
Semantic Segmentation이란 masking 정보를 씌어서 전체 이미지에서 문맥적으로 의미 있는 형태를 찾아내는 개념이다. Instance Segmentation과 차이점이 있다면 동일한 객체에 대한 표현방식에 있다. Semantic은 동일 객체를 같은 색으로 분류했고 Instance는 Object Detection처럼 개별 객체에 masking 정보가 적용된다. 지금부터 배울 Mask-RCNN은 Instance Segmentation의 대표적인 방법이다. 이에 앞서 Semantic 지식이 필요하다. 왜냐하면 Mask-RCNN은 Faster-RCNN과 Semantic Segmentation 기법 중에 하나인 FCN이 결합된 형태이기 때문이다. 따라서 Semantic Segmentation 의 FCN에 대한 사전 지식이 있어야 한다.

위 그림처럼 Semantic Segmentation은 각각 개별 Class 별로 Segmentation(분할)을 시킨다. Semantic Segmentation은 기법 상으로는 Pixel Wise Classification이라고도 부른다. 이미지의 각 픽셀마다 어떤 Class에 속하는지 결정하여 이에 알맞은 Masking을 적용하기 때문이다. 가령 픽셀(0,0)은 나무, (0,1)도 나무 class라고 결정되면 이에 맞는 마스킹 정보를 적용하는 것이다. 마치 컴퓨터 기본 게임인 지뢰 찾기와 비슷한 모양일 것이다.


위 그림처럼 각 Class별로 Classification을 수행하는 것이 Segmentic Segmentaion이다.

convolution에서는 차원축소가 되면서 압축된 차원으로 변경이 되면서 추상적인 level이 올라간다(위치 특성은 사라지지만 이미지의 핵심적인 정보는 압축되어 추상적으로 변화가 됨) 반면 Deconvolution은 압축된 FM을 원본 사이즈와 유사하게 사이즈를 늘려나가면서 hidden factor들을 찾는다. 즉, 원본 이미지에서 찾을 수 없었던 특성들을 찾아내는 것이 encoder-Decoder model이다. FCN을 기점으로 Dilated FCN까지 발전되어 가고 있다.

Mask R-CNN은 Faster R-CNN이라고 해도 무방하다. 단지 masking을 하기 위해서는 FCN이 필요하기때문에 추가가 된 것이다. Faster R-CNN은 ROI Pooling이 있는데, 이것은 Segmentation을 하기엔 정확도가 떨어진다. 그래서 Pooling이 아닌 ROIAlign을 적용한다.
FCN(Fully Convolutional Network for Semantic Segmentation)
-FCN은 fully connected layer 없이 구성된 layer

Semantic Segmentation model은 Encoder-Decoder model 이 대부분이다. Encoder-Decoder model의 목적은 응축된 FM을 기반으로 하여 재창조/재해석을 하는데에 의미를 둔다.

FCN은 1차원으로 Flatten을 시키는 것이 아닌 convolutional 하게 만들어서 가로세로가 있고 4096의 depth가 있도록 만든다. 맨 마지막의 output FM convolution은 depth가 1000개이다. 1000개 depth의 의미는 각 1000개 Class에 대한 확률 값을 나타낸다(ImageNet은 1000개의 Class를 가진다) 만일 고양이라는 Class가 10번째에 해당된다면 depth 1000개 중에서 10번째를 뽑는다. 그러면 위 그림 Heatmap of cat FM을 볼 수가 있게 된다. 각 색깔의 정도는 그리드 당 (원본이미지가 아니기 때문에 픽셀이 아니다) 고양이일 확률이 각각 적혀있다.
확률이 높을수록 빨간색으로 표현이 된다. 강아지가 124번째에 해당된다면 124번 FM을 뽑으면 확률 값을 알 수 있을 것이다. Semantic은 픽셀마다 Class를 분류해야 하므로 FM의 그리드가 아닌 픽셀 단위로 계산을 해야 한다. 즉, 픽셀 * 픽셀로 예측을 하기 위해서는 depth가 1000개인 layer을 업샘플링하여 원본 이미지와 비슷한 크기로 만들어 줘야 한다.

21인 이유는 Pascal VOC이기 때문이다. class20개+background 1개 =21개 원본 이미자가 224라면 4096 depth layer은 7*7이다(21 depth layer 동일 크기) 32배로 줄어든 상태를 32배로 쭉 늘려버린다. 업 샘플링된 정보와 masking이 서로 계속 network를 학습시키는 것이다.

학습을 하게 되면서 업샘플링 가중치도 업데이트가 된다. 문제점은 7*7을 바로 224*224 바로 업 샘플링되면서 원본이 가지고 있는 정보가 상당히 뭉개진다는 점이다. 아래 이미지를 통해 좀 더 자세히 알아본다.

7*7을 32배로 업 샘플링하면 FEN-32s 이미지처럼 명확하지 않고 뭉개지는 것처럼 보이게 된다. 그리고 가장 오른쪽에 보면 업샘플링 과정 그림이 짤막하게 그려져 있다. 업 샘플링할 때는 보관법(Bilinear Interpolation)을 사용한다. 똑같진 않더라도 최대한 비슷하게 복구하려 한다. 본론으로 돌아와서 이 문제점을 해결하기 위해서 나온 방법이 FM을 혼합시키는 것이다.

ResNet의 skip connetion과 비슷한 개념이다. 7*7*4096을 2배 업샘플링하여 Pool4와 합친다. 하친 정보를 16배 업샘플링을 시킨다. 업샘플링시킨 FM을 통해 픽셀*픽셀 예측한 것을 FCN -16s라 한다. FCN-8s는 Pool3까지 포함된 것을 가리킨다.
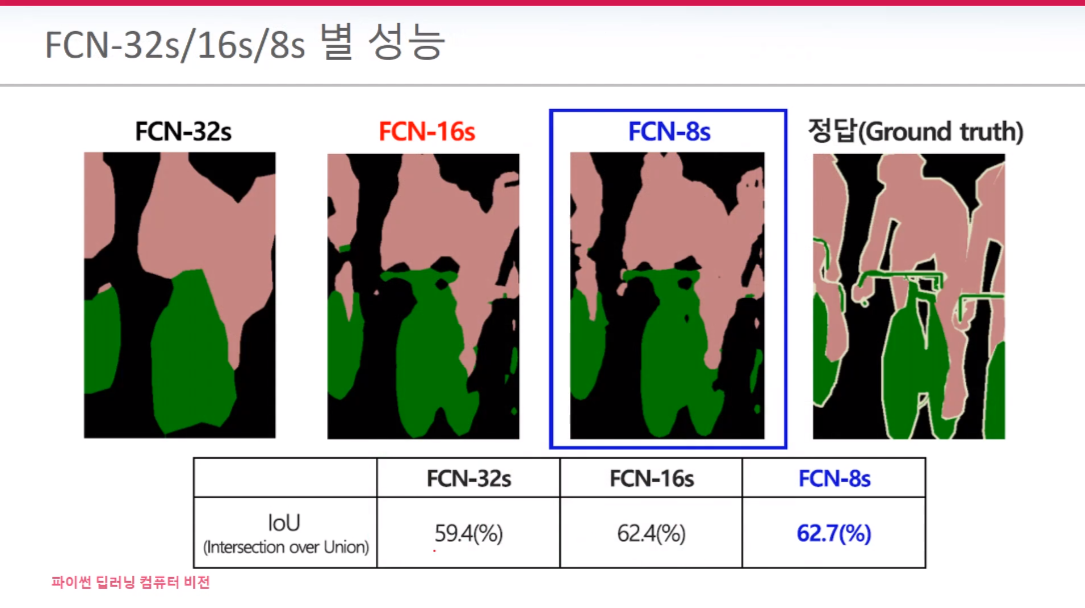
주로 FCN-8s를 사용한다.

Faster R-CNN 과정에서 BR(박스 예측) & Classification을 진행한다. 여기에 추가로 Binary Mask Prediction을 실행한다. 즉, Classification 하고 난 뒤 BB안에 있는 픽셀들이 Mask 이냐 아니냐를 결정하게 된다.

RPN은 객체가 있을만한 영역을 추천해주는 역할을 수행한다. 이를 통해 나온 FM들을 ROI Pooling을 통해 7*7 균일한 크기로 맞추게 된다. 그 후 FC layer로 들어가게 된다.

Mask RCNN은 ROI Pooling대신 ROI Align이 사용된다. 대체가 되는 이유는 ROI Pooling를 쓰게 되면 인접 pixel 공간 정보를 훼손시킵니다. input 크기가 7*7과 딱 맞아떨어지지 않고 20*20이라면 2.85***로 소수점이 나타납니다. 이때 ROI Pooling은 이 소수점을 없애버립니다. 그래서 Align을 통해 보관법으로 보완하게 됩니다. 그 후 FC을 통해 예측과 Classification을 진행합니다. Classification이 되었다면 mask 영역만 prediction을 해주면 된다.
ROI Pooling의 문제점

원본 이미지가 800*800이고, RPN 영역이 665*665이라면 VGG 통과하여 1/32로 사이즈가 줄어든다. 665/32 = 20.78인데 그냥 20으로 계산해버린다. 여기서 추가로 ROI Pooling 7*7로 나누게 되면 2.86 -> 2로 사이즈 down이 일어난다. 즉, quantized가 두 번 발생된다.

ROI영역(추천된 영역)이 3*3이고, ROI Pooling이 2*2라고 할 때, 딱 맞게 나눌 수 없기 때문에 위 빨간 박스처럼 불균등하게 네 등분을 하여 max pooling을 진행하게 된다. Masking은 픽셀 단위로 예측해야 하기 때문에 이러한 손실은 성능에 악영향을 끼칠 수밖에 없는 것이다.
ROI Align

그리드*그리드로 하게 되면 잘리는 부분이 발생한다. 따라서 짤리는 부분이 없도록 소수점까지 Align(맞추다)을 하자는 개념이다. 위 빨간 박스가 그리드 개념으로 했을 때의 경우이다. 반면 ROI-Align은 소수점까지 포함시켜서 검정 박스처럼 표기가 가능하다. 소수점까지 고려하여 맞춘 뒤 각 그리드 안에서 네 개의 포인트를 기준으로 빨간 선 처럼 사분면을 나눈다. 각 검정 포인트들은 Bilinear Interpolation을 통해 구한다. 구하는 방법은 오른쪽 그림처럼 각 거리비율을 통해 별표가 그려진 자리의 값을 구한다.
그렇게 각 검정 포인트를 구했다면 이 네개의 포인트를 가지고 maxpooling 실행한다. 쯕 빨간색 선으로 나눠진 사분면 안에서 maxpooling이 이뤄지는데 그 각각의 값은 보관법으로 구해진 값이다.

소수점이 있으면 있는 그대로 가장 오른쪽 빨간 박스처럼 그려버린다. 그 후 2*2로 나누면 네 개의 그리드가 생긴다. 각 그리드에 네개의 포인트를 보간법으로 채우고 그 안에서 max Pooling을 실행한다. 이 같은 작업을 네번 반복한다. (2*2로 나누면 네개의 그리드가 생기므로)

각 그리드가 2.97 크기로 맞춘다(녹색 그리드 부분). 녹색 박스에서 각 그리드 개별로 위에서 언급했던 사분면을 나눈 뒤 보관법을 적용하고 maxpooling을 실행하게 된다.

AP75일 때를 비교하면 약 5%가 증가했다. 따라서 보다 더 정밀한 작업에 있어서는 ROI Align이 유리하다고 볼 수 있다.

Mask RCNN의 feature Etractor는 ResNet+FPN을 사용했다.

Mask RCNN loss을 보면 Faster RCNN의 Lcls+Lbbox loss에다가 Lmask까지 포함된 걸 확인할 수 있다. Classification Loss는 Pascal VOC 라면 20개의 softmax로 계산이 된다. Smooth L1 Loss는 1보다 작으면 L2형식으로 적용하고 그게 아니면 L1형식으로 계산된다.

BB별로 Classification이 적용된다. Mask는 Person이 그려진 BB안에서 mask 인가요 아닌가요? 를 예측만 하면 된다. (픽셀마다 mask인지 예측)
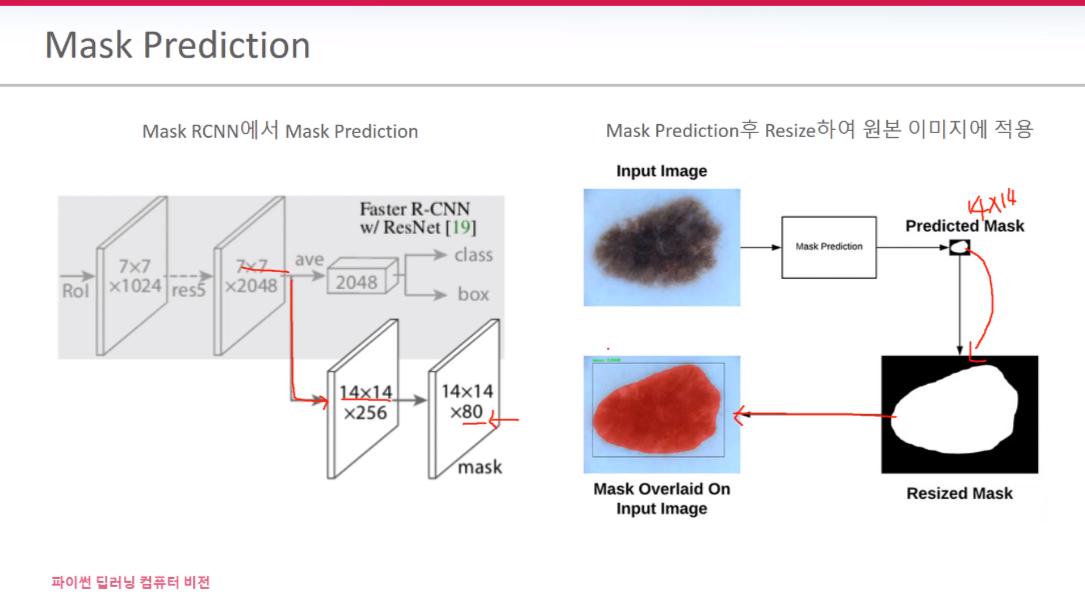
mask prediction은 class를 찾는 게 아니라 이미 특정 class로 분류가 된 BB안에서 해당되는 객체 픽셀마다 돌아다니면서 예측을 하는 것이다. 그래서 오른쪽 그림처럼 예측이 완료된 Mask를 원본 사이즈 크기로 맞춘다면 원본 이미지에 오버랩을 시키면 해당되는 객체만 색깔이 다르게 출력된다.
실습내용은 아래 링크에서 확인할수 있습니다.
2021.08.02 - [실습 note] - Mask-RCNN 실습모음(2021-07-29~02)
Mask-RCNN 실습모음(2021-07-29~02)
이론 내용은 아래 링크에서 확인할수 있습니다. 2021.07.30 - [기록 note] - 2021-07-29(Mask-RCNN_Segmentation) 2021-07-29(Mask-RCNN_Segmentation) Semantic Segmentation이란 masking 정보를 씌어서 전체 이..
ghdrldud329.tistory.com
'Data Diary' 카테고리의 다른 글
| 2021-08-09(딥러닝 수학 7_ gradient descent2 & learning late) (0) | 2021.08.09 |
|---|---|
| 2021-08-06(태블로 기본컨셉 이해하기) (0) | 2021.08.09 |
| 2021-07-26(RetinaNet & EfficientDet) (0) | 2021.07.26 |
| 2021-07-20(Yolo) (0) | 2021.07.20 |
| 2021-07-19(Single Shot Detector) (0) | 2021.07.19 |



