실습내용은 아래 링크에서 확인할 수 있습니다.
2021.10.05 - [실습 note] - CNN_Fundamental 실습 모음
CNN_Fundamental 실습 모음
해당 실습은 iflearn "CNN_Fundamental" 강의에서 사용되었습니다. 실습 진행 순서대로 list-up 했습니다 1. Gradient Descent_01 Gradient_Desecent 내용은 딥러닝 수학 강의에서 배웠으므로 따로 이론을 정리하..
ghdrldud329.tistory.com

CNN은 이미지를의 일 부분을 자동으로 뽑아서 featrue로 사용한다. 반면 머신러닝은 일일히 feature를 뽑기 때문에 효율이 떨어진다. 또한 가변적으로 feature들이 변하기 때문에 성능에도 큰 영향을 주었다.

딥러닝은 Universal 한 Feature를 유연성 있게 뽑아준다. 한개의 뉴런 당 하나의 이미지 part를 맡게 된다. 예를들어 고양이 사진에 뉴런 100개라면, 고양이 사진을 100개 부분으로 개별적으로 본다는 것이다. 다시 돌아와서 convolutional laters에서 feature 특징들이 모이게 되면 이를 "feature map"이라 부른다. 이 feature map을 Dense layer에 넣게 된다. 해당 Dense layer를 Fully connected layer 혹은 Classifier layer 라고 부른다. 해당 layer는 실제와 예측을 비교해가면서 가중치를 updata해 가는데, 이때 가중치의 updata는 Feature Extractor 가중치까지 영향을 준다. 학습하기 전 FE에서는 이미지의 특징을 정답없이? 방향성 없이 FE를 진행한다. 그러다가 특정 target에 대한 Loss가 발생하게 되고, 가중치들이 Updata가 되면서, FE가 특정 target에 대한 특징을 뽑게 된다. 다시말해서 target이 고양이 이고, input 이미지가 고양이가 찍혀 있는 공원이라고 했을때, updata가 되면서 인풋 이미지의 벤치, 하늘, 사람 등 고양이를 제외한 배경들의 가중치는 줄어들게 되고, 고양이에 해당된 가중치들이 업데이트 된다. 고양이이라는 이미지에 맞춰서 FE를 뽑게 된다.

Low level Feature 에서는 주로 이미지를 구성하는 "선"의 특징들로 구성되어 있다. 그 다음 단계인 Mid에서는 더 상세한 특징이 보다는 "추상적인" 특징들이 뽑힌다. layer가 깊어질수록 추상적인 이미지가 뽑힌다.

위 그림을 보듯이, layer가 깊어질수록 뭉개지면서 추상적인 이미지가 생기게 됨을 확인할수있다.

왼쪽 새 이미지의 한 부분에 대해서 Feature를 만든다. 이렇게 만든 Feature에 layer를 추가하여 추상적인 이미지를 뽑는다. 이 과정을 반복하여 만든 Featrue들을 Classifier layer에 넣어서 최종적으로 판단하게 된다. CNN = Feature Extractor + Classifier networt로 구성되어 있다. 최선의 FE를 위해서 필터 가중치를 updata 시킨다. 그리하여 최적의 Feature를 생성한다.

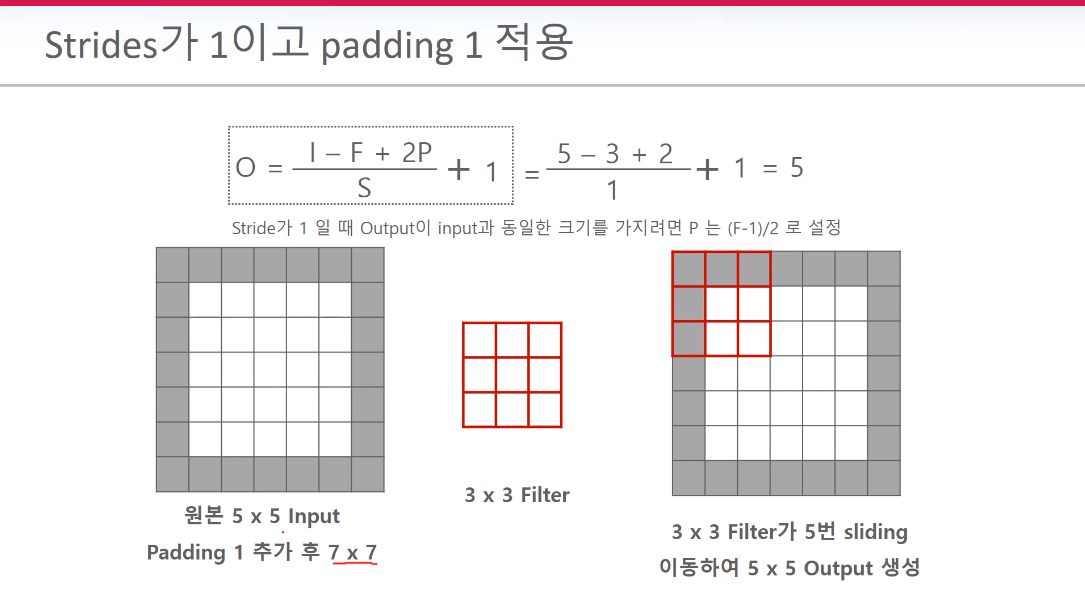
왼쪽처럼 필터를 적용하면 이미지가 작아진다. 그래서 오른쪽의 Zero padding을 사용하여 원본이미지를 7*7로 만들고 필터 계산하여 원본 사이즈인 5*5로 만들수 있다. 참고로 필터는 여러개의 커널로 구성되어 있다.
*Kernal size 특징

커널사이즈를 높일수록 계산될 파라미터들이 많아진다. 7*7는 Alexnet에서 사용된 이후로 잘 사용되지 않고 있다.
*Feature Map 개요

Feature map이란 필터들을 적용한 결과를 말한다. 4개의 feature map이 있다는건 4개의 필터를 적용했기 때문이다. 위 형식이 CNN의 기본 과정이다.
*Stride


*Padding


원본이미지를 유지하기 위해서 상하좌우 겉 테두리에 0값을 넣는게 패딩이다.

패딩의 목적은 layer가 길어질수록 feature map이 작아지는 문제점을 막기 위함이다. 모서리 부분에는 패딩에 의해서 중첩 계산이 발생하므로 모서리의 특징이 보다 더 강화가 된다.
*Pooling

Pooling은 Pool size 만큼 stride가 동일하게 적용된다. 만일 동일하게 하지 않을 시, 중첩되는 부분이 발생하기 때문에 이를 방지하고자 겹치지 않게 Pooling을 하게 된다.보통 Average Pooling은 잘 사용되지 않는다. 뽑고자 하는 특징과 그렇지 않는 특징이 혼합된 경우에 평균으로 계산하면 target 특징을 잘 표현하지 못하게 되기 때문이다. Max을 이용하여 가장 뚜렷하고 특징적인 부분을 뽑고자 Max Pooling을 주로 선호한다. 보통 2*2 Max Pooling을 이용한다.


leNet, AlexNet에는 Conv2d(S/P) -> Pooing 매커니즘 토대를 닦아 놓았다. VGG에서는 이러한 매커니즘을 충실히 반영한 모델이다. 하지만 최근 모델에는 Pooling을 자제하고 Stride를 이용하려는 경향이 강해지고 있다.
*채널과 커널의 이해


중요하게 봐야 할 점은 Input과 kernel 연산 -> "더하기" -> 2차원의 Output이 생성된다는 점이다.

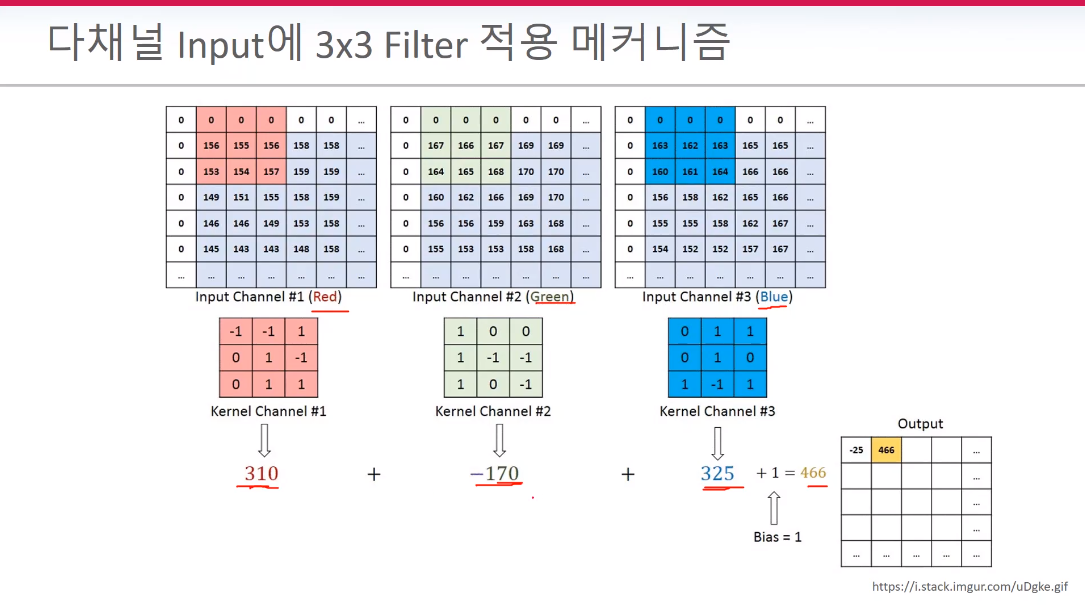

bias 1을 위 그림처럼 일일히 더해줘야 한다.
*피처맵 크기 공식




s=2 적용시, 가장 오른쪽 부분이 계산 안될수가 있다. 그래서 s=2일때는 주의를 기울어야한다. 빨간 줄 부분이 연산되지 않는 부분이다.

이러한 부분을 해결하기 위해서 padding을 사용한다. s=2일때 padding='same'을 사용하게 된다. 이때 padding의 의미가 달라진다. s=1일때는 input과 output size를 동일하게 한다는 의미였지만, 위 그림을 보면 (3,3,1)로 출력 되었다. 즉, 빠지는 부분 없이 연산을 하겠다 라는 의미로 s=2에서는 padding이 사용된다.

padding='same'을 하게 되면 6*6 -> 8*8로 변한다. 사실 7*7만 있어도 빠지는 부분없이 연산이 가능하다. 그래서 위 이미지처럼 zero 패딩을 수동으로 입력할수 있다. (1,0) -> 위로 패딩 한줄 ,(1,0) -> 왼쪽에 패딩 한줄 이다. 빨간 박스를 보면 위,왼쪽에 빨간선이 추가가 된걸 확인할수 있다. 그렇다면 "아래 한줄, 오른쪽 한줄"은 무엇일까 (0,1),(0,1) 이다.

'Data Diary' 카테고리의 다른 글
| 2021-10-6(따릉이 프로젝트 완성하기 11) (0) | 2021.10.06 |
|---|---|
| 2021-10-5(따릉이 프로젝트 완성하기 10) (0) | 2021.10.06 |
| 2021-09-30(딥러닝 CNN 2_Optimizer) (0) | 2021.09.30 |
| 2021-09-26,29(딥러닝 CNN 1_활성화 함수의 이해 & 크로스 엔트로피) (0) | 2021.09.29 |
| 2021-09-28(따릉이 프로젝트 완성하기 9) (0) | 2021.09.28 |


