본 내용은 Dacon의 동서발전 태양광 발전량 예측 AI 경진대회에 참가한 프로젝트 내용입니다.
주어진 데이터를 통해 태양광 발전량 예측 모델을 만들어 봤습니다.
아래는 Data& Target Data 일부분을 캡처한 그림입니다.

1. Import and Libraries
!pip install tsfreshimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
from tqdm import tqdm
# Ignore the warnings
import warnings
warnings.filterwarnings('ignore') # 경고 뜨지 않게 설정
# System related and data input controls
import os
# Data manipulation and visualization
import pandas as pd
pd.options.display.float_format = '{:,.2f}'.format
pd.options.display.max_rows = 10
pd.options.display.max_columns = 20
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
# Modeling algorithms
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestRegressor
from sklearn.feature_selection import RFECV
from sklearn import linear_model
from statsmodels.stats.outliers_influence import variance_inflation_factor
import statsmodels.api as sm
from scipy import stats
import tsfresh
# Model selection
from sklearn.model_selection import train_test_split
# Evaluation metrics
from sklearn.metrics import mean_squared_log_error, mean_squared_error, r2_score, mean_absolute_error
from google.colab import drive2. 선형보건법 fcst/ obs 비교 시각화
데이콘에서 제시한 선형보건법 함수와 주어진 데이터인 예보데이터(fcst),실측치(obs)를 활용하여 가장 오차가 작은 예보 시간대를 선택합니다.
for number in [11,14,17,20]:
inter_obs = obs_to_interpolate(dangjin_obs,False)
inter_fcst= fcst_to_interpolate(dangjin_fcst,number,False)
inter_obs2=inter_obs[24:].reset_index(drop=True)
pd.concat([inter_obs2[['Temperature']],
inter_fcst[0:25608][['Temperature']]], axis=1).plot(kind='line',figsize=(20,10),
linewidth=3, fontsize=20,
ylim=(-15,40))
print('%s일 경우의 그래프'%number)
plt.title('Temparature plot', fontsize=20)
plt.xlabel('label', fontsize=15)
plt.ylabel('Temparature', fontsize=15)
plt.show()
#잔차
Resid=((inter_obs2[['Temperature']].values.flatten()-inter_fcst[0:25608][['Temperature']].values.flatten())**2).mean()
print('Resid',Resid)*11시 예보 데이터 사용 그래프 => Resid 2.899278434194671
*14시 예보 데이터 사용 그래프=>Resid 2.899264549644704
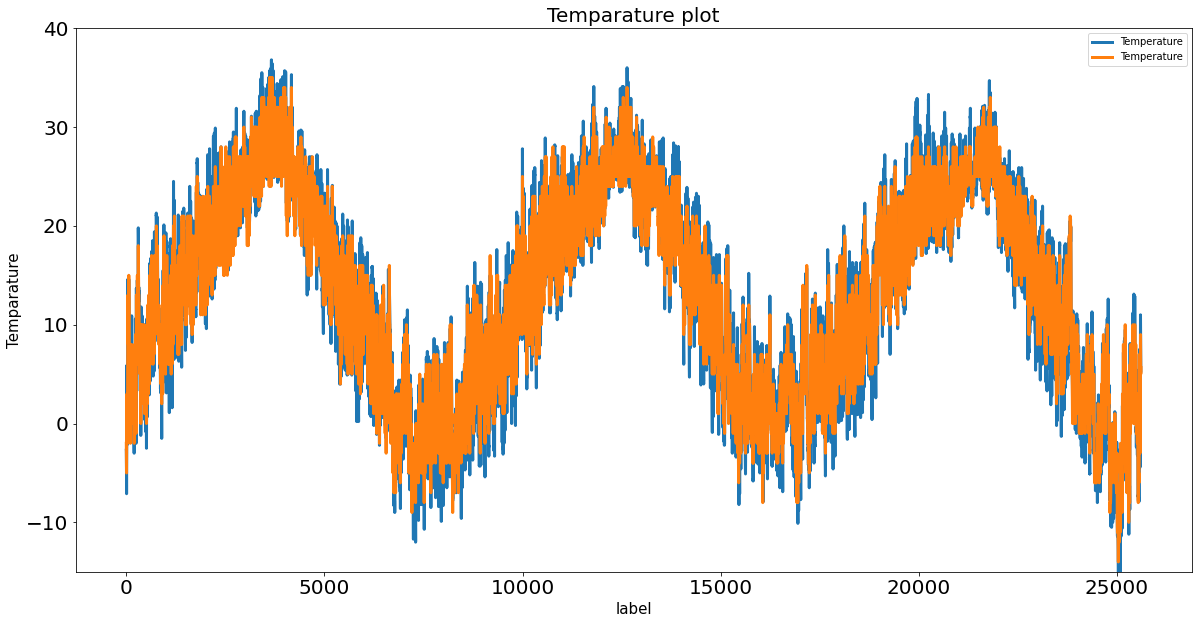
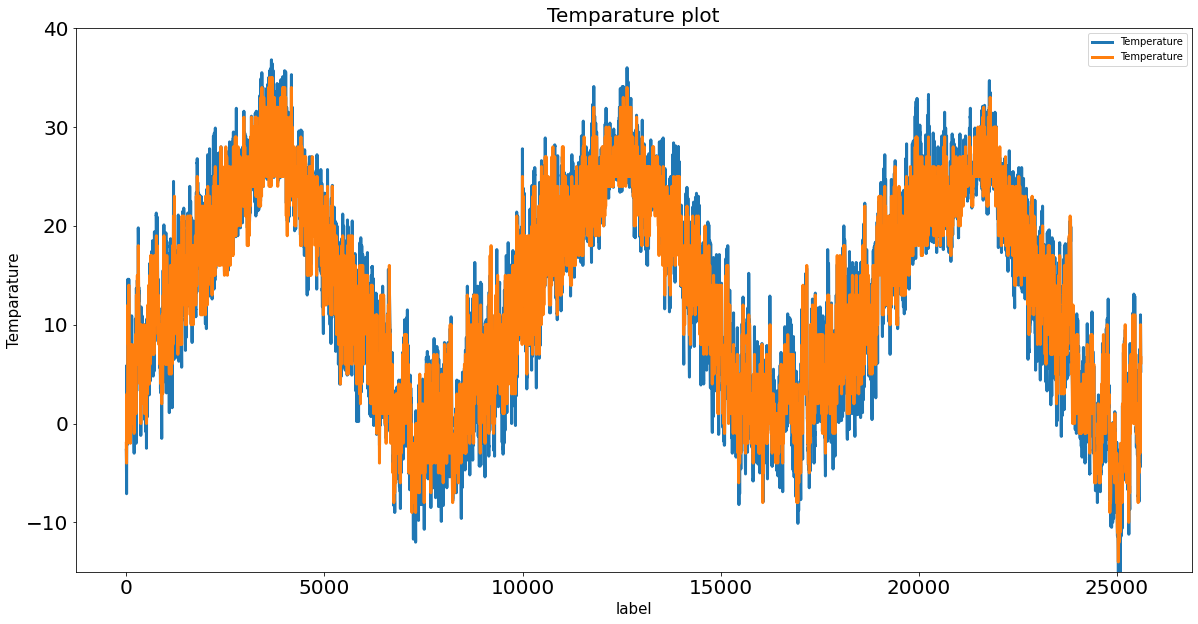
*17시 예보 데이터 사용 그래프=>Resid 2.81235024211184
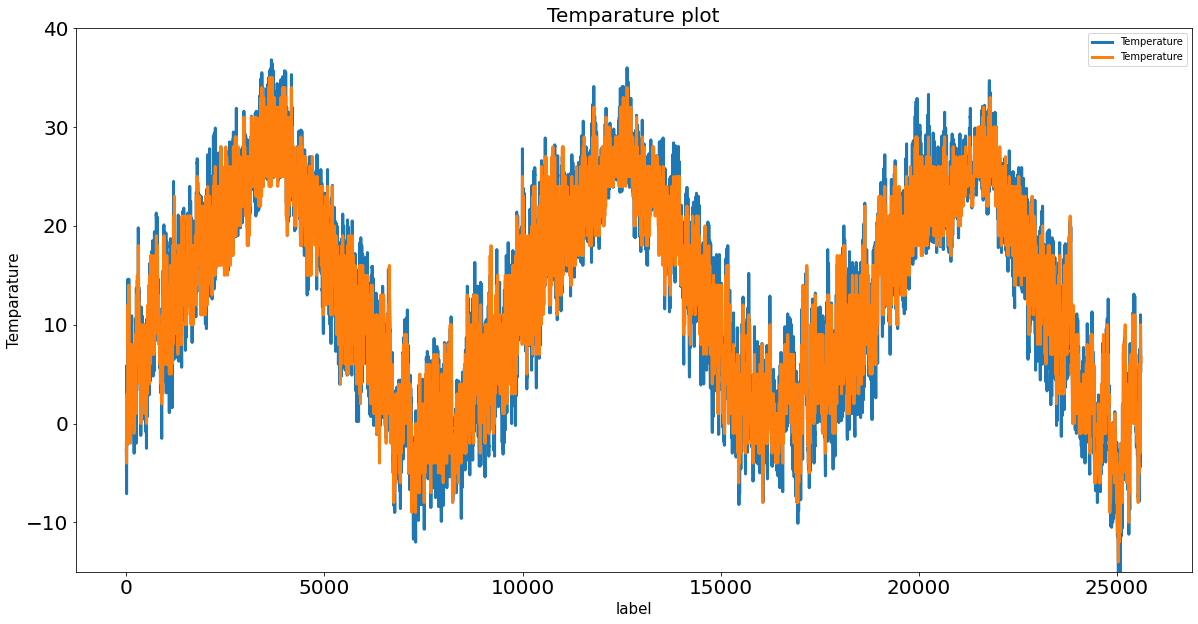
*20시 예보 데이터 사용 그래프=>Resid 2.811606550904232 (20시 예보 데이터가 실측치와 가장 근접)
3. Exploratory Data Analysis
3.1 연도별
for col in concat_df.columns[:4]:
plt.figure(figsize=(15,6))
g = sns.boxplot(x='year', y=col, data=concat_df, showfliers=False)
g.set_title('box plot of %s'%col, size=20)
g.set_xticklabels(g.get_xticklabels(), rotation=90)
plt.show()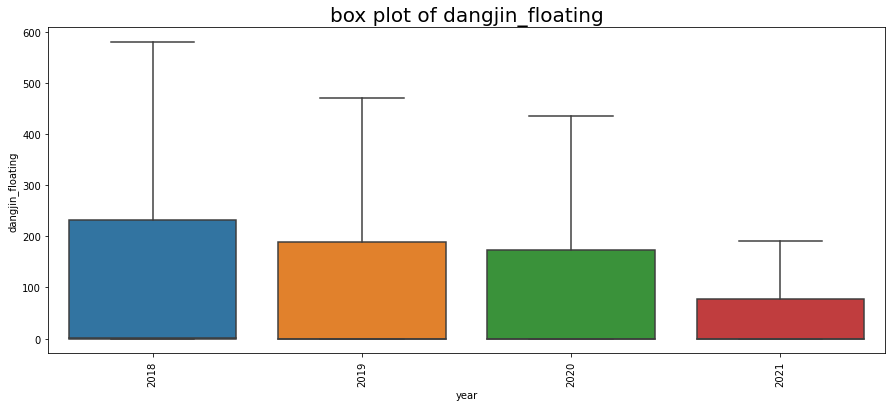
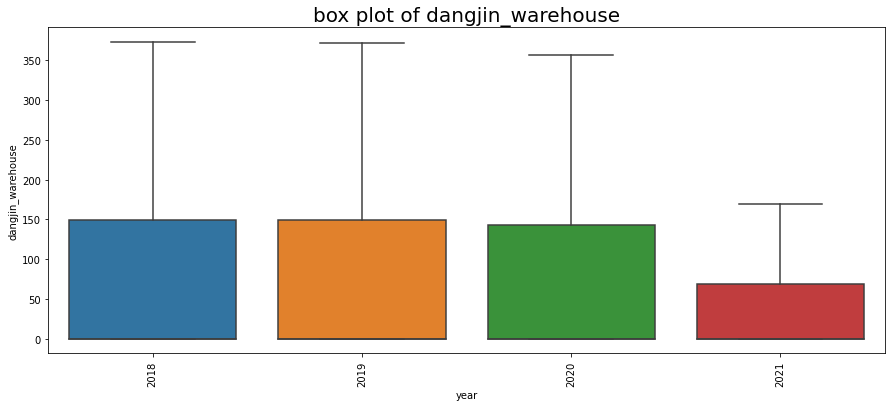
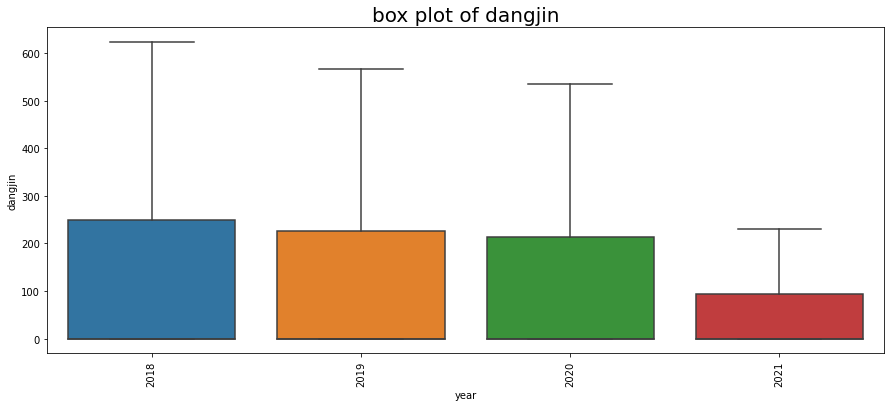
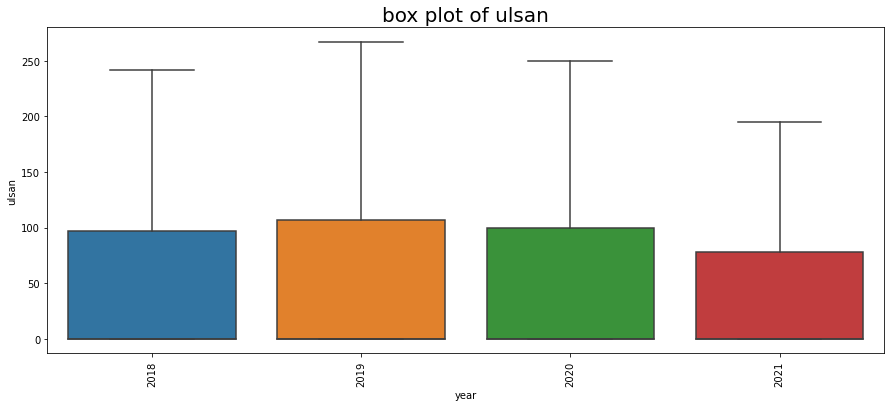
연도별 시각화 결과, dangjin_floating 수치만 감소세를 보입니다. 수치로 확인하기 위해 아래처럼 작업을 진행했습니다.
concat_df.groupby('year').agg({'dangjin_floating':['count','sum','mean']})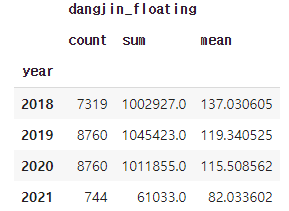
2018년도는 3월부터 기록되어 있으므로 Count 수가 다릅니다. 하지만 태양 에너지 평균은 가장 높습니다.
dangjin_floating 만 감소세를 보이는 원인에 대해서는 파악이 되지 않으나 dangjin_floating 에너지 수급 패턴을 짐작할수 있습니다.
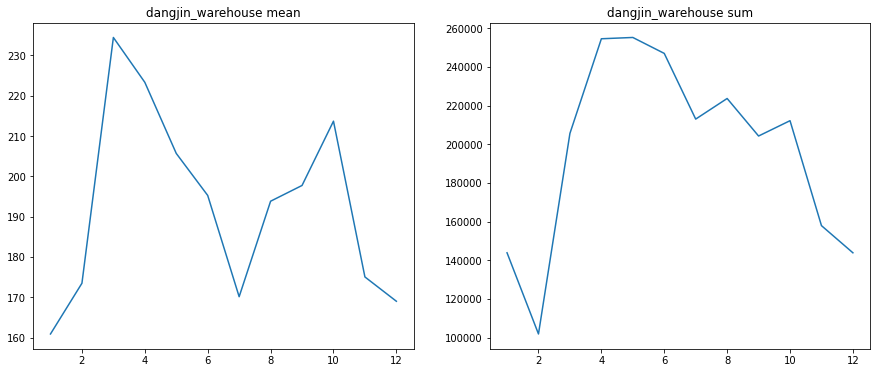
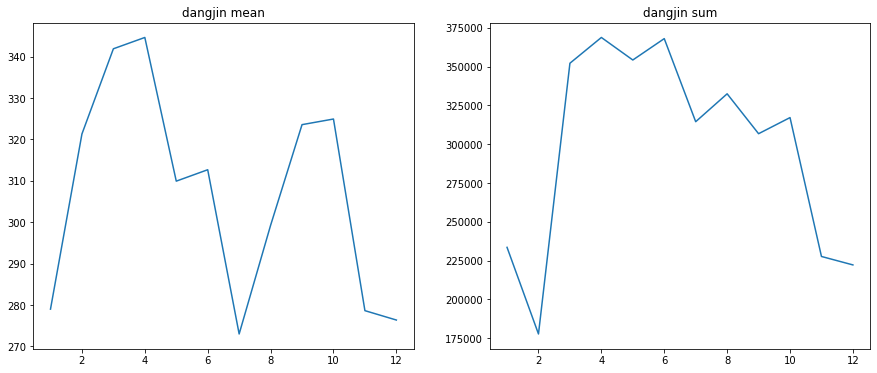
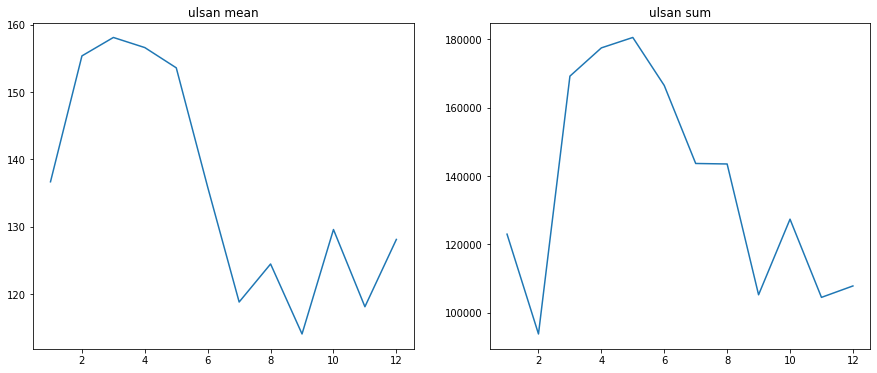
3.2 월별
Y_colname = 'dangjin_floating','dangjin_warehouse','dangjin','ulsan'
for col in Y_colname:
concat_df2 = concat_df[concat_df[col]!=0]
result = concat_df2.groupby('month').agg({col:['sum','mean','count']}).reset_index(drop=False)
# print(result.iloc[:,3])
plt.figure(figsize=(15,6))
plt.subplot(1,2,1)
plt.plot(result.iloc[:,0], result.iloc[:,2])
plt.title('%s mean'%col)
plt.subplot(1,2,2)
plt.plot(result.iloc[:,0], result.iloc[:,1])
plt.title('%s sum'%col)
plt.show()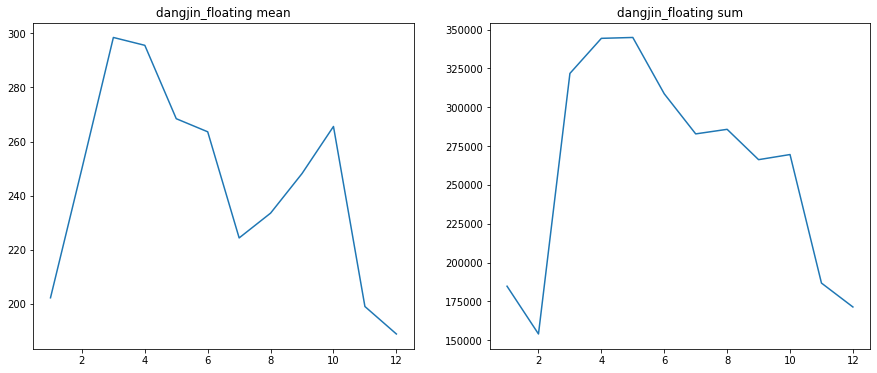
concat_df.boxplot(column ='ulsan', by ='month', grid =True, figsize=(12,5))
concat_df.boxplot(column ='dangjin_floating', by ='month', grid =True, figsize=(12,5))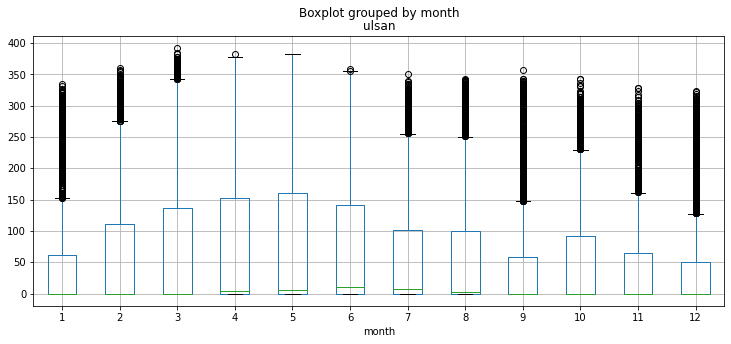
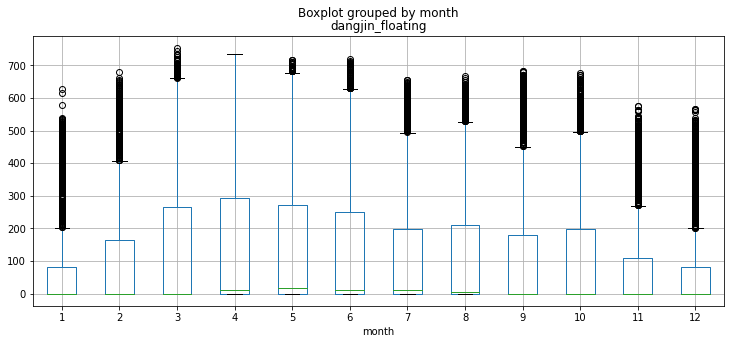
여름에 가장 많은 태양광 에너지를 얻을거라는 예상과 달리 3~4월 기점으로 에너지 수급이 7월까지 급격한 감소 추세를 보입니다. 7월 이후로 반등하는 모습을 보이다가 10월 이후, 겨울이 본격적으로 시작되면서 다시 감소 추세입니다. 가장 수급이 좋은 시기는 초봄인 3월~4월과 더위가 점차 사그라드는 9~10월로 보입니다. 즉 적당한 환경일때 효율적인 수급이 가능 한걸로 추측됩니다.
이후 조사 결과 태양광 에너지 수급에 있어서 중요한 핵심은 태양광의 모듈 온도 이라고 합니다. 이 모듈 온도가 높아지면 효율이 떨어진다고 합니다. 그래서 실제로 이 온도를 낮추기 위한 시설이나 장치를 설치하는 경우가 있다고 합니다.
3.3 시간대별
for col in Y_colname:
concat_df2 = concat_df[concat_df[col]!=0]
result=concat_df2.groupby(['hour']).agg({col:['count','sum','mean']})
result.iloc[:,2].plot(label = '%s_energy'%col, legend=True, figsize=(20,10))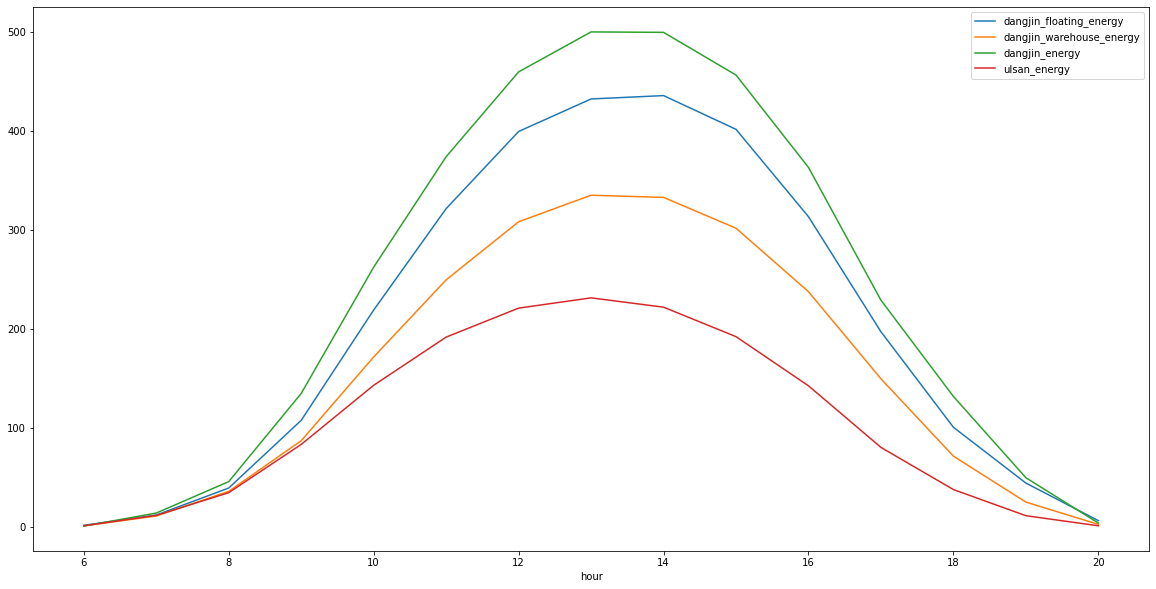
시간대는 약 13시30분에 가장 높은 수급을 보입니다.
정리를 하면, 3~4월의 13시30분에 가장 높은 에너지를 확보 할수 있습니다.
데이터 보기전에는 무조건 온도가 높으면 좋을 줄 알았는데 조금 의외의 결과였습니다.
3.4 날씨별
*Cloud : 하늘상태(1-맑음, 2-구름보통, 3-구름많음, 4-흐림)
concat_df['Cloud'] = concat_df['Cloud'].astype('int') #일기예보의 구름 양 예측에 따른 에너지 양
Y_colname = ['dangjin_floating','dangjin_warehouse','dangjin','ulsan']
cloud = concat_df.groupby(['Cloud'])[Y_colname].sum()
cloud.plot(kind = 'bar')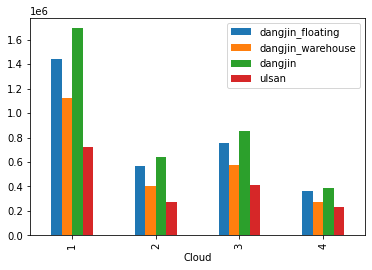
대체로 구름이 없을수록 태양열 에너지 수급이 원활함을 알수 있음 특이한 점은 구름이 많은 상태인 3에서 소폭 상승을 보였다는 점이다. 자세한 파악을 위해서 상관성을 시각화 해보았습니다.
import seaborn as sns
plt.figure(figsize=(16,10))
sns.heatmap(concat_df.corr(), annot=True)
plt.show()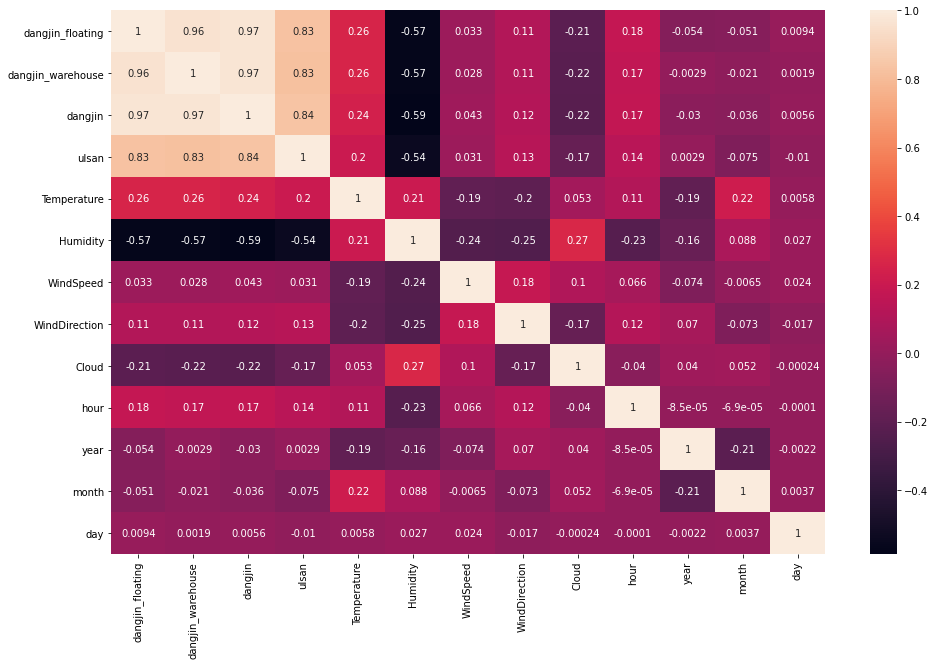
Corr 결과만 봤을때는 음의 상관관계이므로 1->4로 갈수록 수급이 떨어져야 정상입니다. 추측으로는 다중공선성의 영향이 있을 거라 생각됩니다.
3.5 일자별
#Date 설정
concat_df['date'] = concat_df['Forecast_time'].dt.date
concat_df['date'] = pd.to_datetime(concat_df['date'])
#2019/01일 부터 시각화
date_df = concat_df[concat_df['date'] >= '2019-01-01']
date_df =date_df.groupby('date')[Y_colname].sum().reset_index()
plt.figure(figsize=(20,9))
plt.plot('date', 'dangjin_floating', 'g-',label='dangjin_floating',data=date_df)
plt.gcf().autofmt_xdate()
plt.legend(loc='center left', bbox_to_anchor=(1,0.5), fontsize=20)
plt.title('date_df')
plt.show()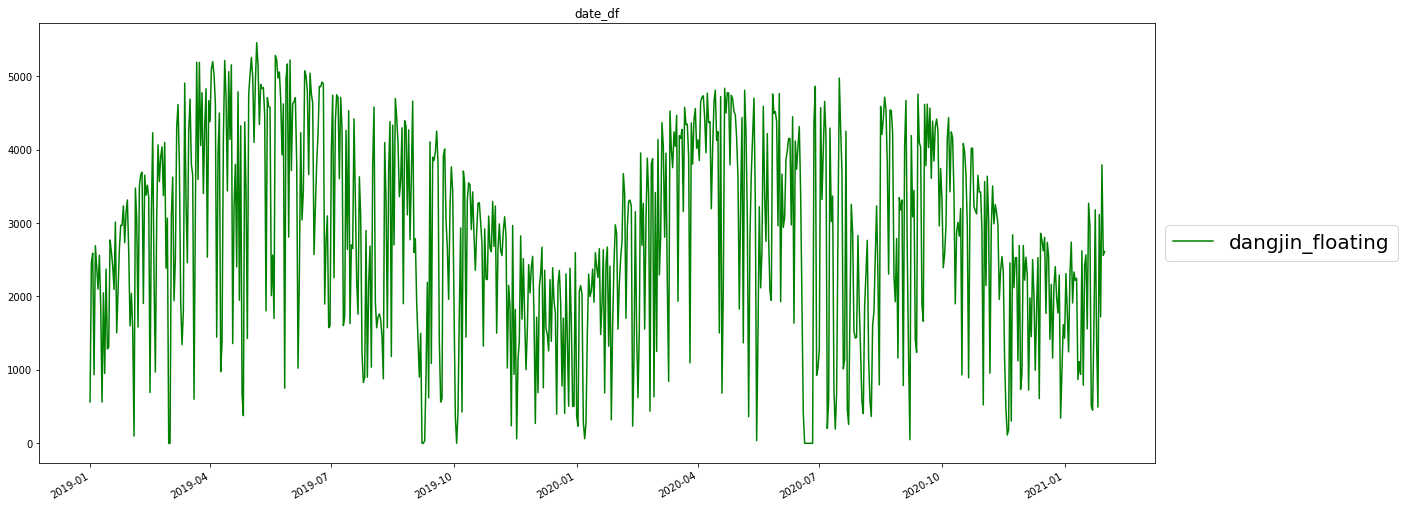
월별 시각화와 일맥상통으로 봄에서 겨울 사이에는 감소를 보이다가 다시 상승하는 패턴을 보입니다.
상승이나 하강의 추세는 아직까진 없어 보이는 대신 계절성 패턴이 명확하게 보입니다.
4. Data Preprocessing & Feature Engineering
# 선형 보건법
def to_date(x):
return pd.DateOffset(hours=x)
def fcst_to_interpolate(dangjin_fcst,date_number,graph=True):
#날짜타입으로 변경
dangjin_fcst['Forecast_time'] = pd.to_datetime(dangjin_fcst['Forecast time'])
#적용할 date_number
fcst = dangjin_fcst[dangjin_fcst['Forecast_time'].dt.hour==date_number]
fcst = fcst[(fcst['forecast']>=24-date_number) & (fcst['forecast']<=47-date_number)]
#forecast 시간 합치기
fcst['Forecast_time'] = fcst['Forecast_time'] + fcst['forecast'].map(to_date)
#사용될 컬럼 추출
fcst = fcst[['Forecast_time', 'Temperature', 'Humidity', 'WindSpeed', 'WindDirection', 'Cloud']]
#선형보건법이 적용된 데이터 프레임 생성
fcst_= pd.DataFrame()
fcst_['Forecast_time'] = pd.date_range(start='2018-03-02 00:00:00', end='2021-03-01 23:00:00', freq='H')
fcst_merge = pd.merge(fcst_, fcst, on='Forecast_time', how='outer')
inter_fcst = fcst_merge.interpolate()
if graph:
plt.figure(figsize=(20,5))
days = 5
plt.plot(inter_fcst.loc[:24*days, 'Forecast_time'], inter_fcst.loc[:24*days, 'Temperature'], '.-')
plt.plot(fcst_merge.loc[:24*days, 'Forecast_time'], fcst_merge.loc[:24*days, 'Temperature'], 'o')
return inter_fcst
def obs_to_interpolate(dangjin_obs,graph=True):
#날짜타입으로 변경
dangjin_obs['Forecast_time'] = pd.to_datetime(dangjin_obs['time'])
#사용될 컬럼 추출
obs = dangjin_obs[['Forecast_time', 'Temperature', 'Humidity', 'WindSpeed', 'WindDirection', 'Cloud']]
#선형보건법이 적용된 데이터 프레임 생성
obs_= pd.DataFrame()
obs_['Forecast_time'] = pd.date_range(start='2018-03-01 00:00:00', end='2021-01-31 23:00:00', freq='H')
obs_merge = pd.merge(obs_, obs, on='Forecast_time', how='outer')
inter_obs = obs_merge.interpolate()
if graph:
plt.figure(figsize=(20,5))
days = 5
plt.plot(inter_obs.loc[:24*days, 'Forecast_time'], inter_obs.loc[:24*days, 'Temperature'], '.-')
plt.plot(obs_merge.loc[:24*days, 'Forecast_time'], obs_merge.loc[:24*days, 'Temperature'], 'o')
return inter_obs
def feature_engineering(concat_df, target):
if 'Forecast_time' in concat_df.columns:
concat_df['Forecast_time']=pd.to_datetime(concat_df['Forecast_time'])
concat_df.index =concat_df['Forecast_time']
concat_df=concat_df.asfreq('H')
#0으로 되어 있는 값을 작년 수치 & 변수 대체
concat_df.loc['2020-06-19 11:00:00':"2020-06-25 23:00:00",'dangjin_floating'] = concat_df.loc['2019-06-19 11:00:00':'2019-06-25 23:00:00','dangjin_floating'].values
concat_df.loc['2020-06-19 11:00:00':"2020-06-25 23:00:00",'Temperature':] = concat_df.loc['2020-06-19 11:00:00':"2020-06-25 23:00:00",'Temperature':].values
#nan값 채우기
concat_df.loc['2020-06-26 01:00:00':"2020-06-27 00:00:00",'dangjin_floating'] = concat_df.loc['2020-06-28 01:00:00':'2020-06-29 00:00:00','dangjin_floating'].values
concat_df.loc['2018-03-17 01:00:00':"2018-03-19 00:00:00",'dangjin_warehouse'] = concat_df.loc['2018-03-15 01:00:00':'2018-03-17 00:00:00','dangjin_warehouse'].values
#날짜 형식 추가
concat_df['hour']=concat_df['Forecast_time'].dt.hour
concat_df['year']=concat_df['Forecast_time'].dt.year
concat_df['month']=concat_df['Forecast_time'].dt.month
concat_df['day']=concat_df['Forecast_time'].dt.day
result =sm.tsa.seasonal_decompose(concat_df[target], model='additive')
Y_seasonal = pd.DataFrame(result.seasonal)
Y_seasonal.fillna(method='bfill', inplace=True)
Y_seasonal.fillna(method='ffill', inplace=True)
Y_seasonal.columns= ['%s_seasonal'%target]
concat_df = pd.concat([concat_df,Y_seasonal], axis=1)
return concat_df
def feature_engineering_lag(concat_fe,x_colname,number,multi_number=1):
for col in x_colname:
for mul_number in range(1,multi_number+1):
shift_number = concat_fe[[col]].shift(number*mul_number)
shift_number.fillna(method='bfill', inplace=True)
shift_number.fillna(method='ffill', inplace=True)
shift_number.columns =['{}_lag{}'.format(col,number*mul_number)]
concat_fe = pd.concat([concat_fe,shift_number], axis=1)
return concat_fe
def feature_engineering_diff(concat_fe, x_colname, diffs):
diff_multi_number =2
for col in x_colname:
for number in range(1,diffs+1):
diff_number = concat_fe[[col]].diff(number)
diff_number.fillna(method='bfill', inplace=True)
diff_number.fillna(method='ffill', inplace=True)
diff_number.columns =['{}_diff{}'.format(col,number)]
concat_fe =pd.concat([concat_fe, diff_number], axis=1)
return concat_fe
def feature_engineering_duplicated(x_train,x_val,target):
target = ['%s_seasonal'%target] # '%s_trend'%target '%s_diff'%target,'%s_lag_1'%target, '%s_lag_2'%target,'Y_%s_week'%target, 'Y_%s_day'%target
for col in target:
x_val.loc['2021-01-01 00:00:00':'2021-01-31 23:00:00',col] = x_train.loc['2020-01-01 00:00:00':'2020-01-31 23:00:00',col].values
return x_val
#Datasplit
def train_dataset(concat_df,criteria, X_colname, target):
if 'time' in concat_df.columns:
del concat_df['time']
if 'Forecast_time' in concat_df.columns:
del concat_df['Forecast_time']
train_df = concat_df.loc[concat_df.index<criteria,:]
val_df = concat_df.loc[concat_df.index>=criteria,:]
x_train = train_df[X_colname]
y_train = train_df[target]
x_val = val_df[X_colname]
y_val = val_df[target]
print('x_train:',x_train.shape, 'y_train:',y_train.shape)
print('x_val',x_val.shape,'y_val',y_val.shape)
return x_train,x_val, y_train,y_val
#Scaling
def Scaling(x_train,x_val,scaler):
from sklearn import preprocessing
scaler = scaler
scaler_fit = scaler.fit(x_train)
x_train_feRS = pd.DataFrame(scaler_fit.transform(x_train), index =x_train.index, columns=x_train.columns)
x_val_feRS = pd.DataFrame(scaler_fit.transform(x_val),index =x_val.index, columns=x_val.columns)
return x_train_feRS,x_val_feRS
#다중공선성
def feature_engineering_VIF(x_train):
vif= pd.DataFrame()
vif['VIF_Factor'] = [variance_inflation_factor(x_train.values,i) for i in range(x_train.shape[1])]
vif['Feature'] = x_train.columns
# x_colname_vif = vif.sort_values(by='VIF_Factor', ascending=True)['Feature'][:num_variables].values
return vif
#evalution
def evaluation(y_train, pred, graph=True):
loss_length = len(y_train.values.flatten()) - len(pred)
if loss_length !=0:
print('길이가 맞지 않습니다.')
if graph == True:
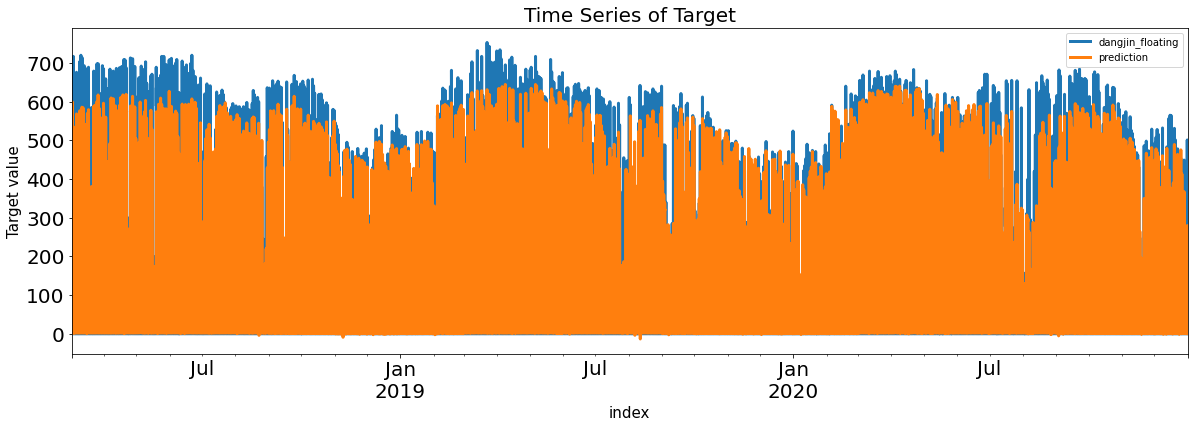
pd.concat([y_train, pd.DataFrame(pred, index=y_train.index, columns=['prediction'])], axis=1).plot(kind='line', figsize=(20,6),
xlim=(y_train.index.min(), y_train.index.max()),
linewidth=3, fontsize=20)
plt.title('Time Series of Target', fontsize=20)
plt.xlabel('index', fontsize=15)
plt.ylabel('Target value', fontsize=15)
Residual = pd.DataFrame(y_train.values.flatten() - pred, index= y_train.index, columns=['Error'])
return Residual
def evaluation_trte(y_train, y_train_pred, y_val, y_val_pred, graph=True ):
Residual_train = evaluation(y_train, y_train_pred,graph=graph)
Residual_val = evaluation(y_val, y_val_pred, graph=graph)
return Residual_train,Residual_val
def nmae_10(y_pred, dataset,capacity=1000):
y_true = dataset.get_label()
absolute_error = abs(y_true - y_pred)
absolute_error /= capacity
target_idx = np.where(y_true>=capacity*0.1)
nmae = 100 * absolute_error[target_idx].mean()
return 'score', nmae, False
def sola_nmae(answer, pred,capacity=1000):
absolute_error = np.abs(answer - pred)
absolute_error /= capacity
target_idx = np.where(answer>=capacity*0.1)
nmae = 100 * absolute_error[target_idx].mean()
return nmae
#feature engineering
concat_fe=feature_engineering(concat_df,"dangjin_floating")
#X's diff 생성
x_colname=['Temperature','WindSpeed','Humidity'] # 'year', 'month', 'day'
concat_fe = feature_engineering_diff(concat_fe,x_colname,6)
#X's lag 생성
# x_colname2=['WindDirection']
# concat_fe = feature_engineering_lag(concat_fe,x_colname2,4)
#datasplit
Y_colname = ['dangjin_floating','dangjin_warehouse','dangjin','ulsan']
X_colname =[col for col in concat_fe.columns if col not in Y_colname+['time','Forecast_time',"year"]]
x_train_feR,x_val_feR, y_train_feR,y_val_feR =train_dataset(concat_fe,'2021-01-01 00:00:00',X_colname,'dangjin_floating')
# #feature_engineering_duplicated
x_val_feR = feature_engineering_duplicated(x_train_feR,x_val_feR,'dangjin_floating')
#설명변수 스케일링
x_train_feRS, x_val_feRS = Scaling(x_train_feR,x_val_feR,preprocessing.StandardScaler())
#다중공선성
vif = feature_engineering_VIF(x_train_feRS)
vif.sort_values(by=['VIF_Factor'], inplace=True)
vif.reset_index(drop=True, inplace=True)
VIF_colname =[]
for idx,x in enumerate(vif['VIF_Factor'].values):
if x <= 15 :
VIF_colname.append(vif['Feature'][idx])
#REV
ols = linear_model.LinearRegression()
refecv = RFECV(estimator=ols, step=1, scoring='neg_mean_squared_error')
refecv.fit(x_train_feRS, y_train_feR)
refecv.transform(x_train_feRS)
refecv_colname =[colname for idx,colname in enumerate(x_train_feRS.columns) if refecv.ranking_[idx]==1]
5. modeling
*target의 정규화를 각 모델에 적용한 결과, 비 정규화가 더 높은 성능을 보였습니다. 정규화 결과는 간결한 진행을 위해서 제외 시켰습니다.
5.1 auto_arima
!pip install pmdarimafrom pmdarima.arima import auto_arima
arima_model = auto_arima(y_train_feR, start_p=2, d=0, start_q=2,
max_p=3, max_d=1, max_q=3,
start_P=1, D=1, start_Q=1,
max_P=7, max_D=3, max_Q=7, m=24, seasonal=True,
error_action='ignore', trace=True,
supress_warnings=True, stepwise=True,
random_state=20) #, n_fits=50
arima_model.fit(y_train_feR)auto_arima로 파리미터를 찾으려고 했으나 computing 문제로 초반부터 중단이 되었습니다. SARIMAX의 acf,pacf 결과로 order 추정을 해보았습니다.
5.2 SARIMAX

위 설정값은 2020년도 값만 적용했을때의 결과값입니다. 이 order 값을 전체 데이터에 적용해 보았지만 computing 문제로 실행되지 않았습니다. 따라서 order 값을 적용했을때의 모습을 보여 드리기 위하여 아래 임의의 order값을 적용했습니다.
#SARIMAX
trend_order = (0,0,0)
seasonal_order = (2,1,2,24)
model = sm.tsa.SARIMAX(y_train_feR, trend='c', order =trend_order, seasonal_order= seasonal_order, exog = x_train_feRS)
result = model.fit()
print('SARIMAX {}*{} and AIC: {}'.format(trend_order,seasonal_order,result.aic))
display(result.summary())
#예측
SARIMAX_train_pred = result.predict(start=0, end=len(y_train_feR)-1, exog = x_train_feRS)
SARIMAX_val_pred = result.forecast(len(y_val_feR), exog = x_val_feRS) #1월달 예측
display('train_CV Score : ', sola_nmae(y_train_feR.to_numpy(), SARIMAX_train_pred.to_numpy()))
display('val_CV Score : ', sola_nmae(y_val_feR.to_numpy(), SARIMAX_val_pred.to_numpy()))
#시각화
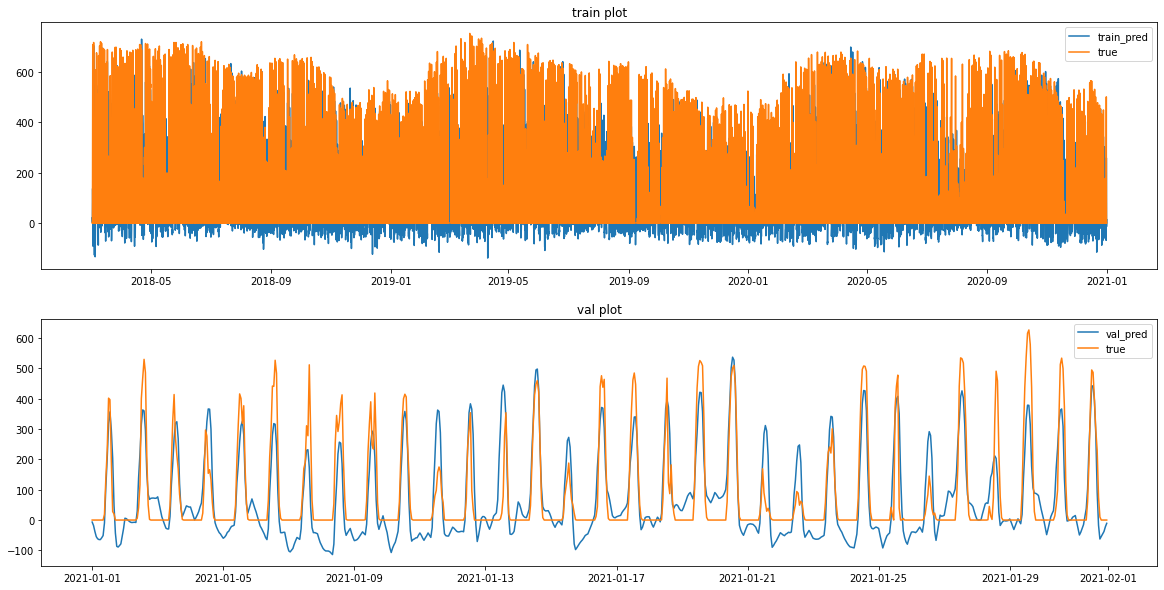
plt.figure(figsize=(20,10))
plt.subplot(2,1,1)
plt.plot(SARIMAX_train_pred, label = 'train_pred')
plt.plot(y_train_feR, label ='true')
plt.legend()
plt.title('train plot')
plt.subplot(2,1,2)
plt.plot(SARIMAX_val_pred, label = 'val_pred')
plt.plot(y_val_feR, label ='true')
plt.legend()
plt.title('val plot')
plt.show()
#잔차진단
result.plot_diagnostics(figsize=(10,8))
plt.tight_layout()
plt.show()
res= result.resid
sm.tsa.graphics.plot_acf(res, lags=100)
sm.tsa.graphics.plot_pacf(res, lags=100)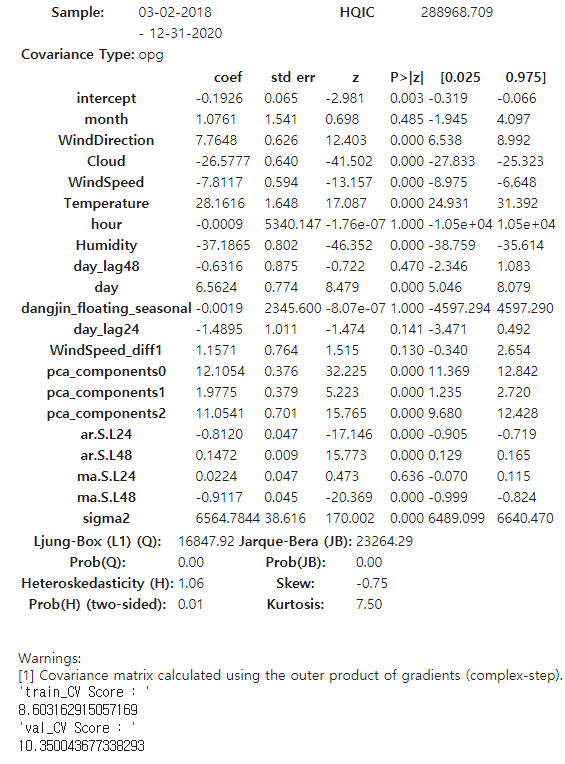
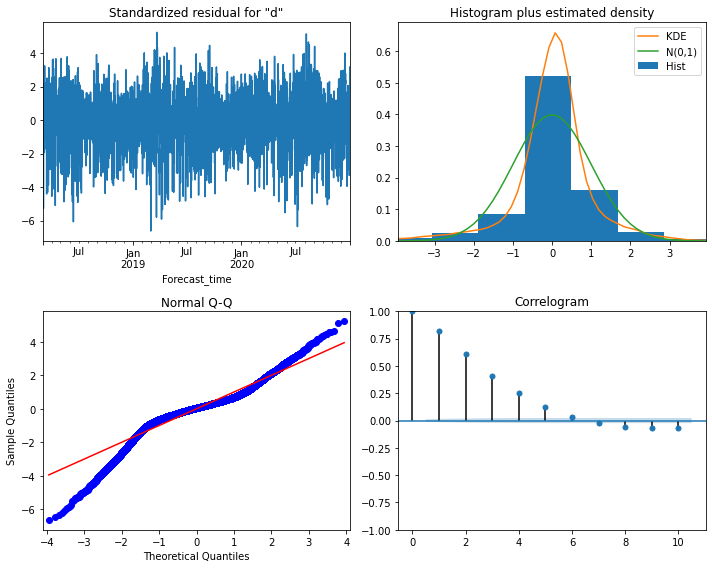
분석결과
자기상관성 존재하며 정규분포는 아니며 등분산은 아니라는 결과를 받았습니다. 정상성을 만들지 못했습니다. 총 62번의 실험을 해보았지만 정상성을 만족하는 order값은 차지 못했습니다. 또한 데이콘에서 제시한 베이스 코드의 점수인 8.3에 못미치는 점수가 나왔으므로 SARIMAX로 모델링 하는건 시간적으로 무리가 있다고 생각했습니다.
5.3 지수평활
CV_Score=[]
numbers=range(1,100)
# log = True
for number in numbers:
fit_exp = ExponentialSmoothing(y_train_feR, seasonal_periods=24*number, trend=None, seasonal='additive').fit(use_boxcox=False)
forecast_exp = fit_exp.forecast(24*31)
#예측점수 계산
CV_Score.append(sola_nmae(y_val_feR.to_numpy(),forecast_exp.to_numpy()))
idxs.append(number)
pd.options.display.max_rows=100
pd.DataFrame(CV_Score, index= numbers, columns=['Score'])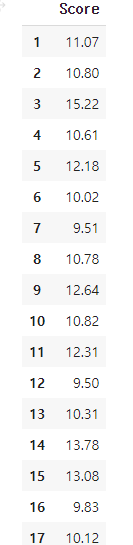
아래는 가장 점수 성능이 좋은 number=12 일 때의 시각화입니다
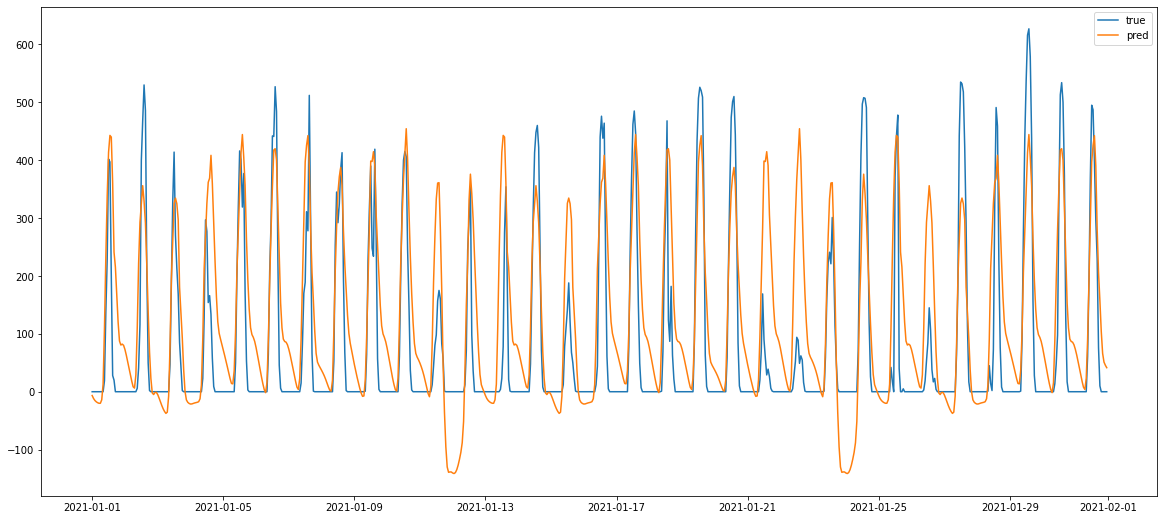
seasonal_periods의 number 값을 100까지 실행한 결과 9.5 점수를 얻은 number=12일때 가장 좋은 성능을 보였습니다.
*extract features
개선된 모델을 위하여 중간에 tsfresh 라이브러리를 사용하여 변수를 늘려보았습니다.
!pip install tsfresh
import tsfresh
# extracted_features=tsfresh.extract_features(concat_x, column_id='time')
#데이터 불러오기
extracted_features = pd.read_csv('/content/drive/MyDrive/extracted_features.csv', sep=',')
#rename
extracted_features.rename(columns = {'Unnamed: 0' : 'Forecast_time'}, inplace = True)
extracted_features.set_index('Forecast_time',inplace=True)
extracted_features_df= extracted_features.copy()
extracted_features_df.dropna(axis=1, inplace=True) #결측값 제거
extracted_features_df.isnull().sum().sum()
#열의 평균이 0 or 1이면 삭제
del_list=[]
columns = extracted_features_df.columns
for columns in columns:
mean_calc = extracted_features_df[columns].mean()
if mean_calc == 0.0 or mean_calc==1.0:
del_list.append(columns)
extracted_features_df.drop(columns=del_list, axis=1,inplace=True
#datasplit
from sklearn.model_selection import train_test_split
target = concat_fe['dangjin_floating']
x_train_feR,x_val_feR, y_train_feR,y_val_feR = train_test_split(extracted_features_df,
target,
test_size=0.1,
shuffle=False,
random_state=1004)
# 다중공선성
vif = feature_engineering_VIF(x_train_feR)
vif.sort_values(by=['VIF_Factor'], inplace=True)
vif.reset_index(drop=True, inplace=True)
VIF_colname =[]
for idx,x in enumerate(vif['VIF_Factor'].values):
if x <= 10:
VIF_colname.append(vif['Feature'][idx])
extracted_features_df[VIF_colname]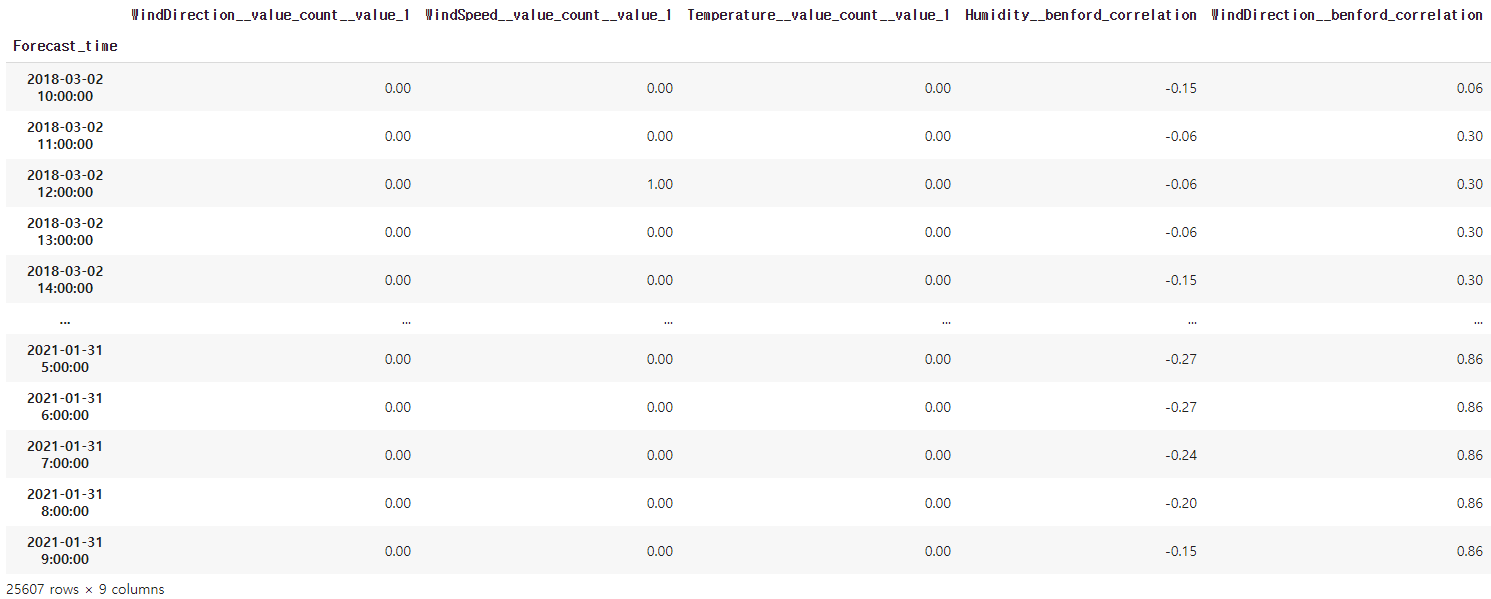
총 생성된 변수 1300여개 중 전처리 후 다중공선성을 제거하기 위해 vif를 실행한 결과 입니다.
VIF_colname
위 9개 변수를 포함하여 가장 성능이 좋았던 random forest에 적용 해본 결과, 성능 다운이 발생했습니다. 변수가 많아져서 과적합이 발생한 걸로 추측해 볼수 있습니다. 아래에 진행 될 모델은 위 9개 변수를 제외하여 진행한 내용입니다.
5.4 randomForeest and LGB
def model(target,fcst,energy_df, n_components=3, y_log =False):
#선형보건법
#20시간으로 한 선형보건법 적용
target_fcst= fcst_to_interpolate(fcst,20,False)
target_fcst = target_fcst.loc[1:25607].reset_index(drop=True)
#energy + dangjin_fcst
energy=energy_df[24:-1].reset_index(drop=True)
concat_df = pd.concat([energy,target_fcst], axis=1)
concat_df.index = concat_df['Forecast_time']
#feature engineering
concat_fe=feature_engineering(concat_df,target)
#X's diff 생성
x_colname=['Temperature','WindSpeed','Humidity'] # 'year', 'month', 'day'
concat_fe = feature_engineering_diff(concat_fe,x_colname,6)
#X's lag 생성
x_colname2=['day']
concat_fe = feature_engineering_lag(concat_fe,x_colname2,24,2)
#datasplit
Y_colname = ['dangjin_floating','dangjin_warehouse','dangjin','ulsan']
X_colname =[col for col in concat_fe.columns if col not in Y_colname+['time','Forecast_time',"year"]]
x_train_feR,x_val_feR, y_train_feR,y_val_feR =train_dataset(concat_fe,'2021-01-01 00:00:00',X_colname,target)
# #feature_engineering_duplicated
x_val_feR = feature_engineering_duplicated(x_train_feR,x_val_feR,target)
#설명변수 스케일링
x_train_feRS, x_val_feRS = Scaling(x_train_feR,x_val_feR,preprocessing.StandardScaler())
# 1. Normal, 2.Robust = 3.Standard 4. Minmax
# target log -> 예측범위를 좁히는데 용이
if y_log:
y_train_feR = np.log1p(y_train_feR).copy()
y_val_feR = np.log1p(y_val_feR).copy()
#다중공선성
vif = feature_engineering_VIF(x_train_feRS)
vif.sort_values(by=['VIF_Factor'], inplace=True)
vif.reset_index(drop=True, inplace=True)
VIF_colname =[]
for idx,x in enumerate(vif['VIF_Factor'].values):
if x <= 15 :
VIF_colname.append(vif['Feature'][idx])
#PCA 변환
pca_col =[col for col in x_train_feRS.columns if col not in VIF_colname]
pca = PCA(n_components=n_components)
#pca fit
pca.fit(x_train_feRS[pca_col])
train_pca_colname = pca.transform(x_train_feRS[pca_col])
val_pca_colname= pca.transform(x_val_feRS[pca_col])
train_pca_df = pd.DataFrame(train_pca_colname, columns=['pca_components%s'%x for x in range(n_components)]) #['pca_components1','pca_components2','pca_components3']
val_pca_df = pd.DataFrame(val_pca_colname, columns=['pca_components%s'%x for x in range(n_components)])
x_train_feRS = x_train_feRS[VIF_colname]
x_val_feRS = x_val_feRS[VIF_colname]
for x in range(n_components):
x_train_feRS.loc[:,'pca_components{}'.format(x)]=train_pca_df.iloc[:,x].values
x_val_feRS.loc[:,'pca_components{}'.format(x)]=val_pca_df.iloc[:,x].values
#REV
ols = linear_model.LinearRegression()
refecv = RFECV(estimator=ols, step=1, scoring='neg_mean_squared_error')
refecv.fit(x_train_feRS, y_train_feR)
refecv.transform(x_train_feRS)
refecv_colname =[colname for idx,colname in enumerate(x_train_feRS.columns) if refecv.ranking_[idx]==1]
# 1.RandomForest
# fit_ranfor = RandomForestRegressor(n_estimators=600, random_state=123,min_samples_leaf=6, min_samples_split=14).fit(x_train_feRS, y_train_feR)
fit_ranfor = RandomForestRegressor(n_estimators=600, random_state=123).fit(x_train_feRS, y_train_feR)
random_train_pred = fit_ranfor.predict(x_train_feRS)
random_val_pred = fit_ranfor.predict(x_val_feRS)
# 2.LGB
import lightgbm as lgb
params = {
'learning_rate': 0.01,
'objective': 'regression',
'metric':'mae',
'seed':42,
}
train_datasets = lgb.Dataset(x_train_feRS.to_numpy(), y_train_feR.to_numpy())
val_dataset = lgb.Dataset(x_val_feRS.to_numpy(), y_val_feR.to_numpy())
fit_lgb = lgb.train(params, train_datasets, 10000, val_dataset, feval=nmae_10, verbose_eval=500, early_stopping_rounds=200)
#lgb 예측
lgb_train_pred = fit_lgb.predict(x_train_feRS)
lgb_val_pred = fit_lgb.predict(x_val_feRS)
#y_log 값 환원
if y_log:
y_train_feR = np.expm1(y_train_feR).copy()
y_val_feR = np.expm1(y_val_feR).copy()
random_train_pred = np.expm1(random_train_pred).copy()
random_val_pred = np.expm1(random_val_pred).copy()
lgb_train_pred = np.expm1(lgb_train_pred).copy()
lgb_val_pred = np.expm1(lgb_val_pred).copy()
# 잔차 진단
rf_Residual_train,rf_Residual_val = evaluation_trte(y_train_feR,random_train_pred, y_val_feR, random_val_pred, graph=True)
display('rf_CV Score : ', sola_nmae(y_val_feR.to_numpy(), random_val_pred))
rf_score = sola_nmae(y_val_feR.to_numpy(), random_val_pred)
lgb_Residual_train,lgb_Residual_val = evaluation_trte(y_train_feR,lgb_train_pred, y_val_feR, lgb_val_pred, graph=True)
display('lgb_CV Score : ', sola_nmae(y_val_feR.to_numpy(), lgb_val_pred))
lgb_score = sola_nmae(y_val_feR.to_numpy(), lgb_val_pred)
return rf_score,lgb_score,rf_Residual_train,lgb_Residual_train,fit_ranfor,fit_lgb,concat_fe,x_train_feRS,y_train_feR,x_val_feRS,y_val_feR,VIF_colname
rf_score,lgb_score,rf_Residual_train,lgb_Residual_train,fit_ranfor,fit_lgb,concat_fe,x_train_feRS,y_train_feR,x_val_feRS,y_val_feR,VIF_colname = model('dangjin_floating',dangjin_fcst,energy)
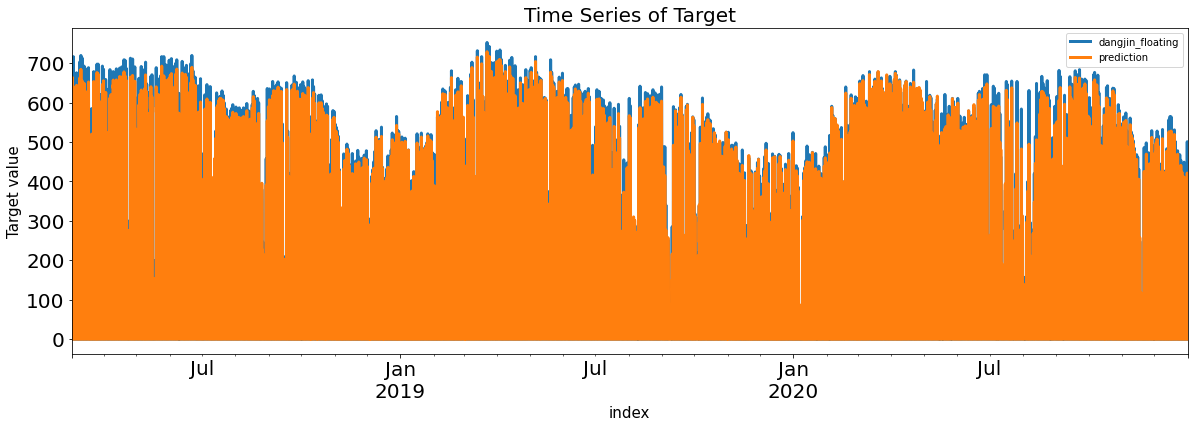
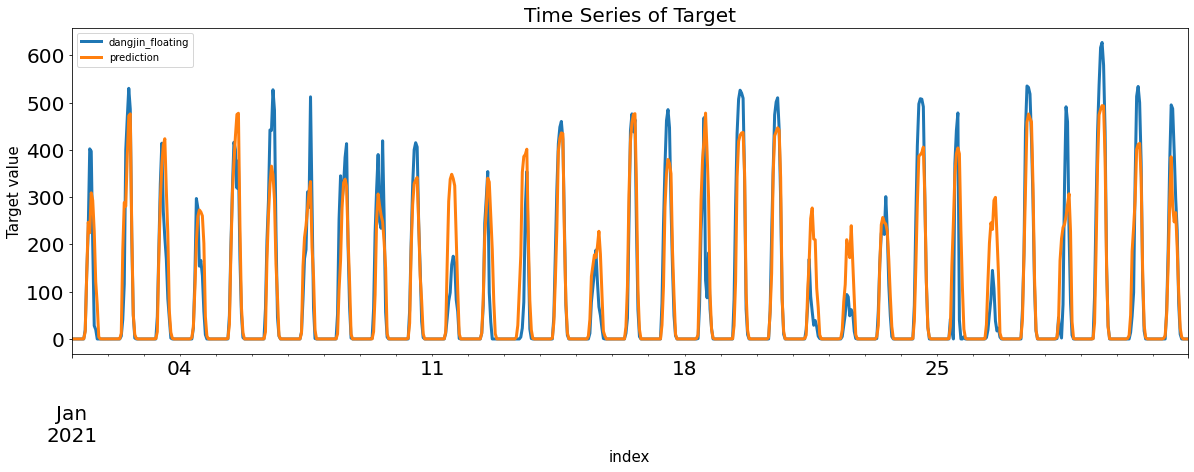
# 랜덤 포레스트 중요도
importances_values = fit_ranfor.feature_importances_
importances_df = pd.Series(importances_values, index = x_train_feRS.columns).sort_values(ascending=False)
plt.figure(figsize=(20,9))
plt.title('Importancsvariables')
sns.barplot(x = importances_df, y = importances_df.index)
plt.show()
sns.distplot(rf_Residual_train['Error'].iloc[1:], norm_hist='True', fit=stats.norm)
figure, axes = plt.subplots(1, 4, figsize=(30,5))
pd.plotting.lag_plot(rf_Residual_train['Error'].iloc[1:], lag=1, ax=axes[0])
pd.plotting.lag_plot(rf_Residual_train['Error'].iloc[1:], lag=5, ax=axes[1])
pd.plotting.lag_plot(rf_Residual_train['Error'].iloc[1:], lag=10, ax=axes[2])
pd.plotting.lag_plot(rf_Residual_train['Error'].iloc[1:], lag=50, ax=axes[3])
figure, axes = plt.subplots(2,1,figsize=(12,5))
figure = sm.graphics.tsa.plot_acf(rf_Residual_train['Error'].iloc[1:], lags=100, use_vlines=True, ax=axes[0])
figure = sm.graphics.tsa.plot_pacf(rf_Residual_train['Error'].iloc[1:], lags=100, use_vlines=True, ax=axes[1])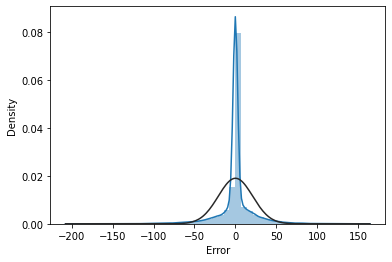

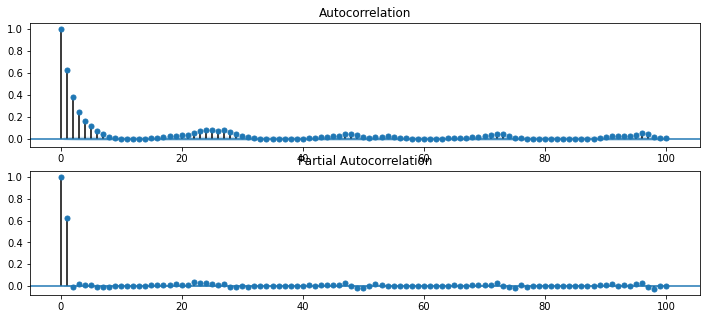
rf(랜덤포레스트)의 정규분포/자기상관성 상태를 시각화 해보았습니다.
ACF를 보면 초반에 튀는 값이 약 7개가 존재하며 중간에 24주기를 중심으로 살짝 튀는 값들도 존재합니다.
제가 이번 프로젝트를 하면서 보았던 자기상관성 그래프들 중 가장 안정적인 모습을 보입니다.
하지만 튀는 값은 존재하므로 제가 잡지 못한 패턴은 존재합니다.
6. Test
def test_dataset(target,concat_fe,start='2021-02-01 00:00:00', end = '2021-02-28 23:00:00', duplicated_start='2020-02-01 00:00:00', duplicated_end = '2020-02-28 23:00:00',n_components=3):
from sklearn import preprocessing
from sklearn.decomposition import PCA
# data loading
dangjin_fcst = pd.read_csv('/content/drive/MyDrive/dangjin_fcst_data.csv', sep=',')
ulsan_fcst = pd.read_csv('/content/drive/MyDrive/ulsan_fcst_data.csv', sep=',')
#당진
##선형보건법
dangjin_fcst= fcst_to_interpolate(dangjin_fcst,20,False)
dangjin_start_index =dangjin_fcst[dangjin_fcst['Forecast_time']==start].index[0]
dangjin_end_index =dangjin_fcst[dangjin_fcst['Forecast_time']==end].index[0]
dangjin_fcst_test = dangjin_fcst.iloc[dangjin_start_index:dangjin_end_index+1,:]
#울산
##선형보건법
ulsan_fcst= fcst_to_interpolate(ulsan_fcst,20,False)
ulsan_start_index =ulsan_fcst[ulsan_fcst['Forecast_time']==start].index[0]
ulsan_end_index =dangjin_fcst[ulsan_fcst['Forecast_time']==end].index[0]
ulsan_fcst_test = dangjin_fcst.iloc[ulsan_start_index:ulsan_end_index,:]
##feature_engineering
def test_feature_engineering(fcst_test,target):
if 'Forecast_time' in fcst_test.columns:
fcst_test['Forecast_time']=pd.to_datetime(fcst_test['Forecast_time'])
fcst_test.set_index(fcst_test['Forecast_time'], drop=True, inplace=True)
fcst_test=fcst_test.asfreq('H')
#날짜 형식 추가
fcst_test['hour']=fcst_test['Forecast_time'].dt.hour
fcst_test['month']=fcst_test['Forecast_time'].dt.month
fcst_test['day']=fcst_test['Forecast_time'].dt.day
del fcst_test['Forecast_time']
##X's diff 생성
x_colname=['Temperature','WindSpeed','Humidity'] # 'year', 'month', 'day'
test_fe = feature_engineering_diff(fcst_test,x_colname,6)
#X's lag 생성
x_colname2=['day']
test_fe = feature_engineering_lag(test_fe,x_colname2,24,2)
#seasonal_duplicated
target2 = ['%s_seasonal'%target]
test_fe.loc[:,target2] = concat_fe.loc[duplicated_start:duplicated_end,target2].values
#스케일링
scaler = preprocessing.StandardScaler()
test_feRS = pd.DataFrame(scaler.fit_transform(test_fe), index = test_fe.index, columns=test_fe.columns)
#PCA 변환
pca_col =[col for col in test_feRS.columns if col not in VIF_colname]
pca = PCA(n_components=n_components)
#pca fit
pca.fit(test_feRS[pca_col])
test_pca_colname = pca.transform(test_feRS[pca_col])
test_pca_df = pd.DataFrame(test_pca_colname, columns=['pca_components%s'%x for x in range(n_components)])
test_feRS = test_feRS[VIF_colname]
for x in range(n_components):
test_feRS.loc[:,'pca_components{}'.format(x)]=test_pca_df.iloc[:,x].values
return test_feRS
#전처리 작업
if target =='ulsan':
test_feRS = test_feature_engineering(ulsan_fcst_test,target)
else:
test_feRS = test_feature_engineering(dangjin_fcst_test,target)
return test_feRS
test_feRS = test_dataset('dangjin_floating',concat_fe)
test_feRS.head()
# 2월 test 예측
rf_pred = fit_ranfor.predict(test_feRS)
pd.DataFrame(rf_pred,index = test_feRS.index, columns =['pred']).plot()
* dangjin_floating

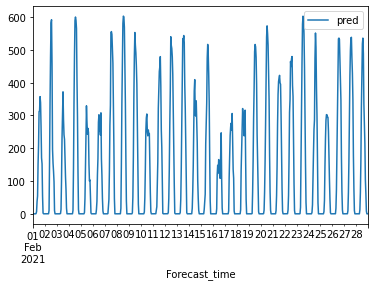
* dangjin_warehouse

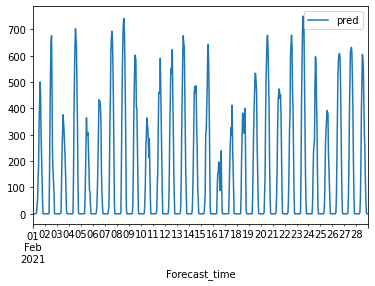
* dangjin_warehouse

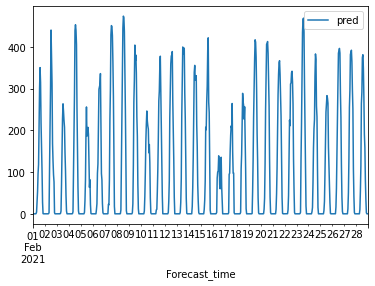
* ulsan

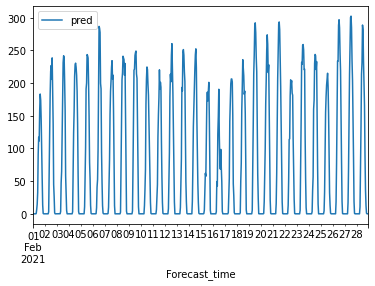
울산 1월 예측 점수는 다른 target과는 달리 큰 폭으로 오차가 줄어들었습니다. lgb가 randomforest보다 더 좋은 성능을 보이고 있습니다. 하지만 일관성을 위해서 randomforest로 2월달을 예측하였습니다.
*프로젝트를 끝내며
데이콘 첫 참가라서 꽤나 어리둥절 했던 것같습니다 프로젝트를 거의 다 만들고
본격적인 평가를 할려고 보니까 6월10일부터 누적 평가라고 하더라구요 이를 확인했을때는 이미
6월 말쯤이라서.. 뒤늦게 제출해도 지나간 날에는 0점으로 매긴다고 합니다. 그래서 프라이빗 평가 대신 대회 끝난 후 퍼블릭 평가를 해볼 생각입니다.
상관성을 보면 추세부분에도 미세하게 연관성이 있어 보입니다. 시계열 모델로 하면 ARMA로 추세부분을 어떻게 해볼순있겠지만 가장 좋은 성능을 보인 랜덤에서는 추세를 어떻게 해야 할까 고민을 좀 해봤습니다.
그래서 생각해 본게 시계열 분해에서 나온 추세를 그냥 넣지 말고 차분이나 lag 등 전처리를 하면 조금이라도 잡을수 있지 않을까 생각해 보면서 마무리를 지어 봅니다.
이 대회 첫참가 하고 데이터를 딱 받아 봤을때 뭘 먼저 해야하는지 감도 잡히지 않아서 일주일동안 답답해 했던 날들이 생각납니다. 이번 대회 덕분에 자신감도 생기고 뿌듯했던 경험이었습니다
'projects' 카테고리의 다른 글
| 따릉이 자전거 이용 예측_dacon (0) | 2021.09.30 |
|---|---|
| Face Mask Detection (0) | 2021.08.25 |
| 뉴욕 택시수요예측 (0) | 2021.02.16 |
| 국민청원글 토픽모델링 (0) | 2021.01.18 |
| CNN_BTS 멤버 image classification (0) | 2021.01.10 |


