실습 링크
2021.07.20 - [기록 note] - 2021-07-20(Yolo)
2021-07-20(Yolo)
간략한 개요 *V2는 V1보다 성능 개선 되었지만 SSD보다는 떨어짐 V1 448*448이미지를 7*7 Grid로 만들면 위 그림처럼 49개의 sell이 생성된다. 생성된 각각의 셀(작은 정사각형) 이 하나의 Object에 대한 dete
ghdrldud329.tistory.com
간략한 개요

*V2는 V1보다 성능 개선 되었지만 SSD보다는 떨어짐
V1

448*448이미지를 7*7 Grid로 만들면 위 그림처럼 49개의 sell이 생성된다. 생성된 각각의 셀(작은 정사각형) 이 하나의 Object에 대한 detection을 수행한다. 기존 two-stage에서는 객체의 위치를 찾기 위해서 연산이 작동 되는데, 이 수행시간을 줄이기 위해서 Grid 개념을 적용한 것이다. 또한 위 분홍색 박스처럼 하나의 sell이 2개의 BB후보를 기반으로 BB를 예측한다. 따라서 하나의 셀은 2개의 BB후보를 기반으로 Object 하나를 예측한다. 단점은 sell하나 당 하나의 Object만 검출 한다는 것이다. sell안에 2개 이상의 객체가 있다 하더라도 하나만 검출이 되며, 하나의 sell 범위를 벗어나는 큰 객체는 검출이 불가능하다. (7*7=49sell * 2후보, 98개의 BB)


Classification, Regression을 하기 위해서 Dense layer 적용해야한다.

7*7*30에서 30은 어떤 의미 인가?

빨간색 sell은 분홍색 박스 처럼 2개의 BB후보를 가지고 있다. 2개의 BB후보는 강아지 Object를 예측하는데 개별 BB별로 5개씩 정보를 가지고 있다. 5개의 정보는 x,y,w,h 이다.
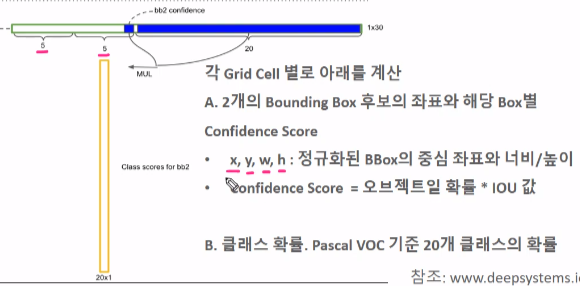
x,y는 예측한 BB후보의 센터좌표이다. confidence Score는 예측한 BB가 Object냐 아니냐를 나타내는 점수이다. 후보 BB에 얼마나 강아지 객체가 포함이 되었는지 나타내느 점수인 것이다. 나머지 20개는 Pascal VOC 기준 20개 클래스의 확률이다. 이때 주의할점은
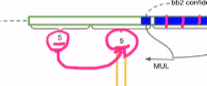
각 후보 BB별로 5개씩 생긴 정보 중 GT와 가장 많이 겹치는(Iou가 가장 높은 것) BB를 대표로 적용한다. 대표로 뽑힌 BB가 어떤 객체 인지 20개의 클래스별로 확률을 나타내는 것이다.


S: 그리드 sell을 나타낸다(7*7Grid 라면 S^2 = 49). 즉 모든 셀을 돌아가면서 loss을 구하게 된다.
B: Bounding Box를 나타낸다. 따라서 B = 2
추가로, 동그라미 표시가 된 것은 숫자 1을 나타낸다. ij는 결국 98개의 BB를 말하는 것인데, 98개 중 Object 인것만 1을 곱한다는 것이다. 즉 위에서 말한 대표 BB에만 1, 그 외 객체을 담고 있지 않은 BB들은 0을 곱하게 된다.
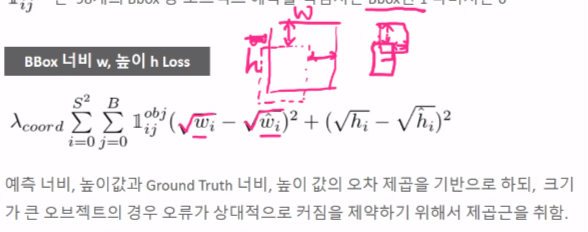
제곱근을 취한 이유: 위 분홍색 박스에서 왼쪽은 큰 객체, 오른쪽은 작은 객체를 나타낸다. 큰 객체는 사이즈 크므로 편차값 자체도 상당히 커질수가 있다. 이를 막기 위해서 제곱근을 취한다.

Ci: 예측된 confidence score 이다. Object 일 확률 P(0)*Iou
Ci^: GT이므로 1 값을 가진다.
람다noobj: 책임있는 않는BB들도 책임이 있기때문에 가중치를 매긴다. 대표 BB가 아닌 나머지 하나의 BB에 대해서도 Iou를 구해서 가중치 0.5만큼 더해준다.

클래스별로 틀린 예측확률들을 위 공식으로 계산한다.
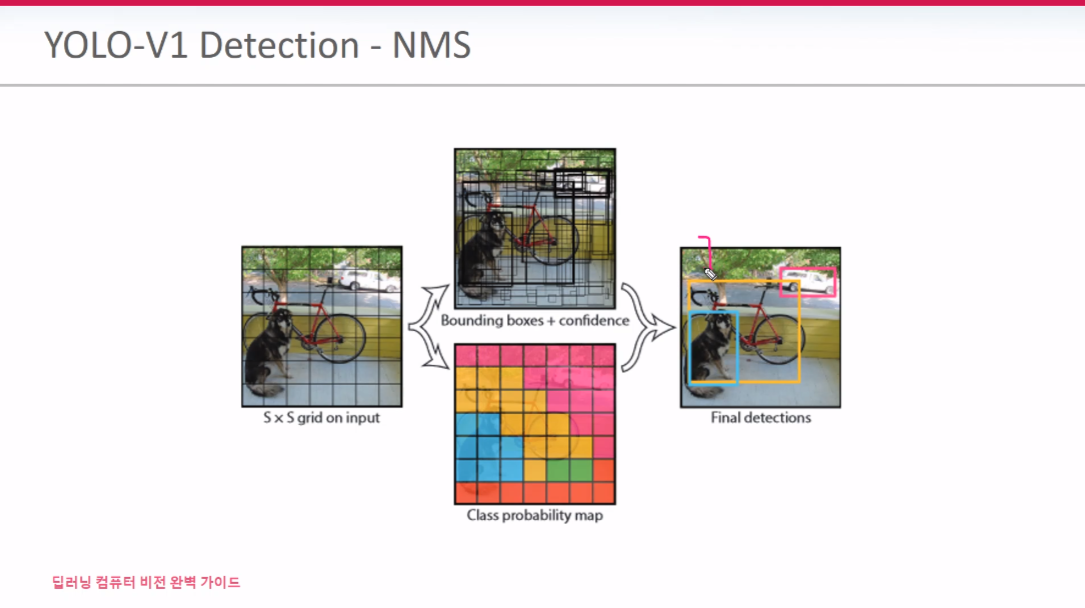
one-stage 전략은 가장 많은 예측BB를 생성 후 NMS를 통해 필터링을 하는 것이다.

위 사람을 예를 들어 본다면, 겹치는 박스가 confidence 0.9 짜리 1개와 0.65짜리 1개 잇다고 가정하겠다. 이때 이둘의 Iou값이 Iou Threshold 값보다 크다면 0.65 짜리 BB가 삭제되어서 가장 높은 confidence 값을 가진 BB만 살아 남게 된다.
한 sell이 하나의 object만을 책임지기 떄문에 한 sell안에 있는 여러 객체를 검출하지 못한다. (V2에서는 해당 문제점을 해결)
V2
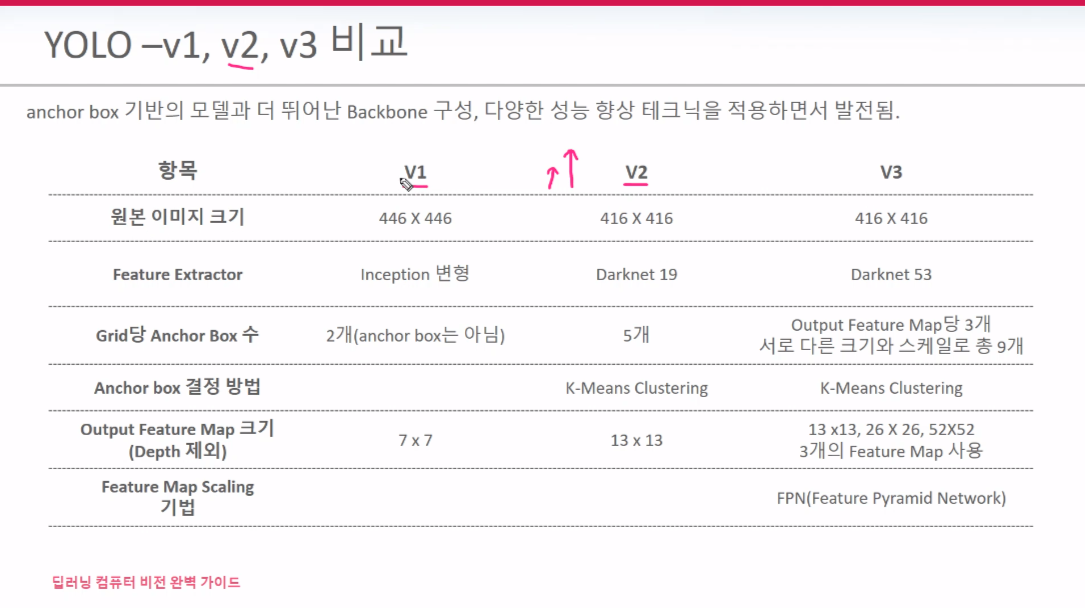
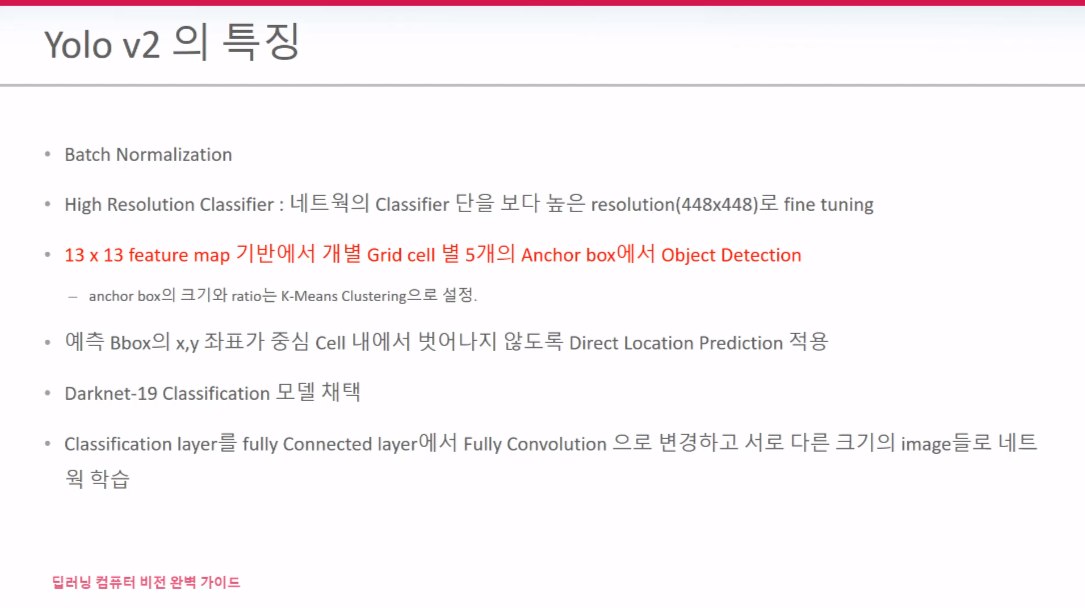

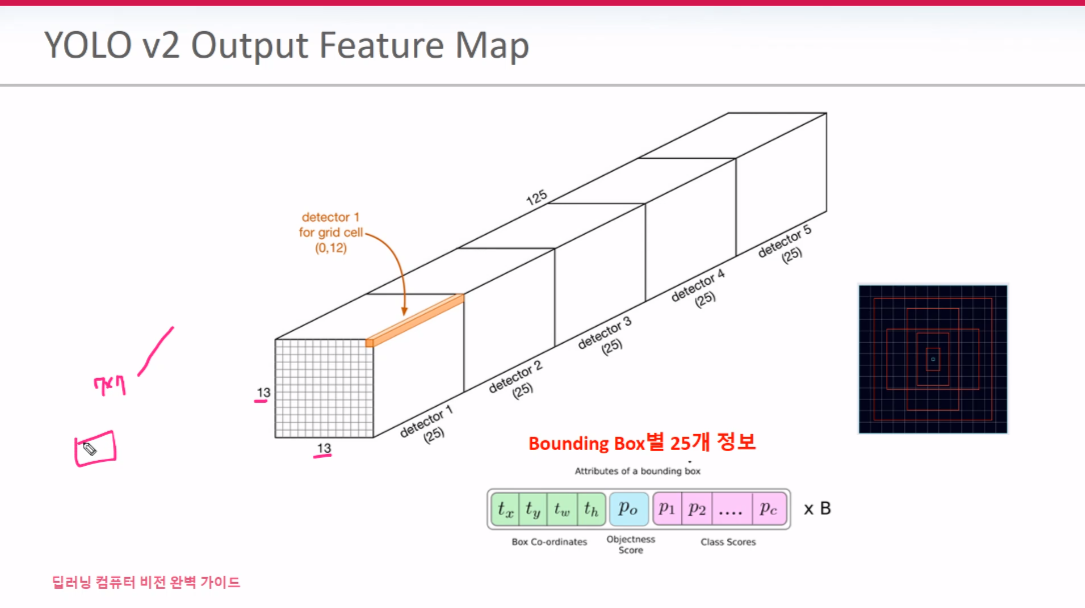
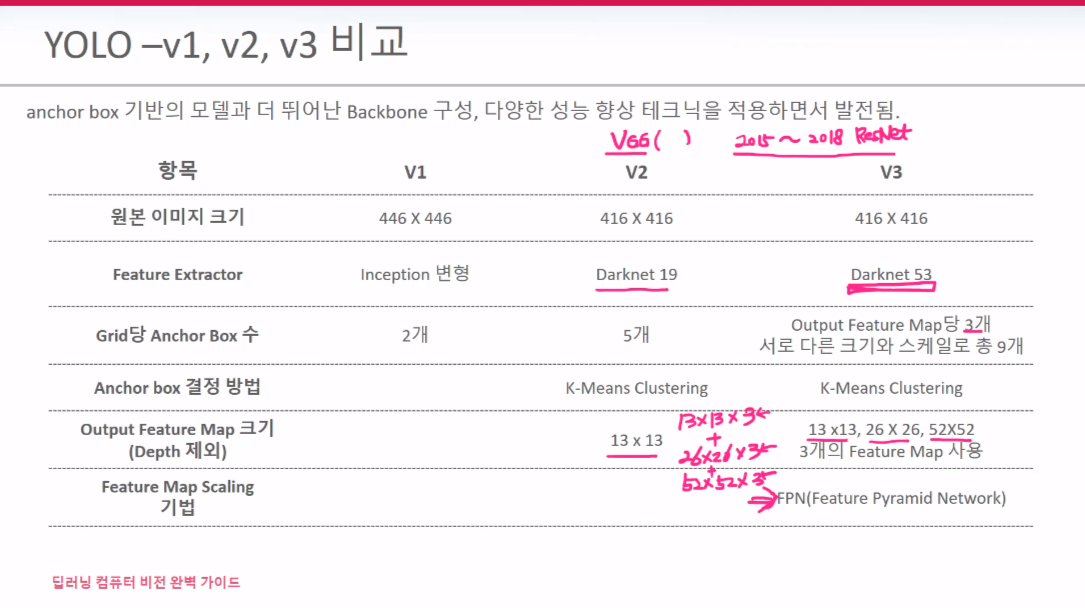
V1은 7*7*30의 FM을 가지는 반면 V2는 13*13*125 FM을 가진다. detector1~5는 Anchor Box 1~5를 가리킨다. 5개의 Anchor Box들 각각 BB별 25개 정보를 가지고 있기 때문에 125개이다. 이 의미는 한 셀안에서의 Anchor box들이 개별적으로 정보를 가지므로 V1과 다르게 한 셀 안에 여러 객체를 검출할수 있게 된다.
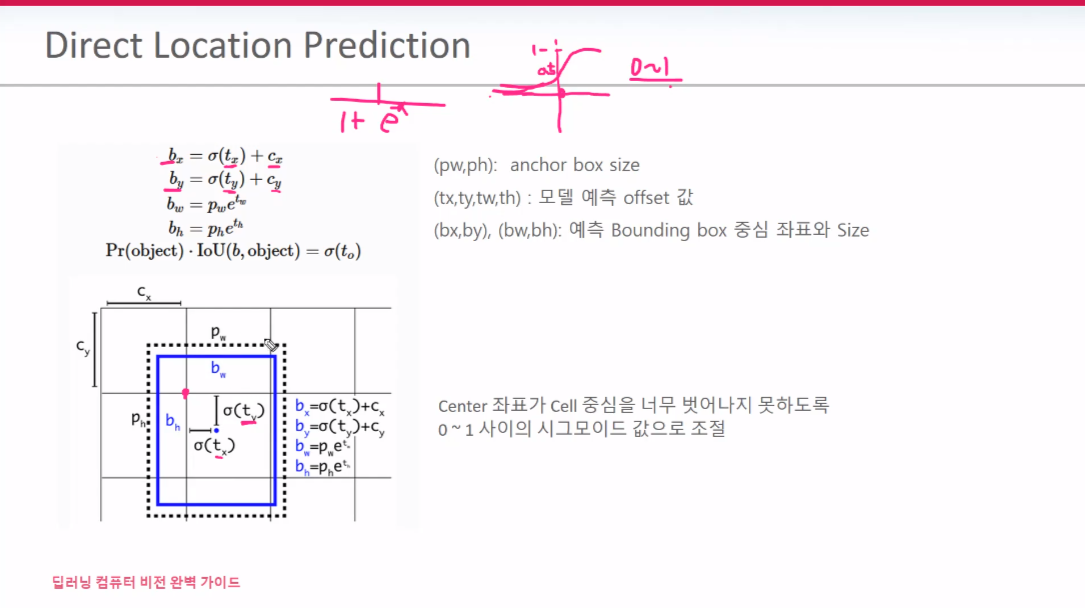
Anchor box 만드는 방식을 Direct Location Prediction 이라 한다. 분홍색 점이 Cx,Cy이다. 셀 중심점 tx,ty에 시그모이드를 적용해서 값이 0~1사이를 벗어나지 못하도록 설정한다. 그렇게 되면 bx,by는 아무리 커봤자 cell 중심을 크게 벗어나지 못하게 된다. 이 덕분에 BB가 뜬금없는 위치에서 Object Detect를 하지 않게 된다.
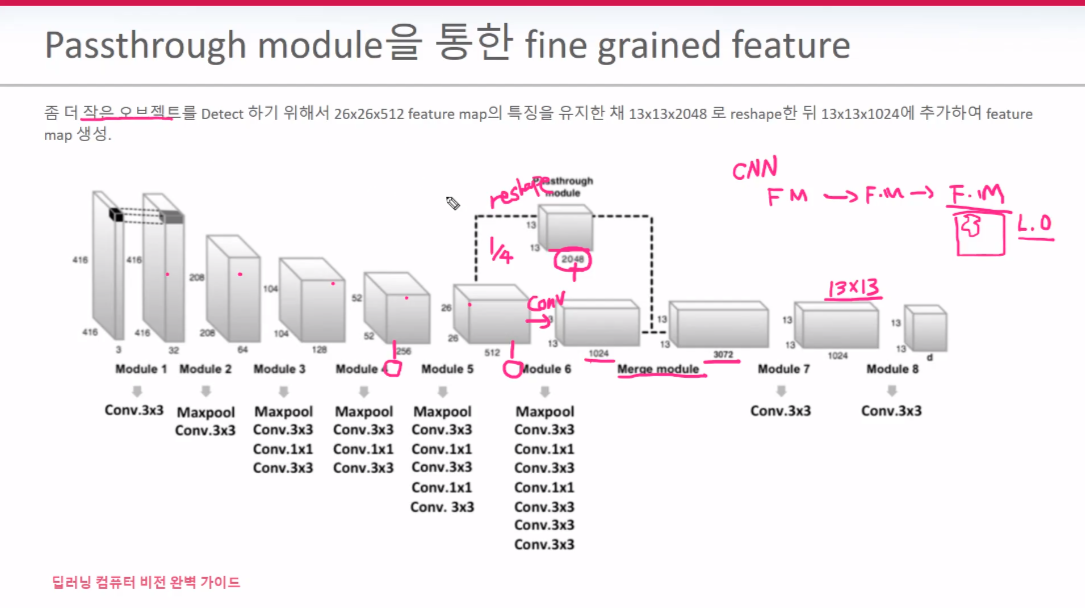
26*26*512 FM을 13*13*2048로 reshap한 후 13*13*1024와 merge를 시킨다. 따라서 26*26*2048에 존재하는 작은객체의 특징들을 살려보고자 하는 방법이다. (요즘에는 사용하지 않는다고 한다)
V3
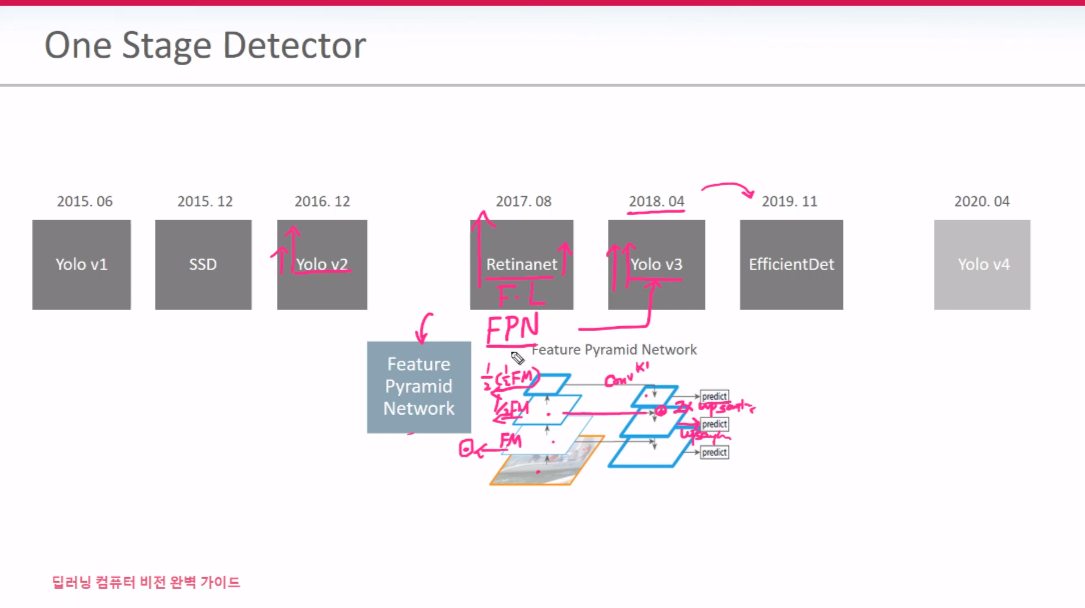
V3에는 FPN이 적용이 되는데 위 그림처럼 상위에 있던 FM의 추성적인 특징들을 하위 FM의 상세한 특징들과 merge 됨으로써 예측 정확성을 올릴 수가 있게 된다. FPN유무가 V2와 가장 다른 점이다.
FPN의 output Feature 갯수가 13*13, 26*26, 52*52 이렇게 세개의 FM이 출력된다. 각 FM 당 3개의 Anchor Box가 존재 한다. 13*13 FM의 3개 Anchor Box, 나머지 2개 FM도 각각 3개씩 할당 된다. 여기서 얻게된 Anchor box들을 가지고 Detection 진행한다.
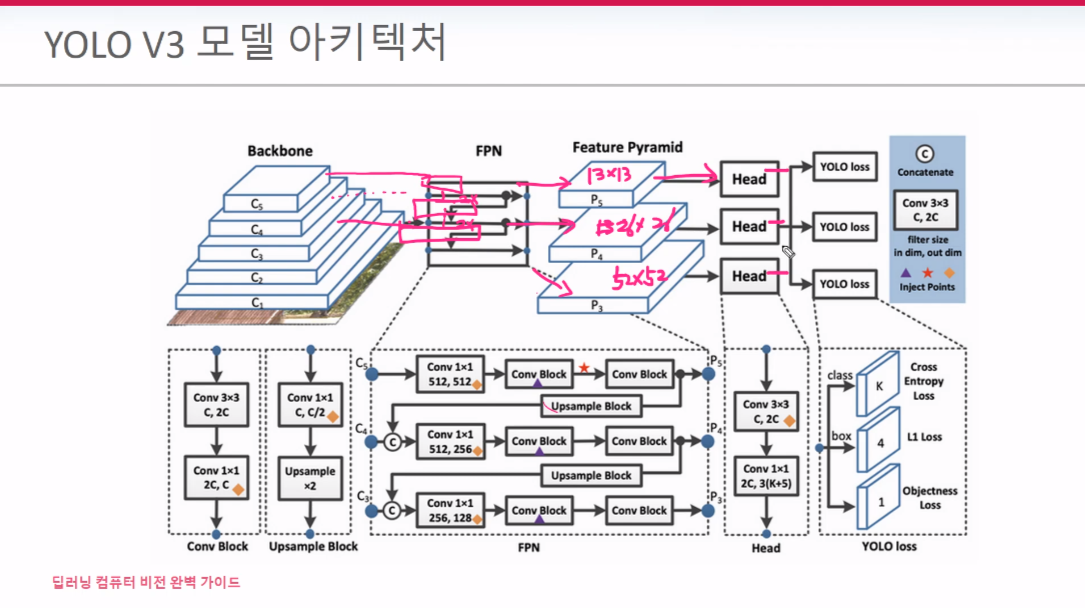
FPN을 통해 만들어진 3개의 FM을 가지고 각자 loss값을 구하면서 예측을 진행한다. 최종적으로는 NMS을 통해 필터링을 거치게 된다.
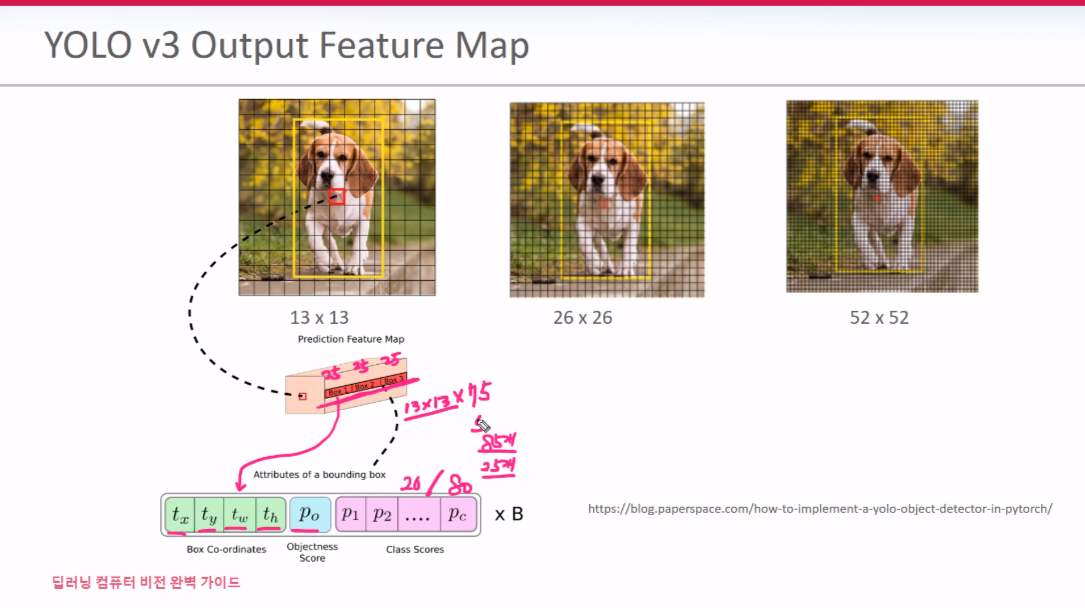
각 FM당 3개의 anchor box가 존재한다. 위 그림에서 3개의 box가 있다. 그 안에 내용물은 (BB의 중심점과 w,h + objectness Score + 20개 Class(pascal VOC 기준). 13*13은 상대적으로 큰 객체을 detect 하고 사이즈가 커질수록 작은 객체 검출에 유리하다.
'Data Diary' 카테고리의 다른 글
| 2021-07-29(Mask-RCNN_Segmentation) (0) | 2021.07.30 |
|---|---|
| 2021-07-26(RetinaNet & EfficientDet) (0) | 2021.07.26 |
| 2021-07-19(Single Shot Detector) (0) | 2021.07.19 |
| 2021-07-08~16(4. MMDetection의 이해와 Faster RCNN 적용 실습 )) (0) | 2021.07.17 |
| 2021-07-07(3. RCNN 계열 Object Detecter(RCNN, SPPNet, Fast RCNN, Faster RCNN)) (0) | 2021.07.07 |


