시계열 데이터 심화 강의의 마지막 단계인 실습프로젝트들 중 bitcoin을 포스팅하겠습니다.
MLP
from keras.models import Sequential, Model, load_model
from keras.layers import Input, Dense, Activation, Flatten, Dropout
from keras.layers import SimpleRNN, LSTM, GRU
###MLP
#Data Loading
location= './Data/Cry/Bitcoint.csv')
raw_all= pd.read_csv(location, index_col='Date')
#Parameters
criteria ='2020-01-01'
scaler= predprocessing.minMaxScaler()
sequence=60
batch_size=32
epoch=10
verbose=1
dropout_ratio=0
# Feature Engineering
# train & test split
train = raw_all.loc[raw_all.index < criteria,:]
test = raw_all.loc[raw_all.inex >= criteria,:]
print('Train_size:', train.shape, 'Test_size:', test.shape)
## Scaling
train_scaled = scaler.fit_transform(train)
test_scaled = scaler.transform(test)
#X/Y split
X_train, Y_train =[], []
for index in range(len(train_scaled)-sequence):
X_train.append(train_scaled[index: index+sequence])
Y_train.append(train_scaled[index + sequence])
X_test, Y_test =[], []
for index in range(len(test_scaled)-sequence):
X_test.append(test_scaled[index: index + sequence])
Y_test.append(test_scaled[index+sequence])
## Retype and Reshape
X_train, Y_train = np.array(X_train), np.array(Y_train) #리스트로 묶여 있는 걸 어레이로 변경
X_test, Y_test = np.array(X_test), np.array(Y_test)
print('X_train:', X_train.shape, 'Y_train:', Y_train.shape)
print('X_test:', X_test.shape, 'Y_test:', Y_test.shape)
X_train=X_train.reshape(X_train.shape[0], X_train.shpae[1])
X_test =X_test.reshape(X_test.shape[0], X_test.shape[1])
print('Reshaping for MLP')
#X_train, test shape is (row, sequence, feature)
print('X_train:', X_train.shape, 'Y_train:', Y_train.shape)
print('X_test:', X_test.shape, 'Y_test:', Y_test.shape)
model = Sequential()
model.add(Dense(128, input_shape=(X_train.shape[1],), activation='relu'))
'''
input은 row를 빼고 다 넣으면된다. 왜? 미니배치(32)가 돌아가면서 끝까지 할테니까
핵심은 안에서 돌아가는 데이터가 무엇이냐가 중요하다
60개 feature가 히든레이어의 input 수
'''
#3차원으로 입력할 경우 (60,1)
# model.add(Dense(128, input_shape=(X_train.shape[1],X_train.shape[2]), activation='relu'))
'''
첫번째 outputshape는 (60,1) -> (none,60,128)로 바뀜
60개 feature가 128개 패턴으로 바뀐게 아니라 1 컬럼이 128개로 증식된것.
사실 이렇게 해도 무방하다 하지만 문제는 최종적으로 나오는 shape이다.
최종 shape는 (1035*60,1)가 나온다. Y_train 의 (1035,1)과 맞지가 않아서
evaluate를 할수 없다
'''
model.add(Dropout(dropout_ratio)) #128*0.2(dropout) 수 만큼 '지우는것'
model.add(Dense(256, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(128, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(64, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(1))
model.complie(doptimaizer='adam', loss='mean_squared_error')
model.summary()
model_fit() =mmodel.fit(X_train, Y_train, batch_size=batch_size, epochs=epoch,verbose=verbose)
plt.plot(pd.DataFrame(model_fit.history())
plt.grid(True)
plt.show()
#prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predict(x_test)
#evaluation
result = model.evaluate(X_test, Y_test_pred)
if scaler !=[]:
Y_train =scaler.inverse_transform(Y_train)
Y_train_pred = scaler.inverse_transform(Y_train_pred)
Y_test - scaler.inverse_tainsform(Y_test)
Y_test_pred - scaler.inverse_transform(y_test_pred)
Score_MLP, Residual_tr, Residual_te = evaluation_trte(pd.DataFrame(Y_train), Y_train_pred.flatten(),
pd.DataFrame(Y_test), Y_test_pred.flatten(),
graph_on=True)
display(Score_MLP) 
위 예시에서는 input_shape= (X_train.shape[1],) 였는데 이렇게 실행하기 위해서는 사전에 3차원을 2차원으로 축소해야 한다.
그러면 3차원을 그대로 사용할려면 어떻게 해야 할까?
input_shape= (X_train.shape[1],X_train.shape[2]) 로 변경 가능하다. 즉 (60,1)로 넣을 수가 있다.
하지만 이렇게 진행할 경우 최종 shape가 Y_train shape와 맞지 않아서 Y값끼리 비교가 불가능하다. evaluation을 진행하지 못한다
input_shape= (X_train.shape[1],) 왼쪽처럼 넣게 되면 feature의 수가 60개이다. 이 값이 히든레이어의 수만큼 변형이 되면서 특징을 뽑을 수가 있는데
input_shape= (X_train.shape[1],X_train.shape[2])로 넣게 되면 (60,1)로 입력이 되고 Dense(128)를 만나게 되면 feature를 60개로 인식을 안 하고 1로 인식한다. 즉 1->128로 늘어난다. 이 방법이 틀린 게 아니다. 아래 이미지로 추가 설명을 한다면
dense_49 => (none, 60, 64)이다. 이를 Dense(1) 통과시키면 (none,60,1)이 된다. 대체 어떻게 변한 걸까?
행이 None으로 지정되는 이유는 데이터의 갯수는 계속해서 추가될 수 있기 때문에 딥러닝 모델에서는 주로 행을 무시하는데 이해를 돋기위해서 여기서의 none를 1035라고 하겠습니다(1035는 전체데이터)
None은 총 row인 1035이다. 즉 60*1 이 1035개가 있다는 뜻이 된다. 즉 각 row마다 1035개가 있다.
결국 (60*1035,1)이라는 소리인데 이 모양은 Y_train (1035,1)와 비교는 할 수 없음을 딱 봐도 알 수 있다.
따라서 문제 해결을 위해서는 60*1035를 1035로 만들어야 한다. 아래 그림을 보면서 설명해본다
dense_49의 형태를 직접 그려 봤다. (60,64) 매트릭스가 1035개가 있는 형태이다. (위 그림의 1034 오타 -> 1035 ), 60*64사이즈의 A4용지가 1035장 쌓여 있는 것이다. 60*64=3840이다. 이 둘을 곱해서 가로로 나열하여 1035를 쌓아버린다. 이때 사용되는 것이 flatten()이다. 최종적으로 세로가 1035*3840의 매트릭스가 되고 이를 Dense(1)에 넣게 되면 3840+1(bias)가 1로 변한다
아래 Param을 보면 3841로 출력되어 있다. (3841 * 1 = 3841)
최종적으로 y_train과 비교가 가능한 (1035,1) 형태가 되었다.
RNN
# Data Loading
location = './Data/Cryptocurrency/Bitcoin.csv'
raw_all = pd.read_csv(location, index_col='Date')
raw_all.index = pd.to_datetime(raw_all.index)
# Parameters
criteria = '2020-01-01'
scaler = preprocessing.MinMaxScaler()
sequence = 60
batch_size = 32
epoch = 10
verbose = 1
dropout_ratio = 0
# Feature Engineering
## Train & Test Split
train = raw_all.loc[raw_all.index < criteria,:]
test = raw_all.loc[raw_all.index >= criteria,:]
print('Train_size:', train.shape, 'Test_size:', test.shape)
## Scaling
train_scaled = scaler.fit_transform(train)
test_scaled = scaler.transform(test)
## X / Y Split
X_train, Y_train = [], []
for index in range(len(train_scaled) - sequence):
X_train.append(train_scaled[index: index + sequence])
Y_train.append(train_scaled[index + sequence])
X_test, Y_test = [], []
for index in range(len(test_scaled) - sequence):
X_test.append(test_scaled[index: index + sequence])
Y_test.append(test_scaled[index + sequence])
## Retype and Reshape
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_test, Y_test = np.array(X_test), np.array(Y_test)
print('X_train:', X_train.shape, 'Y_train:', Y_train.shape)
print('X_test:', X_test.shape, 'Y_test:', Y_test.shape)
# RNN
model = Sequential()
#return_sequences: 출력된 아웃풋을 그대로 받아 올건지(이전 히든스테이트가 학습에 사용되도록)
#X_train.shape[1]: 시간 정보 와 X_train.shape[2]: 컬럼을 입력으로 사용
model.add(SimpleRNN(128, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=True, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(SimpleRNN(256, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(SimpleRNN(128, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(SimpleRNN(64, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(Flatten())
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
'''
컬럼이 1 -> 128개로 증식 x
60개 시퀀스를 128개 시퀀스 패턴으로 바뀐다.
즉, 60*1 이라는 패턴을 60*128개로 바꾸는 느낌으로 해석하는게 맞다
시퀀스 자체를 늘린다.
'''
model_fit = model.fit(X_train, Y_train,
batch_size=batch_size, epochs=epoch,
verbose=verbose)
plt.plot(pd.DataFrame(model_fit.history))
plt.grid(True)
plt.show()
# prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predict(X_test)
# evaluation
result = model.evaluate(X_test, Y_test_pred)
if scaler != []:
Y_train = scaler.inverse_transform(Y_train)
Y_train_pred = scaler.inverse_transform(Y_train_pred)
Y_test = scaler.inverse_transform(Y_test)
Y_test_pred = scaler.inverse_transform(Y_test_pred)
Score_RNN, Residual_tr, Residual_te = evaluation_trte(pd.DataFrame(Y_train), Y_train_pred.flatten(),
pd.DataFrame(Y_test), Y_test_pred.flatten(), graph_on=True)
display(Score_RNN)
# error analysis
# error_analysis(Residual_te, ['Error'], pd.DataFrame(X_train.reshape(X_train.shape[0], X_train.shape[1])), graph_on=True)

LSTM
# Data Loading
location = './Data/Cryptocurrency/Bitcoin.csv'
raw_all = pd.read_csv(location, index_col='Date')
raw_all.index = pd.to_datetime(raw_all.index)
# Parameters
criteria = '2020-01-01'
scaler = preprocessing.MinMaxScaler()
sequence = 60
batch_size = 32
epoch = 10
verbose = 1
dropout_ratio = 0
# Feature Engineering
## Train & Test Split
train = raw_all.loc[raw_all.index < criteria,:]
test = raw_all.loc[raw_all.index >= criteria,:]
print('Train_size:', train.shape, 'Test_size:', test.shape)
## Scaling
train_scaled = scaler.fit_transform(train)
test_scaled = scaler.transform(test)
## X / Y Split
X_train, Y_train = [], []
for index in range(len(train_scaled) - sequence):
X_train.append(train_scaled[index: index + sequence])
Y_train.append(train_scaled[index + sequence])
X_test, Y_test = [], []
for index in range(len(test_scaled) - sequence):
X_test.append(test_scaled[index: index + sequence])
Y_test.append(test_scaled[index + sequence])
## Retype and Reshape
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_test, Y_test = np.array(X_test), np.array(Y_test)
print('X_train:', X_train.shape, 'Y_train:', Y_train.shape)
print('X_test:', X_test.shape, 'Y_test:', Y_test.shape)
# LSTM
model = Sequential()
model.add(LSTM(128, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=True, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(LSTM(256, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(LSTM(128, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(LSTM(64, return_sequences=False, activation="relu"))
'''
마지막 부분에서 return을 False로 놓으면 시퀀스 입력이 중지가 되고
3차원이 시간정보가 사라지면서 2차원으로 줄어든다 즉, flatten기능을 대신 할수있다.
'''
model.add(Dropout(dropout_ratio))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit = model.fit(X_train, Y_train,
batch_size=batch_size, epochs=epoch,
verbose=verbose)
plt.plot(pd.DataFrame(model_fit.history))
plt.grid(True)
plt.show()
# prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predict(X_test)
# evaluation
result = model.evaluate(X_test, Y_test_pred)
if scaler != []:
Y_train = scaler.inverse_transform(Y_train)
Y_train_pred = scaler.inverse_transform(Y_train_pred)
Y_test = scaler.inverse_transform(Y_test)
Y_test_pred = scaler.inverse_transform(Y_test_pred)
Score_LSTM, Residual_tr, Residual_te = evaluation_trte(pd.DataFrame(Y_train), Y_train_pred.flatten(),
pd.DataFrame(Y_test), Y_test_pred.flatten(), graph_on=True)
display(Score_LSTM)
# error analysis
# error_analysis(Residual_te, ['Error'], pd.DataFrame(X_train.reshape(X_train.shape[0], X_train.shape[1])), graph_on=True)

GRU
# Data Loading
location = './Data/Cryptocurrency/Bitcoin.csv'
raw_all = pd.read_csv(location, index_col='Date')
raw_all.index = pd.to_datetime(raw_all.index)
# Parameters
criteria = '2020-01-01'
scaler = preprocessing.MinMaxScaler()
sequence = 60
batch_size = 32
epoch = 10
verbose = 1
dropout_ratio = 0
# Feature Engineering
## Train & Test Split
train = raw_all.loc[raw_all.index < criteria,:]
test = raw_all.loc[raw_all.index >= criteria,:]
print('Train_size:', train.shape, 'Test_size:', test.shape)
## Scaling
train_scaled = scaler.fit_transform(train)
test_scaled = scaler.transform(test)
## X / Y Split
X_train, Y_train = [], []
for index in range(len(train_scaled) - sequence):
X_train.append(train_scaled[index: index + sequence])
Y_train.append(train_scaled[index + sequence])
X_test, Y_test = [], []
for index in range(len(test_scaled) - sequence):
X_test.append(test_scaled[index: index + sequence])
Y_test.append(test_scaled[index + sequence])
## Retype and Reshape
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_test, Y_test = np.array(X_test), np.array(Y_test)
print('X_train:', X_train.shape, 'Y_train:', Y_train.shape)
print('X_test:', X_test.shape, 'Y_test:', Y_test.shape)
# GRU
model = Sequential()
model.add(GRU(128, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=True, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(GRU(256, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(GRU(128, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(GRU(64, return_sequences=False, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit = model.fit(X_train, Y_train,
batch_size=batch_size, epochs=epoch,
verbose=verbose)
plt.plot(pd.DataFrame(model_fit.history))
plt.grid(True)
plt.show()
# prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predict(X_test)
# evaluation
result = model.evaluate(X_test, Y_test_pred)
if scaler != []:
Y_train = scaler.inverse_transform(Y_train)
Y_train_pred = scaler.inverse_transform(Y_train_pred)
Y_test = scaler.inverse_transform(Y_test)
Y_test_pred = scaler.inverse_transform(Y_test_pred)
Score_GRU, Residual_tr, Residual_te = evaluation_trte(pd.DataFrame(Y_train), Y_train_pred.flatten(),
pd.DataFrame(Y_test), Y_test_pred.flatten(), graph_on=True)
display(Score_GRU)
# error analysis
error_analysis(Residual_te, ['Error'], pd.DataFrame(X_train.reshape(X_train.shape[0], X_train.shape[1])), graph_on=True)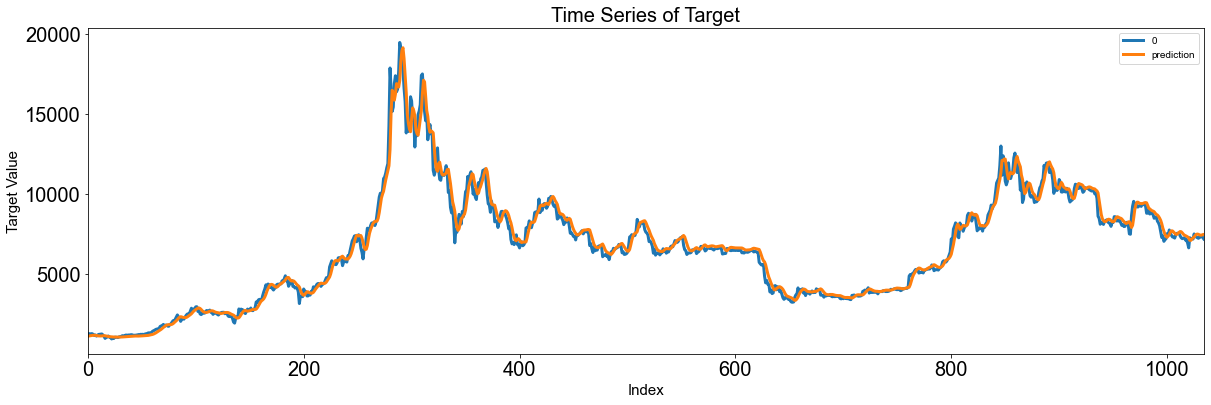

'실습 note' 카테고리의 다른 글
| 주택 가격 예측실습 (0) | 2021.04.16 |
|---|---|
| 자전거 수요예측 실습 (0) | 2021.04.16 |
| 제조 공정 불량 검출 실습 (0) | 2021.03.11 |
| OpenCV_12(딥러닝2) (0) | 2021.03.05 |
| OpenCV_11(딥러닝) (0) | 2021.03.04 |


