시계열 데이터 심화 강의의 마지막 단계인 실습프로젝트들 중 주택 가격 예측실습을 포스팅하겠습니다.
본 실습은 성능보다는 어떻게 적용할지에 대한 내용만 간략하게 소개되어 있음을 알립니다.
MLP
# Data Loading
location = './Data/RealestateKorea_Gangnam/Economy.csv'
raw_all = pd.read_csv(location)
raw_all
# feature engineering
raw_all['Date'] = pd.to_Datetime(Raw_all['Date'])
raw_all.index =raw_all['Date']
raw_all = raw_all[raw_all.index >= '200-01-01']
raw_all = raw_all[raw_all.index <= '2017-12-31']
raw_all.fillna(method='bfill', inplace=True)
# Data split
Y_colname =['Price']
X_remove =['Date','price_Sido']
X_colname =[x for x in raw_all.columns if x not in Y_colname+X_remove]
X_train, X_Test, Y_train, Y_test = datasplit_ts(raw_all, Y_colname, X_colname, '2016-01-01')
# Parameters
scaler_X_tr = preprocessing.MinMaxScaler()
scaler_Y_tr = preprocessing.MinMaxScaler()
# sequence = 34
batch_size = 32
epoch = 20
verbose = 1
dropout_ratio = 0
# Feature Engineering
## Scaling
X_train = scaler_X_tr.fit_transform(X_train)
Y_train = scaler_Y_tr.fit_transform(Y_train)
X_test = scaler_X_tr.transform(X_test)
Y_test = scaler_Y_tr.transform(Y_test)
# MLP
model = Sequential()
model.add(Dense(128, input_shape=(train.shape[1],), activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Desne(64, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(1))
model.complie(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit=model.fit(X_train. Y_train, batch_size=batch_size,
epochs=epoch, verbose=verbose)
pd.plot(pd.DataFrame(model_fit.history))
plt.grid(True)
plt.show()
#prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predcit(X_test)
#evaluation
result = model.evaluate(X_test, Y_test_pred)
if scaler !=[]:
Y_train = scaler_Y_tr.inverse_transform(Y_train)
Y_test = scaler_Y_tr.inverse_transform(Y_test)
Y_train_pred = scaler_Y_tr.inverse_transform(Y_train_pred)
Y_test_pred = scaler_Y_tr.inverse_transform(Y_test_pred)
Score_MLP, Residual_tr, Residual_te = evaluation_trte(pd.DataFrame(Y_train), Y_train_pred.flatten(),
pd.DataFrame(Y_test), Y_test_pred.flatten(), graph_on=True)
display(Score_MLP)
RNN
*그래프 결과만
LSTM
GRU
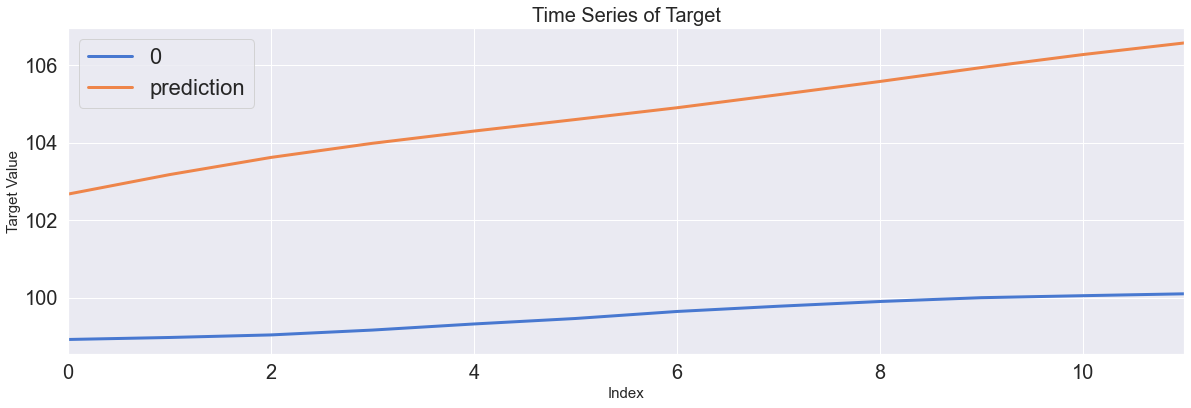
각 딥러닝 모델에 따른 결과를 출력했습니다. 각자 비슷한 성능을 보이는 가운데 여기서 한번 생각해 봐야 할 점이 있습니다. Y값은 부동산 가격입니다. 그래프를 보면 부동산 가격이 너무 변동이 심하다는 걸 볼수 있습니다. 현실적으로
올해 1억하던 매물이 내년에 갑자기 확 뛰거나 내리는 현상은 위 시각화 처럼 자주 발생하지 않습니다
뭔가 이상하다는 걸 느껴야 합니다. 입력된 데이터에서 뭔가가 잘못되었음을 알수 있습니다.
데이터 원본입니다. 빌딩 타입별로 분류가 되어 있습니다. 또한 2006-01-01의 정보를보면 건물 타입과 지역마다 여러 행으로 분리 되어 있습니다. 즉, 이를 한번에 넣고 모델을 돌리게되면 심각한 정보 왜곡이 발생됩니다.
여기서 우리가 알고 싶은점은 부동산 가격입니다. 이 데이터는 강남지역의 부동산 데이터인데, 위 처럼 여러개의 y값이 아닌 강남 부동산 가격을 대표할만한 y를 추정해야 합니다. 강의에서는 2가지를 예시로 들었습니다.
아래 코드를 통해 어떤식으로 적용했는지 보겠습니다.
실습에 적용된 모델은 GRU로 모두 동일합니다.
CASE1: year, month의 groupby한 평균값 사용
# Data Loading
location = './Data/RealestateKorea_Gangnam/Economy.csv'
raw_all = pd.read_csv(location)
date = raw_all['Date'].unique()
raw_all = raw_all.groupby(['Year','Month']).mean().rest_index().iloc[:,2:]
raw_all['Date']= date
# Feature Engineering
raw_all['Date'] = pd.to_datetime(raw_all['Date'])
raw_all.index = raw_all['Date']
raw_all = raw_all[raw_all.index >= '2010-01-01']
raw_all = raw_all[raw_all.index <= '2017-12-31']
raw_all.fillna(method='bfill', inplace=True)
# Data Split
Y_colname = ['Price']
#지역과 빌딩 타입은 숫자의 의미가 없기때문에 삭제
X_remove = ['Date', 'Region', 'Price_Sido', 'Building_Type']
X_colname = [x for x in raw_all.columns if x not in Y_colname+X_remove]
X_train, X_test, Y_train, Y_test = datasplit_ts(raw_all, Y_colname, X_colname, '2016-01-01')
# Parameters
scaler_X_tr = preprocessing.MinMaxScaler()
scaler_Y_tr = preprocessing.MinMaxScaler()
sequence = 12
batch_size = 32
epoch = 20
verbose = 1
dropout_ratio = 0
# Feature Engineering
## Scaling
X_train_scaled = scaler_X_tr.fit_transform(X_train)
Y_train_scaled = scaler_Y_tr.fit_transform(Y_train)
X_test_scaled = scaler_X_tr.transform(X_test)
Y_test_scaled = scaler_Y_tr.transform(Y_test)
## X / Y Split
X_train, Y_train = [], []
for index in range(len(X_train_scaled) - sequence):
X_train.append(np.array(X_train_scaled[index: index + sequence]))
Y_train.append(np.ravel(Y_train_scaled[index + sequence:index + sequence + 1]))
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_test, Y_test = [], []
for index in range(len(X_test_scaled) - sequence):
X_test.append(np.array(X_test_scaled[index: index + sequence]))
Y_test.append(np.ravel(Y_test_scaled[index + sequence:index + sequence + 1]))
X_test, Y_test = np.array(X_test), np.array(Y_test)
## Retype and Reshape
X_train = X_train.reshape(X_train.shape[0], sequence, -1)
X_test = X_test.reshape(X_test.shape[0], sequence, -1)
print('X_train:', X_train.shape, 'Y_train:', Y_train.shape)
print('X_test:', X_test.shape, 'Y_test:', Y_test.shape)
# GRU
model = Sequential()
model.add(GRU(128, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=True, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(GRU(256, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(GRU(128, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(GRU(64, return_sequences=False, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit = model.fit(X_train, Y_train,
batch_size=batch_size, epochs=epoch,
verbose=verbose)
plt.plot(pd.DataFrame(model_fit.history))
plt.grid(True)
plt.show()
# prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predict(X_test)
# evaluation
result = model.evaluate(X_test, Y_test_pred)
if scaler_Y_tr != []:
Y_train = scaler_Y_tr.inverse_transform(Y_train)
Y_train_pred = scaler_Y_tr.inverse_transform(Y_train_pred)
Y_test = scaler_Y_tr.inverse_transform(Y_test)
Y_test_pred = scaler_Y_tr.inverse_transform(Y_test_pred)
Score_GRU, Residual_tr, Residual_te = evaluation_trte(pd.DataFrame(Y_train), Y_train_pred.flatten(),
pd.DataFrame(Y_test), Y_test_pred.flatten(), graph_on=True)
display(Score_GRU)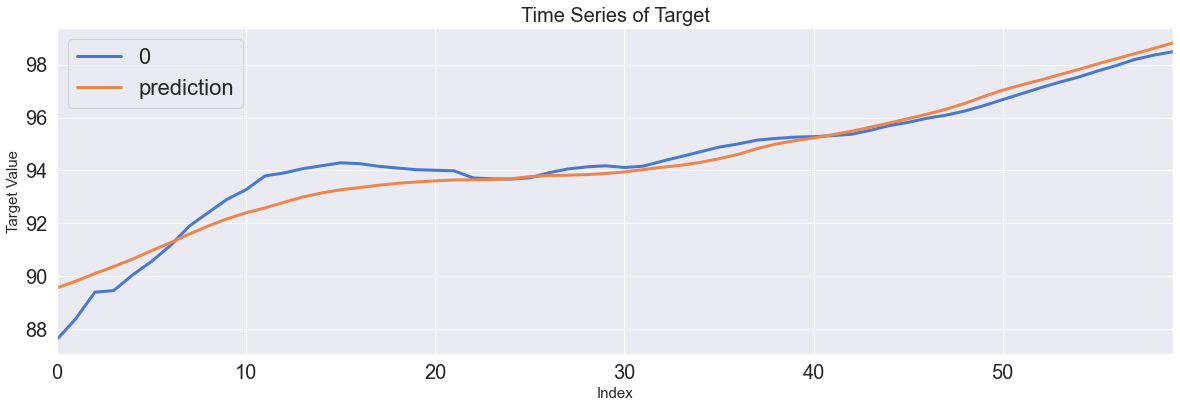
CASE2: 특정한 지역과 빌딩타입을 선택
# Data Loading
location = './Data/RealestateKorea_Gangnam/Economy.csv'
raw_all = pd.read_csv(location)
raw_all = raw_all[(raw_all['Region'] == 50000) & (raw_all['Buillding_type'] == 0)]
###이하 내용은 위 GRU 실습내용과 같습니다.

case1 보다 case2가 개선된 성능을 보입니다. case2같은 경우에는 처음부터 정보왜곡이 되지 않도록 특정한 범위를 선택한 것에 반해 case1은 평균값이라고 해도 다른 여러 종류의 데이터와 섞이기 때문에 성능에서 차이가 발생했습니다.
이 실습을 통해 강사가 알리고자 한 것은 알고리즘이 전부가 아니다. 알고리즘 만큼 중요한 것이 데이터 자체에 있다는 것이였습니다. 이번 강의를 계기로 원본 데이터를 어떻게 설계하느냐가 분석에 큰 영향을 끼칠수 있다는 걸 깨닫게 되었습니다. 이 포스팅을 끝으로 시계열 데이터 심화 강의 포스팅은 마치겠습니다. 좋은 강의를 만들어주신 강사님에게 감사드립니다~ (꾸벅)
'실습 note' 카테고리의 다른 글
| 2021-07-02(R_은행 거래 데이터를 활용한 마케팅 효과 실습) (0) | 2021.07.02 |
|---|---|
| 2021-07-01(R_대학원 입시 합격률 실습) (0) | 2021.07.02 |
| 자전거 수요예측 실습 (0) | 2021.04.16 |
| bitcoin 예측 실습 (0) | 2021.04.14 |
| 제조 공정 불량 검출 실습 (0) | 2021.03.11 |



