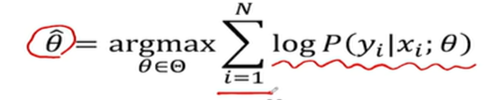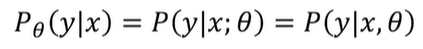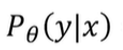차원이 높아질수록 sparse하게 분포되므로 모델링하기가 어려워진다. 예를들어 Kmean는 고차원의 데이터를 다룰 경우 성능이 저하되며 해석도 난해하게 된다. 따라서 쓸데없이 공간만 차지 하는 차원 때문에 성능 저하에 우려가 된다. 이를 해결하기 위해선 적절하게 저차원에서 실행하는 것이 옳다.
*차원 축소
PCA는 어떤 샘플이 있을 때, 이를 잘 설명하는 새로운 축을 찾아내는 방법이다. 축이 분포를 잘 설명한다는 뜻은 무엇일까를 한번 생각해보자.
위 두 조건을 만족했을 때 설명을 잘 해준다고 볼수 있다. 검은점이 기존의 분포이며 이 것들이 빨간점으로 projection된다. 이때 빨간점끼리 서로 멀어지도록 해야 한다. 두번째 조건은 projection할 때, 검은점과 검은 선 사이의 거리의 합이 최소가 되야 한다. 최소가 되어야 하는 이유는 Projection되는 거리 만큼 정보의 손실이 발생하기 때문이다.(손실 압축)
Classification는 multinomial(다항분포)를 따른다고 가정하에 CE를 통한 minimize를 진행했다. 이산부포가 아닌 연속형 분포일 경우에는 뉴럴 네트워크의 출력이 가우시안 분포를 따른다는 가정하에 MSE가 사용되어 지고 있다. 위 그림을 통해 MSE가 유도되는 위 과정을 자세히 살펴보도록 한다.
위 식은 전 시간에 배웠듯 loglikelihood이다. 해당 값들을 모두 더한값이 최대가 되는 theta값을 찾게 된다. 부연설명하자면, log그래프는 확률이 올라갈수록 영양가가 높은 정보를 얻을수 이다. 그래서 높은 값일수록 유리한데, 이를 nagative loglikelihood 바꾸게 되면 아래처럼 변형된다.
부호가 –로 변경되면서 minimize하는 theta값을 찾게 되는 것이다. Minimize는 Gradient Descent를 통해 theta를 업데이트 하게 된다.
가우시안 분포에서의 theta, 즉 파라미터는 평균과 분산이다. 위 식 표기를 빌리자면 µ=ø, σ =ψ 이다. 즉, 가우시안을따르는신경망의 theta은평균과분포라는점이다. 이말은즉슨 xi값에따라서평균과분산이변하게된다는점이다. 왜냐면식자체가조건부이기때문이다. Xi가주어질때 y의분포를나타낸것이다.
그래서 x1이 나타내는 분포와, x2가 나타내는 분포는 위 처럼 다르다.
맨 위의 가우시안 PDF 마지막 줄에 나와 있는 수식에 그대로 대입을 하면 위 식처럼 표기 할 수 있다. 이때, 시그마는 제외하고 오직 평균만을 대상으로 식을 전개한다.(이유는 모르겠음) ø을대상으로미분하게되면아래와같이나온다.
X에 따라서 변하는 theta에 Ground Truth인 y값을 빼주는 작업, 어디서 많이 봤던 형태이다. Mse와 많이 닮아 있다. 즉, 가우시안이라는 가정하에 NLL을 적용하면 mse loss를 minimize한 것과 같은 수식을 얻을 수 있다. (단, 시그마를 무시했을 경우) 최종정리를 하자면 뉴럴 네트워크는 단순히 함수를 모사하는 것이 아니라 “확률분포”를 모사하는 것이다. 왜냐면 뉴럴 네트워크 또한 확률 분포이기 때문이다.
어떻게 하면 최소의 바이트를 사용하면서 정보를 전달할수 있을까?의 연구에서 출발했다.( 정보가 높다 = 불확실성이 높다.) P(X)라는 확률분포에 –log를 붙여주면 X라는 변수에 대한 정보라고 표현 할수 있다.
확률이 1에 가깝게 올라 갈수록 값이 내려가고, 확률이 0에 가까울수록 값이 무한대로 커진다. 그래서 “영희는 내일 밥을 먹을 확률이 높다”라고 할 때, 당연히 밥을 먹으므로 밥 먹을 확률은 거의 99% 일 것이다. 이때 우리가 얻을 수 있는 값은 0에 가깝다는 것이다. 이해하기 편하게 의역을 하자면 영양가 있는 정보가 아니다. 영양가가 0이다 라는 뜻이고. 그 반대로 불확실할수록 새롭게 알게된 정보일 것이므로 영양가가 높을것이다. 그래서 값(영양가)이 커진다.
P라는 분포의 entropy = P(x)분포에서 샘플링한 x의 값에 –log 붙인 후 평균 낸 것이다.
먼저 오른쪽 분포에서 샘플링을 한다면, 가운데 값이 압도적으로 많이 뽑힐 것이다. 확률값이 모두 높은 값들이 많이 뽑힐 텐데 이 값들을 평균내면 정보량은 작아질 것이다. 아까 위에서 설명한 것처럼 확률이 올라 갈수록 영양가가 없는 정보임을 나타낸다고 하였다. 반대로 왼쪽 분포를 보면 분산이 크기 때문에 확률값이 대체로 낮게 분포되어 있다. 이를 샘플링하여 평균내면 정보량값은 커지기 때문에 H(p1)>>>>H(P3) 가 된다. 정리하면정보량이 높은 것은 대체로 분포가 넓고, 반대로 정보량이 적은 분포는 오른쪽과 같은 분포임을 알수 있다. Entropy값을 통해 분포가 어떤 모양일지 상대적으로 예상이 가능해진다.
P(x)에서 샘플링한 x들을 q(x)에 넣어서 확률을 평균 낸 값으로써, Q의 정보량의 평균을 나타낸다.
위 세개의 분포가 있다고 했을 때 x라는 샘플링을 하였다. 오른쪽 수식처럼 처음에는 Q1(x) >Q2(x) 일것이다. 하지만 –log를 취하면 부호가 반대가 되어서 Q2(x)의 값이 더 커지게 된다. 즉 –logQx(x) 평균값이 커질수록 Q2처럼 P(x)와는 다른 분포라는 것을 알수있다. 반대로 두 분포가 비슷할수록 값은 더더욱 작아진다. 이를 이용하여 딥러닝 Optimizer로 CE를 이용하여 Ground Truth의 분포와 파라미터들의 확률분포를 비슷하게 만들 수 있었던 것이다. (두 분포간의 오차를 줄이는 방향으로 GD를 적용)
위 그림에서, yt * logy^을 likelihood라고 부른다. 이 값은 위 그림의 두개 직사각형으로 설명할수 있다. Yt는 실제 실제 원핫벡터이다. 이 값 안에는 클래스에 해당하는 자리 이외값은 0으로 채워져 있다. Y^은 딥러닝이 예측한 각 클래스의 정답이 될 확률 값인데, 이 값에 log를 취한다. 이때 헷갈리지 말아야 하는 점이 있다. 구하고자하는 것은 max값을 갖는 인덱스의 확률이 아니다. 정답인 인덱스의 확률값이 얼마냐 라는 것이 최대 궁금사항이다. 이 공식이 공교롭게도? 신기하게도? 왼쪽의 CE공식과 같다. CE에서 배웠던 내용 중에 확률값이 내려갈수록 무한대 방향으로 값이 커진다고 배웠다. 즉, class라고 예측한 값이 작을수록 Loss값은 커지게 되는 것이다.
KL을 미분한 것은 CE를 미분한 것과 같다. H(p,ptheta) : CE, H(P): Entropy 이다. KL를 theta로 미분하게 되면 CE와 Entropy에도 각각 적용이 되는데, entropy는 theta가 없으므로 날라가게 된다. 따라서 딥러닝에서 GD를 위하여 theta로 미분하는 과정은 CE를 미분한 것과 같다.
KL(p||q)은 p에 대해서 q와 얼마나 다른지를 나타낸다. 왜 P에 대해서인지는 오른쪽 식에 처진 동그라미를 보면 알수있다. P(x) 확률분포에서 샘플링 했기 때문이다. 그리고 log의 성질에 의해서 분모,분자 위치가 바뀌고 마이너스를 제거한 표현식과도 동일하다.
P(x)라는 확률분포에서 x를 샘플링 했다고 가정하고 q1,q2 확률분포에 이를 아래처럼 표현해 볼수 있다.
x라는샘플링을 각 확률분포에 표시한 그림이다. 크기를 비교해보면 q1 > p(x) > q2 순이다.
각 분포에 log를 씌운 값을 비교하면 당연히 왼쪽 값이 더 클것이다.
하지만 맨 위에 공식은 마이너스가 붙어 있으므로 이를 적용해 보면 부호가 반대로 적용된다. 정리하면 P(x)와 가장 가까운 확률 분포는 q1인데 위 식에 의하면 값이 작으므로 값이 작을수록 P(x)와 비슷하다는 결론을 얻을수 있다. 반대로 값이 클수록 P(x)와는 다르다는 걸 알수있다.
D는 datset를 뜻하고, h는 가정,가설을 뜻한다. 즉, 데이터가 주어 졌을 때 그 데이터에 대한 가설을 얘기하는 것이다. MLE는 likelihood를 maximize하는 방법이다. 마찬가지로 것처럼 h값을 maximize하는 즉, 데이터가 주어 졌을 때 Posterior를 maximize할수있다. 그래서 이번 글에서는 Posterior를 maximize해서 h값을 찾는 방법에 대해서 알아본다.
X 값이 240일 때 남자일까? 여자일까?를 묻고 있다. 이때 우리는 쉽게 정답을 내린다. 240이면 대부분 여자다.이 생각이 바로 가능도 확률이다. 우리도 모르는 사이에 가능도를 재고 있었던 것이다. 아래 이미지를 통해 보도록 한다.
첫번째) y가 남자일 때 신발사이즈가 240일 확률은?
두번째) y가 여자일 때 신발사이즈가 240일 확률은?
두개의 가설중에서 우리는 무의식적으로 두번째라고 생각했을 것이다. 이러한 개념이 likelihood이다. 이러한 결과는 이미 한 가지 가정이 들어가 있는 결과다. 바로 y에 대해서 “남녀비율이 같을 때”를 가정하고 우리는 계산한 것이다.
위 글 처럼 범행 장소가 군부대였다면 성비가 맞지 않을 것이다. 100:1 비율로 남자가 압도적이라면 확률 상 범인은 남자일 것이다.
위에서 말한 것처럼, 240신발 사이즈라면 여자일 확률이 높겠지만 P(y=male)의 값이 99%로 압도적이라면 결국 남자가 범인일 확률이 클 수밖에 없다. (P(y=male) = 0.99, P(y=female)=0.01) 이 개념이 MAP이다.
P(D)는 결과에 영향을 주지않으므로 삭제한다. 맨 밑에 식을 보면 결국 likelihood에 prior를 곱한 값을 최대화 하는 과정을 말한다.
베이지안 관점의 첫번째 줄 수식을 해석하면 어떤 데이터가 주어졌을 때 theta 확률값 즉 theta 확률분포를 가장 높이는 theta 값이 theta_hat이 되는 것이다. 이렇게만 보면 우리가 늘 이렇게 해 왔던 것처럼 느껴질수도 있다. 하지만 오른쪽 수식이 우리가 해왔던 방식이다.
Freq 관점의 수식을 보면 어떤 theta가 주어졌을 때 데이터 확률분포를 가장 높이는 theta값을 찾고 있었다. 베이지안 관점에의 두번째 수식을 보면 likelihood 식이 freq관점의 수식과 같다는 것이다. 이에 대해서 제가 추측되는 것을 말해 보자면, 딥러닝 연산이 시작되면 초기 wieghts들은 랜덤값으로 정해진 후, Loss를 구하고 GD를 통해파리미터를 업데이트 한다. 그리곤 업데이트 한 파라미터를 가지고 실제 target과의 차이를 구하게 또 구한 뒤, GD를 실행한다. 이 과정이 P(D;theta)를 말하는 것이라 생각된다. 식을 좀더 풀어서 말해본다면 어떠한 theta값이 주어졌을 때 (나는 이부분을 theta의 업데이트 과정(backward-GD)이라고 생각한다) 가장 데이터 확률분포를(우리가 딥러닝을 하는 이유는 모집단에서 샘플링한 데이터를 통해 모집단에 근사 시키는 파라미터를 찾고자 하는 것이기 때문에, 모집단의 확률분포에 가장 크게 근접 시키는 theta값을 찾아야 한다) 높이는 theta값을 찾는다. (이 해석은 제 개인적인 생각이므로 틀릴 수 있다.)
그래서, 여태껏 우리가 했던 것은 위 설명대로 freq관점에서 실행했다면 이번엔 베이지안 관점을 자세히 보도록 한다.
MAP는 likelihood를 최대화 하는 동시에 P(theta)를 최대화 해줘야 한다. 이 말은 즉, theta를 maximize해줘야 한다는 것이다. 이 뜻은 딥러닝 weights 파라미터는 어떠한 확률분포를 가지고 있다는 말이 된다.
theta값에 확률 분포가 있다는 뜻은 무엇일까? 데이터를 잘 설명해 줄 수 있는, 잘 표현 해줄 수 있는 theta의 확률 분포가 있다는 것이다. 확률분포는 확률변수가 특정 값을 가질 확률이 얼마나 되는냐를 나타내는 것을 말한다.
Freq관점에서는 현재까지 모은 데이터에 대해서 잘 설명하면 되는데 베이지안 관점은 현재 데이터도 잘 설명해야 할 뿐 더러 미래에 얻게될 데이터까지도 잘 설명 해야한다. 만일 다를 경우엔 theta 확률분포에 특정한 가정을 설정해서 과적합을 피하도록 할 수 있다. 즉, 데이터를 잘 설명하는 theta 확률 분포만 알게 되면 조금 조정을 통하여 얼마든지 적잘한 확률분포를 변형 시킬수 있다는 뜻으로 해석된다(개인적 생각) 마치 코로나라ㄴ는 큰 틀의 구조가 있고, 백신을 맞은 인간이라는 예상치 못한 변수를 만났을 때, 변이 코로나를 일으켜 다시 인간을 공격할만한 최적 상태를 재 창조 하는 것처럼..?
P(x)라는 알고자 하는 확률분포에서 x,y data를 샘플링하여 모은 데이터로 파라미터를 찾고자 한다.
이때, 이 파라미터는 상황에 따라 다르다. 가우시안이라면 μ, σ 일것이고, 신경망이라면 weights, bias일것이다. 그래서위식처럼 maximum log likelihood를최대화하는 theta를찾는다. 해당식을풀이하자면 “Xi를입력으로넣고, theta라는어떠한파라미터가있었을때 yi의값은확률값이얼마인가?” 그렇게얻은확률값에 log를취하고이런과정을 N번반복하고모두더한다. 그렇게더한값들중에 theta가가장큰값을찾으면된다. 위방식은어디까지나 Ascent 방식이다.
샘플링 된 만 명의 신장 데이터가 있다고 가정해본다. 내가 알고 싶었던 것은 전국 사람들의 정규분포를 알고 싶었던 것이다. 즉, 모집단이 궁금해서 표본집단을 만개를 수집해 놓은 것이다. 이 모집단을 알기 위해서 아래 이미지처럼 평균과 분산을 랜덤하게 설정하여 각 샘플링에 대한 확률 값이 어떤지를 알아낸다
위처럼 랜덤하게 평균과 분산을 만들어 가면서 비교하던 도중
위 이미지처럼 가장 높은 확률값을 가지고 있다. 높은 확률값을 가지고 있다는 것은 빨간 점선이 길다는 것이다. 빨간 길이들의 곱을 구하면(Likelihood)세번째 분포가 가장 길다는 걸 알수있다. 그러면 이 초록색 분포가 Ground Truth 확률분포에 가장 근접한 분포가 될 것이다. 점선들의 곱 = Likelihood이다. 즉, Likelihood라는 function이 있을 때 μ, σ를입력으로넣으면 μ, σ의가우시안함수를만든다. 그후준비해둔샘플들을넣어서샘플들의 density의곱의값(길이의곱)을알아낸다.
위에서 언급된 파라미터는 μ, σ이며, 데이터를 얼마나 잘 설명하는지에 대한 기준은
Probability Density의 값이다.(클수록 잘 설명)
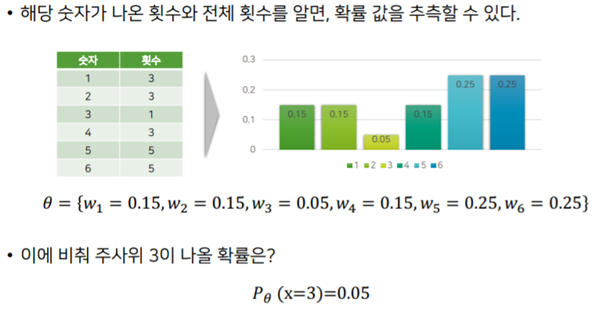
주사위를 20번 던졌을 때 위와 같이 나왔다고 가정하여 Likelihood를 구해본다.
랜덤하게 정한 μ, σ를 가지고 Theta1, Theta2를 만들었다. 가능도는 Probability Density이므로 위에서 설명한 것처럼 곱해주면 된다. 위 결과 theta1이 더 높기 때문에 theta2는 삭제하고 다른 μ, σ를 사용하여 다른 theta 분포를 계속해서 만들어 간다. 이 과정을 계속 반복해서 가능도가 가장 높은 값을 찾아 내도록 하는 것이 Maximum Likelihood Estimation이다. 이름 그대로 가능도를 최대로 하는 파라미터를 찾아내는 것이다.
곱셈으로 하면 underflow가 발생하기 때문에 log를 넣어서 곱셈을 덧셈으로 바꿔 해결 할 수 있을 뿐만 아니라 덧셈이 더 연산이 빠르다는 장점을 이용 할 수 있다.
무작정 랜덤하게 파라미터를 설정하기 보다는 Gradient Asent를 이용하여, 파라미터 Theta를 가장 최대화 하는 값을 찾으면 된다. Ascent는 Descent와 다르게 부호가 + 이다.
*진도를 더 나가기에 앞서 짚고 넘어가야 할 부분
-> theta라는 파라미터를 갖는 확률분포에서의 x의 확률값
->theta라는 파라미터를 갖는 확률분포의 x가 주어졌을 때 y의 확률값
*신경망과 MLE의 관계
어떤 확률분포 P(X)에서 샘플링한 x를 넣었을 때, c일 확률 값을 뜻하는 위 수식을 잘 숙지할 필요가 있다. 이 개념이 딥러닝과 관련이 있다.
위에서 배운 내용에서 MLE는 가능도를 최대화 하는 파라미터 μ, σ를 찾는 방법이리고 소개했다. 이는 가우시안 분포일 경우에 파라미터가 μ, σ라는 것이다. 그러면 딥러닝 신경망에서 μ, σ에 해당하는 부분은 무엇일까? 바로 위 그림처럼 weights와 bias다. 즉, 가능도를 최대화 하는 weights와 bias를 찾으면 되는 것이다.
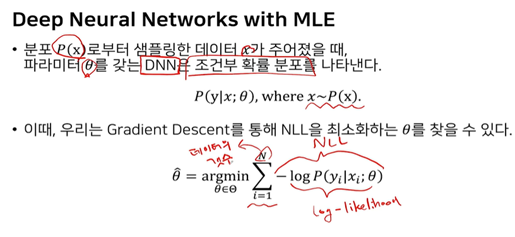
딥러닝 신경망에 위 식을 접목 시킨다면, theta라는 파라미터(weights, bias)를 갖는 확률분포에서 x라는 값이 주어졌을 때의 y의 확률 값 구한다.
여기에 log를 붙이고 summation한 값이 최대화되는 값을 Gradient Ascent를 통해 log likelihood를 구한다. 보통의 딥러닝은 Gradient Descent만을 하는데 Descent와 Ascent의 차이점은 부호뿐 이기에 Descent에서 -1을 곱해주면 최대화 문제를 최소화 문제로 접근이 가능하다. Negative는 -1를 곱했음을 의미한다. 따라서 기존에 최대화 해야 했던 문제를 -1를 곱하여 최소화 하는 문제로 바꿀 수 있는 것이다.
그래서 NLL통해 argmax가 아닌 argmin을 구하게 되면 우리가 목표로 하는 함수를 모사하는 theta(weights bias)가 되는 것이다
P(X)라는 분포에서 샘플링한 X를 f(x)에 넣으면 f(x)의 개별 값들을 알 수 있다. 이 값들을 평균 낸다.
P(x): 소문자 x이므로 분포가 아닌 어떠한 값이 주어진 상태
P(Z)라는 분포에서 샘플링한 Z가 주어졌을 때, X(대문자)라는 random variable이 x(소문자)를 가졌을 확률값에 대해서 가중평균을 한 것이다.
위 지도에서 대한민국의 면적 값을 알고 싶을 때 몬테카를로를 사용해 볼 수 있다. P(X)를 사각형 안에서 랜덤하게 유니폼 샘플링하는 함수라고 가정해본다. 그래서 위 지도에 빨간 점처럼 샘플링를 하는데, 이때 한반도에 찍힌 점과 아닌 점에 대해서 비율을 알수 있다. 예를들어 한반도 점이 20개, 그 외에 점을 100개 했을 때 20/100 = 20%이며, 이를 (w*h)*0.2계산하면 한반도의 넓이를 근사한 값이 되겠다. 만일 1억번을 점찍는다면 이 근사한 값이 더욱 정밀하게 근사하게 될것될 것이다. 즉, 몬테카를로는 샘플링 횟수가 많을수록 정밀하게 되는 approximation 방법이다