오늘은 미분부터 jacobian매트릭스까지 간략하게 정리하여 포스팅하겠습니다~
여담이지만 전 문과생 출신이라서 작년 자코비안 매트릭스에 대해 공부할때 정말 멘탈이 싹 나갔던 기억이 있습니다
구글링해도 개념이 잘 잡히지 않아서 일단 미루고 있었는데 과연
제가 완전하게 이해를 하게 되었을지 끝가지 읽어 주십사 합니다 ㅎㅎ
*딥러닝에서의 미분이란 뭘까?
흔히 어떤 x가 변화했을때 y의 변화량 이라고 배워왔는데요
그래도 뭔가 아 그렇구나 하지 와닿지는 않았더라구요 이 수업에서는 딥러닝의 미분을 아래처럼 소개 하였습니다.

y = 2x^2를 미분하면 y=4x가 됩니다
하늘색은 x=2를 대입할때 계수가 +8이 나왔고 x=-4를 대입하면 -16이 나왔습니다.
이 둘의 미분계수를 자세히 보겠습니다. 만일 x=2가 아니라 3,4,5 증가하면 y값이 커지게 됩니다.
x=-4대신 -5-,6,-7 를 넣게 되면 마찬가지로 y값이 커지게 됩니다(그래프에 대입을 하면 간단하게 알수 있습니다)
결국 이 미분계수가 말하는 것은 "Y가 커지는 방향을 가르키고 있습니다"
x 가 음수로 갈수록, 그리고 양수로 갈수록 y값은 어찌됐건 증가 할 수밖에 없습니다.
우리의 포인트는 증가하는 방향을 알고자 하는게 아닙니다. 바로 감소하는 방향입니다. 왜냐면
딥러닝은 가장 최저점으로 최적화 시켜야 하기 때문이죠. (loss를 줄여야 하니까)
그러면 간단하게 생각해 볼수 있는 것은 f(2)라는 함수에 마이너스를 붙이면 해결이 됩니다~
f(-4)를 -f(-4)로 넣어주면 반대방향으로 바뀌게 됩니다.
위와 같은 함수가 있을때 편미분을 하면 아래처럼 계산이 됩니다.
이때 x=5, y=-5를 대입하면 (10,-10)이라는 gradient가 나옵니다.
이 (10,-10)이라는 것은 무슨 의미 일까요? 그리고 (5,-5)는 어떻게 해석하면 될까요?
(5,-5)는 단지 점!!입니다. 좌표처럼 점을 나타내는 것에 불과하고 (10,-10)은 아래 그래프를 보면서 설명하겠습니다.
x=10이고 y=-10 이니까 이 두 값이 만나는 지점이 빨간 화살표가 가르키고 있는 곳입니다.
보시다시피 원이 안에서 밖으로 퍼저나가면서 값이 커짐을 알수 있습니다.
아까 말씀드린 것처럼 미분계수의 값은 Y가 커지는 방향을 나타냅니다.
여기서 우리의 목적은 가장 최저점인 정 가운데 부분으로 가야하기 때문에 음수를 붙여주게 됩니다.
위 같은 경우에는 함수가 스칼라(값이 하나)일 경우에 해당됩니다.
함수가 여러개가 있을수도 있고 independent variable이 여러개 일수도 있습니다. 예를들어
함수가 하나이고, ndependent variable(변수)가 2개 경우입니다.
여러개가 모이면 벡터가 됩니다. 선형수학에서의 꽃은 여러개 값을 한번에 계산 한다는 점이라서
이 벡터와 그리고 벡터가 모인 매트릭스 같은 연산에 대해서 잘 이해 해야 합니다
본론으로 돌아와서
X라는 변수 벡터를 앞으로 θ로 표기하겠습니다. 변수들이 모여서 만든 벡터와, 함수들이 모여서 만들어진 벡터는
아래 이미지처럼 표현이 가능합니다.
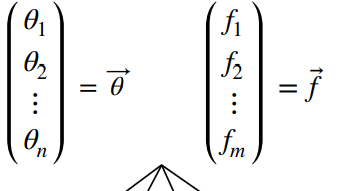
그러면 만들수 있는 모든 경의 수를 생각해 봅시다.
그냥 스칼라값을 가진 함수와 변수가 있을테고, 위 이미지처럼 벡터인 함수와 변수가 있으므로 총 네가지의 경의 수가 발생됩니다.

정사각형 박스는 스칼라를, 길쭉한 직사각형은 벡터를 나타냅니다.
왜 이렇게 표현이 되는지는 아래 이미지로 다시 확인해 봅시다
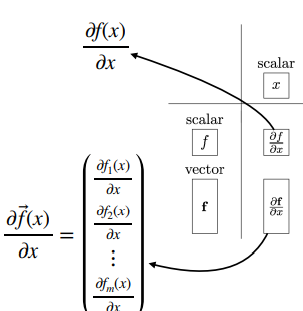
스칼라/스칼라 인 경우는 맨 위에 해봤으니 바로 아래값에 대해 말씀드리겠습니다.
하나의 스칼라 x로 여러개의 함수를 상대해야 하므로 이미지처럼 표현이 가능하겠습니다.
(이때 함수의 갯수는 m개)
계속해서 오른쪽 부분을 보겠습니다.

맨 위를 보면 X에 화살표가 그러져 있는 걸보니 벡터고, 함수는 스칼라 값입니다.
하나의 함수를 가지고 n개의 변수로 각각 미분을 취하는 형식입니다.
그리고 대망의 매트릭스/매트릭스 경우인 맨 아래 입니다.
어려울거 없이 함수가 m가 있고, 변수가 n가 있을때 위 처럼 표현 하다는 것입니다.

각 row에 빨간색으로 칠해져 있는데 이 각각을 gradient라고 합니다.
즉, 가장 큰 값을 가리키는 방향을 나타내는 벡터인 것이죠. 추가로 이 값에 그냥 마이너스를 붙이면
가장 최저점으로 이동 시 방향을 알려줍니다.
정리를 한자면 각 row의 gradient는 함수의 가장 큰 값 바양을 나타내므로 이 m*n 매트릭스에 -1를 곱하게 되면
감소하는 방향의 매트릭스가 됩니다.
*딥러닝에서 사용되는 Element-wise Binary operation
그런데 이 자코비안 매트릭스는 특정한 상황에서 특이한 모습을 보입니다.
바로 각 함수가 특정한 변수에만 영향을 받을 경우입니다.

f1 함수는 θ1에 대해서만 영향이 있고, f2도 θ2에서만 있습니다. 좀더 이해하기 쉽게 다른 예제를 가져오면

알파라는 variable 벡터와 함수 벡터가 있습니다. 식을 보면 함수 하나당 한개 변수로 구성되어 있습니다.
이를 미분한다는 얘기 입니다. 딱 봐도 미분을 하게 되면 뭔가 특이한 모양이 나올거라 예상이 됩니다


위 식 처럼 계산이 이루어 집니다. 식은 복잡해 보여도 한줄 씩 뜯어보면 간단합니다. 이 매트릭스를 미분하게 되면


대각행렬(diagonal matrix)이 나오게 됩니다. 이 대각행렬의 값은 고정은 아니지만 비 대각 성분은 모두 0으로 고정되어 버립니다. 이처럼 한 함수에 한가지 변수만 영향을 주게 되면 위처럼 계산이 됩니다.
또 다른 예를 가져오면



대각성분은 다르게 나오지만 비 대각 성분은 똑같이 0으로 계산되었습니다. 이 연산이 딥러닝에서도 사용이됩니다.
만일 이 두개를 더해서 자코비안 매트릭스를 구하면 어떻게 표현이 될까요?

바로 위 식대로 연산을 해보겠다는 의미입니다. 모든 식을 나열하기엔 너무 많아서 글로 표현을 하겠습니다.
벡터끼리 더해지므로
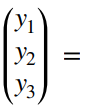


이렇게 표현이 가능합니다. 이 값을 각각 알파와 베타로 편미분을 하면 되는데,
당연하게도 알파로 편미분을 하게되면 알파만 있는 f함수에만 적용되고 베타가 있는 g함수는 0으로 처리가 될것입니다
반대로 베타가 포함된 g함수는 적용이 되고 f함수는 0으로 떨어지게 됩니다.
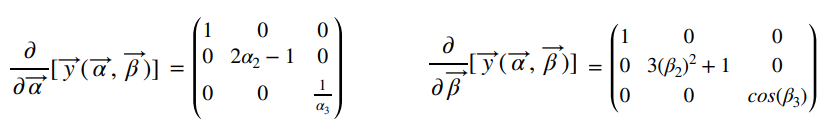
이 개념을 가지고 아래 이미지를 살명하겠습니다.

Z1_1, Z1_2는 각각 n개의 independent variable로 구성되어 있습니다. Z2는 이 두 벡터를 합한 벡터입니다.
그러면 Z2를 각각 Z1_1, Z1_2로 편미분 하게 되면



Z1_2도 같은 모습으로 표현 됩니다. 대각 성분이 1로 통일되였는데 1 값이 달라지면 언제든지 바뀔수 있습니다.
여기까지가 오늘 수업에서 배운 내용을 정리한 내용입니다.
작년의 벡터로 미분하고 매트릭스가 나온다~ 라는 수업내용을 따라가지 못해서 답답했었는데
이번 강의를 통해서 한번에 깨끗하게 해결되었습니다. 이거 때문에 작년에 서점가서 이공계 수학책을 본적이 있는데
제가 원하는 결과는 얻지 못했어요 워낙 광범위하더라구요
그래서 이 강의 듣기 전까지는 미분하면 복잡하다 라는 인식이 있었는데
해결이 된것같아서 뿌듯하고 재미있었습니다
'Data Diary' 카테고리의 다른 글
| 2021-04-26(딥러닝 수학3_Vector Chain Rule) (0) | 2021.04.26 |
|---|---|
| 2021-04-23(태양열 에너지 예측) (0) | 2021.04.23 |
| 2021-04-20(딥러닝 수학1) (0) | 2021.04.20 |
| 2021-04-16(시계열데이터 심화20_종강2) (0) | 2021.04.16 |
| 2021-04-15(시계열데이터 심화19_종강1) (0) | 2021.04.15 |
