### 영상이동변환
import sys
import numpy as np
import cv2
src = cv2.imread('tekapo.bmp') #640*480
if src is None:
print('Image load failed!')
sys.exit()
# affine 변환행렬을 먼저 만들어야 한다->변환행렬을 만드는 함수는 getAffineTransform
aff= np.array([[1,0,200],[0,1,100]], dtype=np.float32) #가로 200픽셀, 세로 100픽셀 이동
# warpAffine는 변환행렬을 알고 있는경우, 결과 영상을 보기 위한 함수
dst=cv2.warpAffine(src, aff, (0,0)) #(0.0):입력영상과 동일한 크기 출력
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
전단 변환
import sys
import numpy as np
import cv2
src = cv2.imread('tekapo.bmp')
if src is None:
print('Image load failed!')
sys.exit()
#0.5: x좌표
aff = np.array([[1,0.5,0], [0,1,0]], dtype=np.float32)
'''
출력영상 크기를 (w+h*0.5,h)로 수정해야 x방향만큼 밀려나간 이미지를 볼수 있다
밀려나간 x값만큼 출력영상에 더해주면 된다
가로크기가 h*0.5만큼 밀렸다. 여기서 (0,0)으로 출력영상을 찍으면 밀린 이미지는 짤려서 보이지 않는다
입력영상은 정수형태로 있어야 하므로 int로 형변환 시킨다.
'''
h, w = src.shape[:2]
dst=cv2.warpAffine(src, aff,(w + int(h * 0.5), h))
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
### 이미지 파라미드
import sys
import numpy as np
import cv2
src = cv2.imread('cat.bmp')
if src is None:
print('Image load failed!')
sys.exit()
#(x,y,w,h)
rc = (250, 120, 200, 200) # rectangle tuple
# 원본 영상에 그리기
cpy = src.copy()
cv2.rectangle(cpy, rc, (0, 0, 255), 2) #빨간색으로 두께가 2픽셀짜리 사각형
cv2.imshow('src', cpy)
cv2.waitKey()
# 피라미드 영상에 그리기
# 이미지다운
for i in range(1, 4):
src = cv2.pyrDown(src)
cpy = src.copy()
#shift: 가로세로를 얼만큼 줄일건지 결정
#2이면 원본에 2배 줄이고, 3이면 원본에 3배
cv2.rectangle(cpy, rc, (0, 0, 255), 2, shift=i)
cv2.imshow('src', cpy)
cv2.waitKey()
cv2.destroyWindow('src') #이전src가 닫혔다가 새 src가 열리는 형태
#이미지 업
for i in range(1,4):
cpy=cv2.pyrUp(cpy) #축소된 이미지를 입력으로 받는다
cv2.imshow('src2',cpy)
cv2.waitKey()
cv2.destroyWindow()
cv2.destroyWindows()
cv2.destroyAllWindows()
회전변환_1
### 회전 변환
import sys
import math
import numpy as np
import cv2
src = cv2.imread('tekapo.bmp')
if src is None:
print('Image load failed!')
sys.exit()
#중심점이 좌측상단이다. 주로 이미지의 중심점으로 회전한다 => getRotationmatrix2D
#반시계방향으로 20도
#시계방향으로는 -20도로 음수를 붙인다.
rad = 20 * math.pi / 180 #각도(degreed) 20를 radian으로 고친 과정(단위 변경)
aff = np.array([[math.cos(rad), math.sin(rad),0],
[-math.sin(rad), math.cos(rad),0]], dtype=np.float64)
dst= cv2.warpAffine(src, aff, (0,0))
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
회전변환_2
### 회전 변환2
import sys
import numpy as np
import cv2
src = cv2.imread('tekapo.bmp')
if src is None:
print('Image load failed!')
sys.exit()
#입력영상의 가로,세로 크기를 반으로 나눈다
#순서는 가로, 세로
cp=(src.shape[1]/2, src.shape[0]/2)
'''
getRotationMatrix2D(center,angle,scale)
center : 중심점 좌표
angle: 각도 (음수는 시계방향)
크기조절 scale, 회전만 하고싶은때는 1 입력
'''
rot = cv2.getRotationMatrix2D(cp,20,1)
print(rot)
dst=cv2.warpAffine(src,rot,(0,0))
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
투시변환
### 투시 변환
import sys
import numpy as np
import cv2
src = cv2.imread('namecard.jpg')
if src is None:
print('Image load failed!')
sys.exit()
w, h = 720, 400 #출력영상 크기 정의
#[좌측상단],[우측상단],[우측하단],[좌측하단]
srcQuad = np.array([[325, 307], [760, 369], [718, 611], [231, 515]], np.float32)
#[좌상단점],[우상단점],[우하단점],[좌하단점]
dstQuad = np.array([[0, 0], [w, 0], [w, h], [0, h]], np.float32) #ndarray로 만든다
pers = cv2.getPerspectiveTransform(srcQuad, dstQuad) #pers 3*3 형태의 투시변환 행렬을 받는다
dst = cv2.warpPerspective(src, pers, (w, h))
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
리매핑
### 리매핑
import sys
import numpy as np
import cv2
'''
map1: x좌표 정보
map2: y좌표 정보
'''
src = cv2.imread('tekapo.bmp')
if src is None:
print('Image load failed!')
sys.exit()
h, w = src.shape[:2]
# indices: x,y 좌표 의 인덱스 값
# map1(x좌표)는 행 원소가 1씩 증가
# map2(y좌표)는 열 원소가 1씩 증가
map2,map1 = np.indices((h,w), dtype=np.float32)
# print("ymap2",map2)
print("xmap1",map1[0:10, 0:10])
#상하(위아래로)로 10픽셀
#여러번 파도가 칠수있도록 map1/32 입력
map2 = map2+10*np.sin(map1/32)
#BORDER_DEFAULT: 영상 바깥쪽의 가상영상을 검정색으로 칠하는게 아니라 주변 픽셀과 비슷한 같으로 대체하여 채워준다
dst = cv2.remap(src, map1, map2, cv2.INTER_CUBIC, borderMode=cv2.BORDER_DEFAULT)
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
찌그러진 영상 펴기
### 종합실습
import sys
import numpy as np
import cv2
def drawROI(img, corners): #corners= np.array([[30, 30], [30, h-30], [w-30, h-30], [w-30, 30]])
cpy = img.copy()
c1 = (192, 192, 255) #1번컬러 ==맑은 핑크색, 원
c2 = (128, 128, 255) #2번컬러 ==탁한 핑크색, 사각형 라인
for pt in corners:
#-1: 원의 내부를 채운다
cv2.circle(cpy, tuple(pt), 25, c1, -1, cv2.LINE_AA)
#사격형 표현하기
#corners은 ndarray이므로 그대로 넣어주면 에러발생
#넘길때 tuple로 묶어서 전달
cv2.line(cpy, tuple(corners[0]), tuple(corners[1]), c2, 2, cv2.LINE_AA)
cv2.line(cpy, tuple(corners[1]), tuple(corners[2]), c2, 2, cv2.LINE_AA)
cv2.line(cpy, tuple(corners[2]), tuple(corners[3]), c2, 2, cv2.LINE_AA)
cv2.line(cpy, tuple(corners[3]), tuple(corners[0]), c2, 2, cv2.LINE_AA)
#원래 이미지 img에 원과 직선들을 그려놓은 이미지 cpy를 addWeighted 이용해서 합성한다
#가중치가 있으므로 배경이 살짝 비치는 정도(중첩효과)
#addWeighted는 전체 픽셀을 계산하기 때문에 드래그 이동 시 조금 늦게 따라온다
disp = cv2.addWeighted(img, 0.3, cpy, 0.7, 0)
#return에 그냥 cpy를 넣으면 가중치가 없으므로 img가 비치지 않고 이미지가 위에 덮힌다
#하지만 빠르게 동작함, 끊김 없음
return disp #cpy
#콜백함수이므로 아래처럼 다섯개의 파리미터를 갖는다
#flags: 마우스,키보드 상태(클릭하고 있는지 등)
def onMouse(event, x, y, flags, param):
global srcQuad, dragSrc, ptOld, src # 위 5개 파라미터 이외에 사용되는 것들 불러오기
#마우스가 눌렸을때의 event
if event == cv2.EVENT_LBUTTONDOWN:
for i in range(4):
#srcQuad: 네개의 원 좌표
#25는 원의 반지름
#내가 클릭한 점이 원 안에 있다면 드래그를 시작한다
#ex) (30,30)과 현재 찍은 좌표의 "거리"가 25미만인 경우에만 드래그
if cv2.norm(srcQuad[i] - (x,y))< 25:
#드래그 시작
dragSrc[i] =True
#마우스가 움직일때마다 원이 이동하는 변위를 알기 위한 변수
#저장해 놓고 재 사용한다
ptOld= (x,y)
break
#드래그를 뗄때
if event == cv2.EVENT_LBUTTONUP:
for i in range(4):
dragSrc[i] = False #드래그 초기화
#마우스 왼쪽이 눌러 있는 상태
if event == cv2.EVENT_MOUSEMOVE:
for i in range(4):
if dragSrc[i]:#True인경우 = 어떤 점을 붙잡고 드래그 하고 있는 경우에만
dx = x - ptOld[0] #현재 좌표 - 마우스가 이전에 있던 좌표=> dx 변위를 계산
dy = y - ptOld[1] #즉 이전에 마우스에서 얼만큼 이동했는지 dx,dy를 통해 알수 있다
#dx,dy만큼 srcQuad(네개 좌표)를이동
#-=를 하게되면 드래그 하고자 하는 방향의 반대 방향으로 가게된다
srcQuad[i] += (dx, dy)
#이동한 만큼 화면에 보여주기 위해서 아래 처럼 작성
#아래 코드가 없으면 드래그,클릭 모두 작동 안함
cpy = drawROI(src, srcQuad)
cv2.imshow('img', cpy) #클릭, 드래그 한 영상
'''
ptOld를 x,y로 최신화를 안해주면 값이 크게 벌어진다.
위에서 맨 처음 ptOld값은 처음 마우스로 반지름 원 25안의 임의의 포인트이다.
이값을 53줄에 보면 ptOld 변수에 넣었다. 그리고 65줄에서는 x-ptOld[0], 마우스가 옮겨진 좌표-맨처음 딱 클릭한 원 25안의 임의의 좌표이다.
65줄에서 이동한 거리를 구하고 이값을 srcQuad에 넣어서 더해줌으로써 제대로 이동이 가능해진다
그리고 아까 65줄에서 뺄셈했던 x,y값을 넣어줘야지
다음 for문의 65줄에서 (현재 위치 - 바로 직전의 포인트) 식이 성립이 된다.
만일 계속 ptOld값을 처음 찍었던 임의의 포인트로 고정한다면 드래그를 멀리 이동할수록 아래처럼 값이 커져버린다 아래 예를들면
ptOld= (10,10)일때 드래그를 쭉 옮긴다면 20-10 -> 40-10 -> 100-10 -> 150-10 순으로 값이 10,30,90,140 갑자기 커지는데 최신화를 하면
20-10 -> 40-20 -> 100- 40 -> 150 - 100 으로 10,20,60,50 딱 이동한 거리만큼 구해진다
'''
ptOld = (x, y) #현재점으로 다시 셋팅
break
# 입력 이미지 불러오기
src = cv2.imread('scanned.jpg')
if src is None:
print('Image open failed!')
sys.exit()
# 입력 영상 크기 및 출력 영상 크기
h, w = src.shape[:2]
dw = 500 #임의로 가로 크기 지정
dh = round(dw * 297 / 210) # A4 용지 크기: 210x297cm의 비율에 맞게 계산
# 모서리 점들의 좌표, 드래그 상태 여부
#srcQuad: 내가 선택하고자 하는 모서리 네개의 ndarray
#반시계 방향
srcQuad = np.array([[30, 30], [30, h-30], [w-30, h-30], [w-30, 30]], np.float32)
#dstQuad: 반시계방향의 출력영상 네개의 모서리 위치
dstQuad = np.array([[0, 0], [0, dh-1], [dw-1, dh-1], [dw-1, 0]], np.float32)
#srcQuad 네개의 점들중에 현재 어떤 점을 드래그 하고 있는지에 대한 상태정보
dragSrc = [False, False, False, False]
# 모서리점, 사각형 그리기
disp = drawROI(src, srcQuad)
cv2.imshow('img', disp) #맨 처음 나오는 영상
cv2.setMouseCallback('img', onMouse)
while True:
key = cv2.waitKey()
if key == 13: # ENTER 키
break
elif key == 27: # ESC 키
cv2.destroyWindow('img')
sys.exit() #아예 프로그램을 종료함
#네점의 변환행렬 출력과 영상출력
# 투시 변환
pers = cv2.getPerspectiveTransform(srcQuad, dstQuad) # 새로운 4개 점이 결정된 변환행렬
print(pers)
dst = cv2.warpPerspective(src, pers, (dw, dh), flags=cv2.INTER_CUBIC)
# 결과 영상 출력
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
#import
from matplotlib import font_manager, rc
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
import platform
#window 폰트 설정
font_name=font_manager.FontProperties(fname='c:/Windows/Fonts/malgun.ttf').get_name()
rc('font', family=font_name)
#그래프의 마이너스 표시가능 설정
matplotlib.rcParams['axes.unicode_minus']=False
1.EDA(탐색적 데이터 분석)
프리시즌 살펴보기
#프리시즌 데이터로드
preseason_df=pd.read_csv('D:/dacon/KBO 타자 OPS 예측/Pre_Season_Batter.csv')
#정규시즌 데이터로드
regular_season_df=pd.read_csv('D:/dacon/KBO 타자 OPS 예측/Regular_Season_Batter.csv')
#데이터크기 확인
print(preseason_df.shape)
#데이터 상단 출력
display(preseason_df.head())
#데이터 기초통계량 확인
display(preseason_df.describe())
#데이터 시각화
preseason_df.hist(figsize=(10,9))
plt.tight_layout() # 그래프 간격 설정
plt.show()
#정규시즌 데이터에서 2002년 이후의 연도별기록된 선수의 수
regular_count=regular_season_df.groupby('year')['batter_name'].count().rename('regular')
#프리시즌 데이터에서 2002년 이후의 연도별기록된 선수의 수
preseason_count=preseason_df.groupby('year')['batter_name'].count().rename('preseason')
#합치기
pd.concat([regular_count,preseason_count, np.round(preseason_count/regular_count,2).rename('ratio')],axis=1).transpose().loc[:,2002:]
#타자의 이름과 연도를 이용해 새로운 인덱스를 생성
regular_season_df['new_idx']=regular_season_df['batter_name']+regular_season_df['year'].apply(str)
preseason_df['new_idx']=preseason_df['batter_name']+preseason_df['year'].apply(str)
#새로운 인덱스의 교집합
intersection_idx=list(set(regular_season_df['new_idx']).intersection(preseason_df['new_idx']))
#ket_point: intersaction을 활용한 교집합
#교집합에 존재하는 데이터만 불러오기
regular_season_new=regular_season_df.loc[regular_season_df['new_idx'].apply(lambda x:x in intersection_idx)]
regular_season_new=regular_season_new.sort_values(by='new_idx').reset_index(drop=True)
#비교를 위한 인덱스 정렬
preseason_new=preseason_df.loc[preseason_df['new_idx'].apply(lambda x:x in intersection_idx)]
preseason_new=preseason_new.sort_values(by='new_idx').reset_index(drop=True)
#검정코드
print(preseason_new.shape, preseason_new.shape)
sum(preseason_new['new_idx']==regular_season_new['new_idx'])
(1358, 30) (1358, 30)
1358
intersaction을 활용한 교집합+set을 이용한 중복제거(두시즌 모두 참여한 선수 추출)
#2000년도 이전의 변동폭이 크기 때문에 좀더 자세히 살펴본다
pd.crosstab(regular_season_df['year'], 'count').T
#2000년 이전의 데이터 수가 작아서 변동성이 컸음을 알수있음
#팀별/연도별 OPS
#연도별 팀의 OPS 중앙값 계산
med_OPS=regular_season_df.pivot_table(index=['team'], columns='year', values="OPS", aggfunc="median")
#2005년 이후에 결측치가 존재 하지 않은 팀만 확인
team_idx=med_OPS.loc[:,2005:].isna().sum(axis=1)<=0
plt.plot(med_OPS.loc[team_idx,2005:].T)
plt.legend(med_OPS.loc[team_idx,2005:].T.columns, loc='center left', bbox_to_anchor=(1,0.5)) #그래프 범례를 그래프 밖에 위치
plt.title('팀별 성적')
plt.show()
team_idx=med_OPS.loc[:,2005:].isna().sum(axis=1)<=0 결측치가 있는걸 제거 하는 코드
키와 몸무게가 성적과 관련이 있는지 확인
import re
regular_season_df['weight']=regular_season_df['height/weight'].apply(lambda x: int(re.findall('\d+', x.split('/')[1])[0]) if pd.notnull(x) else x )
regular_season_df['height']=regular_season_df['height/weight'].apply(lambda x: int(re.findall('\d+', x.split('/')[0])[0]) if pd.notnull(x) else x )
print(regular_season_df['height/weight'][0], regular_season_df['weight'][0],regular_season_df['height'][0])
177cm/93kg 93.0 177.0
선수들의 포지션을 통해서 왼손잡이,오른손잡이를 알아내고 성적과 상관관계를 알아내는 추론과정
plt.figure(figsize=(15,5))
plt.subplot(1,2,1)
ax= sns.boxplot(x='pos', y='OPS', data=regular_season_df,
showfliers=False) # 박스 범위 벗어난 아웃라이어 표시하지 않기
#position별 ops 중앙값
median= regular_season_df.groupby('pos')['OPS'].median().to_dict() #{'내야수': 0.706, '외야수': 0.7190000000000001, '포수': 0.639}
#position 별 관측치 수 -> 그래프에 넣을 값
nobs=regular_season_df['pos'].value_counts().to_dict() #{'내야수': 827, '외야수': 622, '포수': 203}
#키 값을 'n:값' 형식으로 변환하는 코드
for key in nobs: nobs[key] = "n:"+str(nobs[key]) #for key의 keyr가 아닌 다른 텍스트를 넣으면 n:n:n:값 형식으로 형태가 이상해짐
#그래프의 Xticks text 값 얻기
xticks_labels = [item.get_text() for item in ax.get_xticklabels()] #['내야수', '외야수', '포수']
#ax안에 텍스트 위치와 내용 넣기
for label in ax.get_xticklabels(): #x축 인자 즉, 내야수,외야수, 포수를 차례대로 label 넣는다
# print(xticks_labels.index(label.get_text())) # 0,1,2 차례대로
# print(label.get_text()) #내야수 외야수 포수
ax.text(xticks_labels.index(label.get_text()), #x의 위치--> 숫자로 인덱스가 출력
median[label.get_text()]+0.03, #y의 위치
nobs[label.get_text()], #들어갈 텍스트 내용
horizontalalignment='center', size='large', color='w', weight='semibold')
print(label.get_text())
ax.set_title('포지션별 OPS')
plt.subplot(1,2,2)
ax= sns.boxplot(x='hit_way', y='OPS', data=regular_season_df, showfliers=False)
#타자 방향별 OPS 중앙값
median=regular_season_df.groupby('hit_way')['OPS'].median().to_dict()
#타자 방향 관측치 수
nobs = regular_season_df['hit_way'].value_counts().to_dict()
#키 값을 'n:값' 형식으로 변환
for key in nobs: nobs[key] = 'n:'+str(nobs[key])
#그래프의 xticks text 값 얻기
xticks_labels=[item.get_text() for item in ax.get_xticklabels()] #hit_way의 인덱스가 리스트 형식으로 묶인다
#tick은 tick의 위치, label은 그에 해당하는 text 값
for label in ax.get_xticklabels():
ax.text(
xticks_labels.index(label.get_text()),
median[label.get_text()]+0.03,
nobs[label.get_text()], horizontalalignment='center', size= 'large',
color='w', weight='semibold')
ax.set_title('타석방향별 OPS')
plt.show()
to_dict과 그래프 적용하는 과정
xticks_labels.index(label.get_text(): x축 index 추출 과정
커리어 변수를 이용하여 외/내국인 차이를 탐색
#career를 split
foreign_country = regular_season_df['career'].apply(lambda x:x.replace('-','').split(' ')[0])
#외국인만 추출
foreign_country_list= list(set(foreign_country.apply(lambda x:np.nan if '초' in x else x))) #초가 있으면 nan으로 처리하고 그게 아니라면 x출력
#nan이 1개인 이유 : set함수
#결측치 처리
foreign_country_list = [x for x in foreign_country_list if str(x) != 'nan']
foreign_country_list
['쿠바', '도미니카삼성', '캐나다', '도미니카', '네덜란드', '미국']
regular_season_df['country']=foreign_country
regular_season_df['country']=regular_season_df['country'].apply(lambda x: x if pd.isnull(x) else ('foreign' if x in foreign_country_list else 'korean'))
regular_season_df[['country']].head()
plt.figure(figsize=(15,5))
ax= sns.boxplot(x='country', y='OPS', data=regular_season_df, showfliers=False)
#국적별 OPS 중앙값 dict
median= regular_season_df.groupby(['country'])['OPS'].median().to_dict()
#내외국인 관측치 수
nobs = regular_season_df['country'].value_counts().to_dict()
#키 값을 n:값 형태로 변경
for key in nobs : nobs[key] = 'n:'+str(nobs[key]) #['foreign', 'korean']
#그래프의 Xticks text 값 얻기
xticks_labels=[item.get_text() for item in ax.get_xticklabels()]
for label in ax.get_xticklabels():
ax.text(
xticks_labels.index(label.get_text()),
median[label.get_text()]+0.03,
nobs[label.get_text()],
horizontalalignment='center', size='large', color='w', weight='semibold')
ax.set_title('국적별 OPS')
plt.show()
#결측치라면 그대로 0으로 두고, 만원이 포함된다면 숫자만 뽑아서 초봉으로 넣어준다.
#그외 만원 단위가 아닌 초봉은 결측치로 처리한다.
regular_season_df['starting_salary']=regular_season_df['starting_salary'].apply(lambda x:x if pd.isnull(x) else(int(re.findall('\d+',x)[0]) if '만원' in x else np.nan))
plt.figure(figsize=(15,5))
plt.subplot(1,2,1)
b=sns.distplot(regular_season_df['starting_salary'].\
loc[regular_season_df['starting_salary'].notnull()], hist=True)
b.set_xlabel('staring salary', fontsize=12)
b.set_title('초봉의 분포', fontsize=20)
plt.subplot(1,2,2)
correlation=regular_season_df['starting_salary'].corr(regular_season_df['OPS'])
b=sns.scatterplot(x=regular_season_df['starting_salary'], y=regular_season_df['OPS'])
b.axes.set_title('correlation(상관계수):'+str(np.round(correlation,2)), fontsize=20)
b.set_ylabel('정규시즌 OPS:',fontsize=12)
b.set_xlabel("초봉",fontsize=12)
plt.show()
#날짜(date)를 '.'을 기준으로 나누고 첫 번째 값을 월(month)로 지정
day_by_day_df['month']=day_by_day_df['date'].apply(lambda x:str(x).split('.')[0]) #숫자는 split 안됨, str로 변경 후 사용
#각 연도의 월별 평균 누적 타율(avg2) 계산
agg_df= day_by_day_df.groupby(['year','month']).mean().reset_index()
agg_df
#피벗 데이털로 재구성하기
agg_df=day_by_day_df.pivot_table(index='month', columns='year', values='avg2')
agg_df
date변수를 월을 추출해서 월별 평균 타율을 추출과정
#그래프의 간소화를 위해 결측치가 있는 3월과 10월제외한다.
display(agg_df.iloc[2:,10:])
plt.plot(agg_df.iloc[2:,10:]) #2011~2018년도
plt.legend(agg_df.iloc[2:,10:].columns, loc='center left', bbox_to_anchor=(1,0.5)) #범례 그래프 밖에 위치
plt.title('연도별 평균 타율')
plt.show()
데이터 전처리
결측치 처리 및 데이터 오류 처리
# 수치형 타입의 변수 저장
numberics =['int16','int32','int64','float16','float32','float64']
num_cols=regular_season_df.select_dtypes(include=numberics).columns #columns을 붙여야 열 이름만 추출
수치형 타입을 이용해서 해당되는 데이터를 찾아내는 과정
select_dtypes
regular_season_df.loc[regular_season_df[num_cols].isna().sum(axis=1)>0 , num_cols].head()
#ex 0번 인덱스에 하나라도 결측치가 있으면 num_cols와 매칭하여 보여준다.
#0번 인덱스에 결측치가 있을때 그 결측치가 num_cols중에 발생한 것인지 확인하기 위해서 필요한 코드
결측치 여부를 부등호로 처리
#수치형 변수에 포함되는 데이터 타입 선정
numberics =['int16','int32','int64','float16','float32','float64']
#정규시즌 데이터에서 결측치를 0으로 채우기
regular_season_df[regular_season_df.select_dtypes(include=numberics).columns]=regular_season_df[regular_season_df.select_dtypes(include=numberics).columns].fillna(0)
#일별 데이터에서 결측치를 0으로 채우기
day_by_day_df[day_by_day_df.select_dtypes(include=numberics).columns]=day_by_day_df[day_by_day_df.select_dtypes(include=numberics).columns].fillna(0)
#프리시즌 데이터에서 결측치를 0으로 채우기
preseason_df[preseason_df.select_dtypes(include=numberics).columns]=preseason_df[preseason_df.select_dtypes(include=numberics).columns].fillna(0)
#수치형 변수의 결측치를 다루기 전에 먼저 결측치의 현황을 파악 후 결측치 처리 방법을 정해야 한다
not_num_cols=[x for x in regular_season_df.columns if x not in num_cols ]
#수치형이 아닌 변수 중 결측치가 하나라도 존재하는 행 출력
regular_season_df.loc[regular_season_df[not_num_cols].isna().sum(axis=1)>0, not_num_cols].head()
#결측치 해당 변수는 분석에 사용안하므로 결측치 처리 안함
#잘못된 결측치 데이터를 삭제
#삭제할 데이터 추출
drop_index= regular_season_df.loc[
#안타가 0개 이상이면서 장타율이 0인 경우
((regular_season_df['H']>0) & (regular_season_df['SLG']>0))|
#안타가 0개 이상 혹은 볼넷이 0개 이상 혹은 몸에 맞은 볼이 0개 이상이면서 출루율이 0인 경우
(((regular_season_df['H']>0)|
(regular_season_df['BB']>0)|
(regular_season_df['HBP']>0))&
(regular_season_df['OBP']==0))
].index
#데이터 삭제
regular_season_df=regular_season_df.drop(drop_index).reset_index(drop=True)
#시간변수를 생성하느 함수 정의
def lag_function(df,var_name, past):
# df = 시간변수를 생성할 데이터 프레임
# var_name= 시간변수 생성의 대상이 되는 변수 이름
# past= 몇 년 전의 성적을 생성할지 결정(정수형)
df.reset_index(drop=True, inplace=True)
#시간변수 생성
df['lag'+str(past)+'_'+var_name] = np.nan #결측치로 채워 넣어 놓는다
df['lag'+str(past)+'_'+'AB'] = np.nan
for col in ['AB',var_name]:
for i in range(0, (max(df.index)+1)):
val=df.loc[(df['batter_name']==df['batter_name'][i])& #이름이 가르시아 이면서
(df['year']==df['year'][i]-past),col] #년도는 i년도
#과거 기록이 결측치가 아니라면 값을 넣기
if len(val)!=0:
df.loc[i,'lag'+str(past)+'_'+col]=val.iloc[0] #i번째 행에 삽입
#30타수 미만 결측치 처리
df.loc[df['lag'+str(past)+'_'+'AB']<30,
'lag'+str(past)+'_'+var_name]=np.nan #var_name 행의 존재하는 30미만은 제거하고
df.drop('lag'+str(past)+'_'+'AB', axis=1, inplace=True) #AB열을 제거 하여 var_name만 남김
return df
과거 시간을 for문으로 채우기 전에 결측치로 채워 넣은 점-> 과거 기록이 없으면 결측치로 채우기 위함
# 상관관계를 탐색할 변수 선택
numberics =['int16','int32','int64','float16','float32','float64']
numberics_cols=list(regular_season_df.select_dtypes(include=numberics).drop(['batter_id','year','OPS','SLG'], axis=1).columns)
regular_season_temp=regular_season_df[numberics_cols+['year','batter_name']].copy()
regular_season_temp= regular_season_temp.loc[regular_season_temp['AB']>=30]
# #시간변수 생성 함수를 통한 지표별 1년 전 성적 추출
for col in numberics_cols:
regular_season_temp=lag_function(regular_season_temp,col ,1)
numberics_cols.remove('OBP')
regular_season_temp.drop(numberics_cols, axis=1, inplace=True)
#상관관계 도출
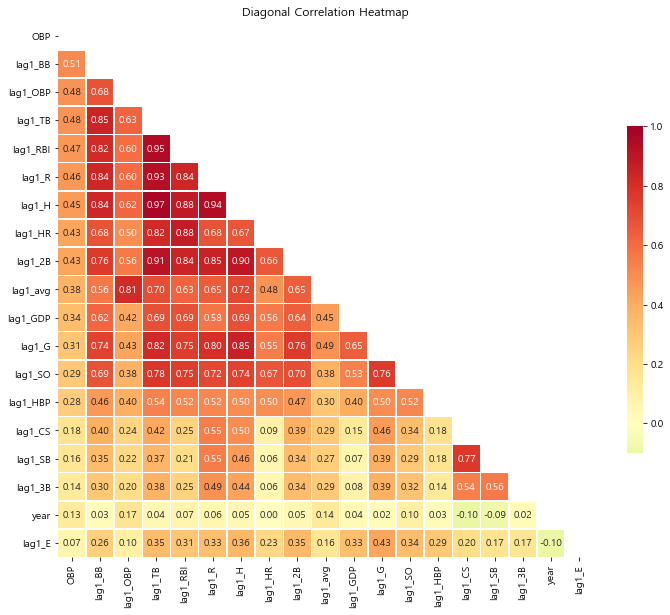
corr_matrix= regular_season_temp.corr()
corr_matrix= corr_matrix.sort_values(by='OBP', axis=0, ascending=False)
corr_matrix= corr_matrix[corr_matrix.index]
#상관관계의 시각적 표현
f, ax = plt.subplots(figsize=(12,12))
corr= regular_season_temp.select_dtypes(exclude=['object','bool']).corr()
#대각 행렬을 기준으로 한쪽만 설정
mask= np.zeros_like(corr_matrix, dtype=np.bool)
mask[np.triu_indices_from(mask)]=True
g= sns.heatmap(corr_matrix, cmap='RdYlGn_r', vmax=1, mask=mask, center=0, annot=True, fmt='.2f', square=True, linewidths=.5, cbar_kws={'shrink':.5})
plt.title('Diagonal Correlation Heatmap')
#희생 플라이 구하기
#OBP(출루율) 계산 공식 이용하여 SF(희생 플라이) 계산 > (H+BB+HBP)/OBP-(AB+BB+HBP)
regular_season_df['SF']= regular_season_df[['H','BB','HBP']].sum(axis=1)/ regular_season_df['OBP']-\
regular_season_df[['AB','BB','HBP']].sum(axis=1)
regular_season_df['SF'].fillna(0, inplace=True) #결측치 채우기
regular_season_df['SF']=regular_season_df['SF'].apply(lambda x: round(x,0))
#한 타수당 평균 희생 플라이 계산 후 필요한 것만 추출
#regular_season_df는 각 연도별 전체 데이터이다.
#이를통해서 한 타수당 평균 플라이 계산 후 일일 데이터에서 상반기데이터만 취하여 희생플라이 계산 -> 선수 별 상반기 출루율 계산
regular_season_df['SF_1']=regular_season_df['SF']/regular_season_df['AB']
regular_season_df_SF=regular_season_df[['batter_name','year','SF_1']]
regular_season_df_SF
#day_by_day_df에서 연도별 선수의 시즌 상반기 출루율과 관련된 성적 합 구하기
sum_hf_yr_OBP=day_by_day_df.loc[day_by_day_df['date']<=7.18].groupby(['batter_name','year'])['AB','H','BB','HBP'].sum().reset_index()
#day_by_day_df와 regular_season에서 구한 희생 플라이 관련 데이터 합치기
sum_hf_yr_OBP=sum_hf_yr_OBP.merge(regular_season_df_SF, how='left', on=['batter_name','year'])
#선수별 상반기 희생 플라이 수 계산
sum_hf_yr_OBP['SF']=(sum_hf_yr_OBP['SF_1']*sum_hf_yr_OBP['AB']).apply(lambda x:round(x,0))
sum_hf_yr_OBP.drop('SF_1', axis=1, inplace=True) #SF_1 삭제
#선수별 상반기 OBP(출루율)계산
sum_hf_yr_OBP['OBP']=sum_hf_yr_OBP[['H','BB','HBP']].sum(axis=1)/ sum_hf_yr_OBP[['AB','BB','HBP','SF']].sum(axis=1)
#OBP 결측치를 0으로 처리
sum_hf_yr_OBP['OBP'].fillna(0,inplace=True)
#분석에 필요하지 않은 열 제거
sum_hf_yr_OBP = sum_hf_yr_OBP[['batter_name','year','AB','OBP']]
sum_hf_yr_OBP
추가 변수 생성
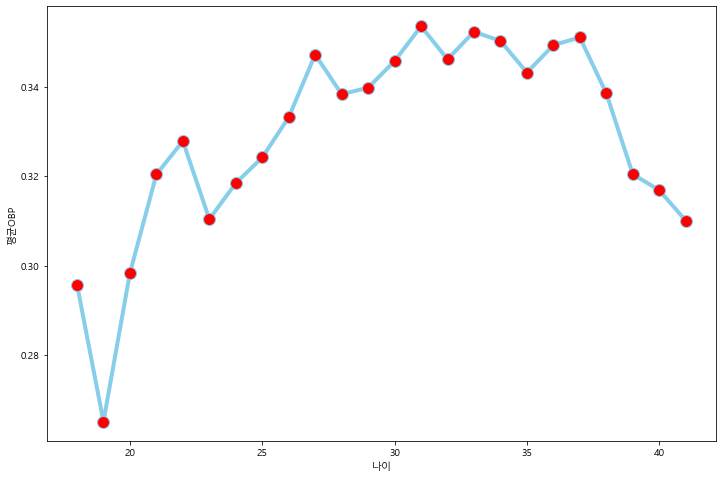
#나이 변수 생성
regular_season_df['age']=regular_season_df['year']-regular_season_df['year_born'].apply(lambda x:int(x[:4]))
#나이,평균 출루율,출루율 중앙값으로 구성된 데이터프레임 구축
temp_df=regular_season_df.loc[regular_season_df['AB']>=30].groupby('age').agg({'OBP':['mean','median']}).reset_index()
temp_df.columns= temp_df.columns.droplevel()
temp_df.columns=['age','mean_OBP','median_OBP']
#나이에 따른 출루율 시각화
plt.figure(figsize=(12,8))
plt.plot('age','mean_OBP', data=temp_df, marker='o', markerfacecolor='red', markersize=12, color='skyblue', linewidth=4)
plt.ylabel('평균OBP')
plt.xlabel('나이')
plt.show()
#나이를 포함한 변수 선택
sum_hf_yr_OBP=sum_hf_yr_OBP.merge(regular_season_df[['batter_name','year','age']],
how='left',on=['batter_name','year'])
#총 3년 전 성적까지 변수를 생성
sum_hf_yr_OBP= lag_function(sum_hf_yr_OBP,'OBP',1)
sum_hf_yr_OBP= lag_function(sum_hf_yr_OBP,'OBP',2)
sum_hf_yr_OBP= lag_function(sum_hf_yr_OBP,'OBP',3)
sum_hf_yr_OBP
#1. 선수별 OBP 평균
#SF = (H+BB+HBP)/OBP-(AB+BB+HBP)
#OBP = (H+BB+HBP) / (AB+BB+HBP+SF)
player_OBP_mean= regular_season_df.loc[regular_season_df['AB']>=30].groupby('batter_name')['AB','H','BB','HBP','SF'].sum().reset_index()
player_OBP_mean['mean_OBP']=player_OBP_mean[['H','BB','HBP']].sum(axis=1)/player_OBP_mean[['AB','BB','HBP','SF']].sum(axis=1)
#2. 시즌별 OBP평균
season_OBP_mean=regular_season_df.loc[regular_season_df['AB']>=30].groupby('year')['AB','H','BB','HBP','SF'].sum().reset_index()
season_OBP_mean['mean_OBP']=season_OBP_mean[['H','BB','HBP']].sum(axis=1)/season_OBP_mean[['AB','BB','HBP','SF']].sum(axis=1)
season_OBP_mean=season_OBP_mean[['year','mean_OBP']]
##player_OBP_mean(선수별 평균) 열 추가
sum_hf_yr_OBP=sum_hf_yr_OBP.merge(player_OBP_mean[['batter_name','mean_OBP']], how='left', on='batter_name')
#선수평균의 성적이 결측치이면 데이터에서 제거
sum_hf_yr_OBP=sum_hf_yr_OBP.loc[~sum_hf_yr_OBP['mean_OBP'].isna()].reset_index(drop=True) #~하면 False 가 True로 반전됨, 평균값이 없는 선수는 제외 시키기위함?
sum_hf_yr_OBP
#결측치 처리하는 함수 정의
def lag_na_fill(data_set,var_name,past,season_var_mean_data):
#data_set: 이용할 데이터 셋
#var_name: 시간변수르 만들 변수 이름
#season_var_mean_data: season별로 var_name의 평균을 구한 데이터
for i in range(0, len(data_set)):
if np.isnan(data_set['lag'+str(past)+'_'+var_name][i]): # 결측치가 존재하면 True를 반환
#선수별 var_name 평균 + #시즌별 var_name평균
data_set.loc[i,'lag'+str(past)+'_'+var_name]=(data_set.loc[i,'mean_'+var_name]+season_var_mean_data.loc[season_var_mean_data['year']==\
(data_set['year'][i]-past),'mean_'+var_name].iloc[0])/2
return data_set
#생성한 함수를 이용해 결측치 처리
sum_hf_yr_OBP=lag_na_fill(sum_hf_yr_OBP,'OBP',1,season_OBP_mean) #1년 전 성적 대체
sum_hf_yr_OBP=lag_na_fill(sum_hf_yr_OBP,'OBP',2,season_OBP_mean) #2년 전 성적 대체
sum_hf_yr_OBP=lag_na_fill(sum_hf_yr_OBP,'OBP',3,season_OBP_mean) #3년 전 성적 대체
sum_hf_yr_OBP
과거 성적데이터를 쓴다는 인사이트와 구현하는 코드
함수를 정의하는 과정 방법
SLG 데이터 처리
#상관관계를 탐색할 변수 선택
numberics_cols=list(regular_season_df.select_dtypes(include=numberics).drop(['batter_id','year','OPS','OBP'], axis=1).columns)
regular_season_temp = regular_season_df[numberics_cols+['year','batter_name']].copy()
regular_season_temp=regular_season_temp.loc[regular_season_temp['AB']>=30]
#시간변수 생성 함수를 통한 지표별 1년 전 성적추출
for col in numberics_cols:
regular_season_temp=lag_function(regular_season_temp,col,1)
numberics_cols.remove('SLG') #SLG를 상관관계표에서 비교해야 하므로 미리 삭제목록에서 제외시킨다
regular_season_temp.drop(numberics_cols, axis=1,inplace=True)
#상관관계 도출
corr_matrix=regular_season_temp.corr()
corr_matrix=corr_matrix.sort_values(by='SLG', axis=0, ascending=False)
corr_matrix=corr_matrix[corr_matrix.index]
#상관관계 시각적 표현
f,ax = plt.subplots(figsize=(12,12)) #fig 사이즈, ax : axes 생성된 그래프 낱낱개
corr=regular_season_temp.select_dtypes(exclude=['object','bool']).corr()
#대각 행렬을 기준으로 한쪽만 설정
mask= np.zeros_like(corr_matrix, dtype=np.bool)
mask[np.triu_indices_from(mask)]=True
g= sns.heatmap(corr_matrix, cmap='RdYlGn_r', vmax=1, mask=mask, center=0, annot=True, fmt='.2f', square=True, linewidths=.5, cbar_kws={'shrink':.5})
plt.title('Diagonal Correlation Heatmap')
SLG 예측에 필요한 변수를 파악하기 위한 상관성
#day_by_day_df에서 연도별 선수의 시즌 상반기 장타율과 관련된 성적 합 구하기
sum_hf_yr_SLG=day_by_day_df.loc[day_by_day_df['date']<=7.18].groupby(['batter_name','year'])['AB','H','2B','3B','HR'].sum().reset_index()
#상반기 장타율 계산 #sum(axis=1) :행 별로 더해진다#
sum_hf_yr_SLG['SLG']=(sum_hf_yr_SLG['H']-sum_hf_yr_SLG[['2B','3B','HR']].sum(axis=1)+sum_hf_yr_SLG['2B']*2+sum_hf_yr_SLG['3B']*3+\
sum_hf_yr_SLG['HR']*4)/sum_hf_yr_SLG['AB']
#SLG결측치를 0으로 처리
sum_hf_yr_SLG['SLG'].fillna(0, inplace=True)
#필요한 칼럼만 불러오고 나이계산
sum_hf_yr_SLG=sum_hf_yr_SLG[['batter_name','year','AB','SLG']]
sum_hf_yr_SLG=sum_hf_yr_SLG.merge(regular_season_df[['age','batter_name','year']], how='left', on=['batter_name','year'] )
sum_hf_yr_SLG.head()
# 총 3년 전 성적까지 변수를 생성
sum_hf_yr_SLG=lag_function(sum_hf_yr_SLG,'SLG',1)
sum_hf_yr_SLG=lag_function(sum_hf_yr_SLG,'SLG',2)
sum_hf_yr_SLG=lag_function(sum_hf_yr_SLG,'SLG',3)
display(sum_hf_yr_SLG.head())
#전체 데이터에서 결측치가 차지하는 비율보기
round(sum_hf_yr_SLG[['lag1_SLG','lag2_SLG','lag3_SLG']].isna().sum()/sum_hf_yr_SLG.shape[0],2)
#결측치를 시즌성적,선수의 평균 성적을 이용해 결측치 처리
#선수별 SLG평균 데이터(player_SLG_mean) 생성
player_SLG_mean= regular_season_df.loc[regular_season_df['AB']>=30].groupby('batter_name')['AB','H','2B','3B','HR'].sum().reset_index()
player_SLG_mean['mean_SLG']= (player_SLG_mean['H']-player_SLG_mean[['2B','3B','HR']].sum(axis=1)+player_SLG_mean['2B']*2+player_SLG_mean['3B']*3+\
player_SLG_mean['HR']*4)/player_SLG_mean['AB']
#시즌별 SLG 평균 데이터(season_SLG_mean) 생성
season_SLG_mean=regular_season_df.loc[regular_season_df['AB']>=30].groupby('year')['AB','H','2B','3B','HR'].sum().reset_index()
season_SLG_mean['mean_SLG']=(season_SLG_mean['H']-season_SLG_mean[['2B','3B','HR']].sum(axis=1)+season_SLG_mean['2B']*2+season_SLG_mean['3B']*3+\
season_SLG_mean['HR']*4)/season_SLG_mean['AB']
#선수 평균의 SLG(player_SLG_mean)를 새로운 변수에 더한다
sum_hf_yr_SLG=sum_hf_yr_SLG.merge(player_SLG_mean[['batter_name','mean_SLG']], how='left', on='batter_name')
#선수 평균의 성적이 결측치이면 데이터에서 제거
sum_hf_yr_SLG=sum_hf_yr_SLG.loc[~sum_hf_yr_SLG['mean_SLG'].isna()].reset_index(drop=True) #mean_SLG가 있는 것만 추출해서 인덱스 정리
sum_hf_yr_SLG
#결측치 처리
sum_hf_yr_SLG=lag_na_fill(sum_hf_yr_SLG,'SLG',1, season_SLG_mean) #1년전 성적 대체
sum_hf_yr_SLG=lag_na_fill(sum_hf_yr_SLG,'SLG',2, season_SLG_mean) #2년전 성적 대체
sum_hf_yr_SLG=lag_na_fill(sum_hf_yr_SLG,'SLG',3, season_SLG_mean) #3년전 성적 대체
display(sum_hf_yr_SLG.head())
round(sum_hf_yr_SLG[['lag1_SLG','lag2_SLG','lag3_SLG']].isna().sum()/sum_hf_yr_SLG.shape[0],2)
모델구축과 검증
lasso,RIdge
#30태수 이상의 데이터만 학습
sum_hf_yr_OBP=sum_hf_yr_OBP.loc[sum_hf_yr_OBP['AB']>=30]
sum_hf_yr_SLG=sum_hf_yr_SLG.loc[sum_hf_yr_SLG['AB']>=30]
#2018년 데이터를 test 데이터로, 2018 이전은 train 데이터로 나눈다
OBP_train= sum_hf_yr_OBP.loc[sum_hf_yr_OBP['year']!=2018]
OBP_test= sum_hf_yr_OBP.loc[sum_hf_yr_OBP['year']==2018]
SLG_train= sum_hf_yr_SLG.loc[sum_hf_yr_SLG['year']!=2018]
SLG_test= sum_hf_yr_SLG.loc[sum_hf_yr_SLG['year']==2018]
print(OBP_train.shape,OBP_test.shape,SLG_train.shape,SLG_test.shape)
(872, 9) (150, 9) (872, 9) (150, 9)
#랏지와 라소 선형모델
from sklearn.linear_model import Ridge,Lasso
from sklearn.model_selection import GridSearchCV
#log 단위(1e+01)로 1.e-04 ~1.e+01 사이의 구간에 대해 parameter를 탐색한다
lasso_params={'alpha':np.logspace(-4,1,6)} #array([1.e-04, 1.e-03, 1.e-02, 1.e-01, 1.e+00, 1.e+01])
ridge_params={'alpha':np.logspace(-4,1,6)}
#GridSeachCV를 이용하여 dict에 lasso,Ridge OBP 모델을 저장한다.
OBP_linear_models={
'Lasso':GridSearchCV(Lasso(), param_grid=lasso_params).fit(OBP_train.iloc[:,-5:],OBP_train['OBP']).best_estimator_,
'Ridge':GridSearchCV(Ridge(), param_grid=lasso_params).fit(OBP_train.iloc[:,-5:],OBP_train['OBP']).best_estimator_,
}
#GridSeachCV를 이용하여 dict에 lasso,Rigde SLG 모델을 저장한다.
SLG_linear_models={
'Lasso':GridSearchCV(Lasso(), param_grid=lasso_params).fit(SLG_train.iloc[:,-5:],SLG_train['SLG']).best_estimator_,
'Ridge':GridSearchCV(Ridge(), param_grid=lasso_params).fit(SLG_train.iloc[:,-5:],SLG_train['SLG']).best_estimator_,
}
Randomforest
import time
from sklearn.ensemble import RandomForestRegressor
start=time.time() #시작시간
#랜덤 포레스트의 파라미터 범위 정의
RF_params = {
"n_estimators":[50,100,150,200,300,500,100],
"max_features":['auto','sqrt'],
"max_depth":[1,2,3,4,5,6,10],
"min_samples_leaf":[1,2,4],
"min_samples_split":[2,3,5,10]}
#GridsearchCV를 이용하여 dict에 OBP RF 모델을 저장
OBP_RF_models={
"RF":GridSearchCV(
RandomForestRegressor(random_state=42), param_grid=RF_params, n_jobs=-1).fit(OBP_train.iloc[:,-5:],OBP_train['OBP']).best_estimator_}
#GridsearchCV를 이용하여 dict에 SLG RF 모델을 저장
SLG_RF_models={
"RF":GridSearchCV(
RandomForestRegressor(random_state=42), param_grid=RF_params, n_jobs=-1).fit(SLG_train.iloc[:,-5:],SLG_train['SLG']).best_estimator_}
print(f"걸린시간 : {np.round(time.time() -start,3)}초") #현재시간-시작시간(단위 초)
XGBoost
import xgboost as xgb
# from xgboost import XGBRegressor
start=time.time()
#xgboost parameter space를 정의
XGB_params={
'min_child_weight':[1,3,5,10],
'gamma':[0.3,0.5,1,1.5,2,5],
'subsample':[0.6,0.8,1.0],
'colsample_bytree':[0.6,0.8,1.0],
'max_depth':[3,4,5,7,10]}
#GridSearchCV를 통해 파라미터를 탐색 정의한다
XGB_OBP_gridsearch= GridSearchCV(xgb.XGBRegressor(random_state=42),
param_grid=XGB_params, n_jobs=-1)
XGB_SLG_gridsearch= GridSearchCV(xgb.XGBRegressor(random_state=42),
param_grid=XGB_params, n_jobs=-1)
#모델 학습
XGB_OBP_gridsearch.fit(OBP_train.iloc[:,-5:],OBP_train['OBP'])
XGB_SLG_gridsearch.fit(SLG_train.iloc[:,-5:],SLG_train['SLG'])
print(f"걸린시간 : {np.round(time.time() -start,3)}초")
알고리즘별 성능비교
#테스트 데이터셋(2018년)의 선수들의 OBP예측
Lasso_OBP=OBP_linear_models['Lasso'].predict(OBP_test.iloc[:,-5:])
Ridge_OBP=OBP_linear_models['Ridge'].predict(OBP_test.iloc[:,-5:])
RF_OBP=OBP_RF_models['RF'].predict(OBP_test.iloc[:,-5:])
XGB_OBP=XGB_OBP_gridsearch.predict(OBP_test.iloc[:,-5:])
#test 데이터의 WRMSE 계산
wrmse_score=[wrmse(OBP_test['OBP'],OBP_test['AB'],Lasso_OBP), #실제값,타수,예측값 순
wrmse(OBP_test['OBP'],OBP_test['AB'],Ridge_OBP),
wrmse(OBP_test['OBP'],OBP_test['AB'],RF_OBP),
wrmse(OBP_test['OBP'],OBP_test['AB'],XGB_OBP)]
x_lab=['Lasso','Ridge','RF','XGB']
plt.bar(x_lab,wrmse_score)
plt.title('WRMSE of OBP', fontsize=20)
plt.xlabel('model', fontsize=8)
plt.ylabel("",fontsize=18)
plt.ylim(0,0.5)
#막대 그래프 위에 값 표시
for i,v in enumerate(wrmse_score):
plt.text(i-0.1,v+0.01,str(np.round(v,3))) #x좌표,y좌표, 텍스트
plt.show()
#테스트 데이터셋(2018년)의 선수들의 SLG예측
Lasso_SLG=SLG_linear_models['Lasso'].predict(SLG_test.iloc[:,-5:])
Ridge_SLG=SLG_linear_models['Ridge'].predict(SLG_test.iloc[:,-5:])
RF_SLG=SLG_RF_models['RF'].predict(SLG_test.iloc[:,-5:])
XGB_SLG=XGB_SLG_gridsearch.predict(SLG_test.iloc[:,-5:])
#test 데이터의 WRMSE 계산
wrmse_score_SLG=[wrmse(SLG_test['SLG'],SLG_test['AB'],Lasso_SLG), #실제값,타수,예측값 순
wrmse(SLG_test['SLG'],SLG_test['AB'],Ridge_SLG),
wrmse(SLG_test['SLG'],SLG_test['AB'],RF_SLG),
wrmse(SLG_test['SLG'],SLG_test['AB'],XGB_SLG)]
x_lab=['Lasso','Ridge','RF','XGB']
plt.bar(x_lab,wrmse_score_SLG)
plt.title('WRMSE of SLG', fontsize=20)
plt.xlabel('model', fontsize=8)
plt.ylabel("",fontsize=18)
plt.ylim(0,0.9)
#막대 그래프 위에 값 표시
for i,v in enumerate(wrmse_score_SLG):
plt.text(i-0.1,v+0.01,str(np.round(v,3))) #x좌표,y좌표, 텍스트
plt.show()
결과해석 및 평가 - 변수의 중요도를 랜덤포레스트를 통해 알수가 있다
plt.figure(figsize=(15,6))
#가로막대 그래프
plt.subplot(1,2,1)
plt.barh(OBP_train.iloc[:,-5:].columns, OBP_RF_models['RF'].feature_importances_)
plt.title('Feature importance of RF in OBP')
plt.subplot(1,2,2)
plt.barh(SLG_train.iloc[:,-5:].columns, SLG_RF_models['RF'].feature_importances_)
plt.title('Feature importance of RF in SLG')
plt.show()
라쏘와 릿지 회귀모델
#Lasso에서 GridSearchCV로 탐색한 최적의 alpha값 출력
print('Alpha:',OBP_linear_models['Lasso'].alpha)
#Lasso model의 선형계수 값 출력
display(pd.DataFrame(OBP_linear_models['Lasso'].coef_.reshape(-1,5),
columns=OBP_train.iloc[:,-5:].columns, index=['coefficient']))
#Lasso에서 GridSearchCV로 탐색한 최적의 alpha값 출력
print('Alpha:',SLG_linear_models['Lasso'].alpha)
#Lasso model의 선형계수 값 출력
display(pd.DataFrame(SLG_linear_models['Lasso'].coef_.reshape(-1,5),
columns=SLG_train.iloc[:,-5:].columns, index=['coefficient']))
from sklearn.linear_model import lars_path
plt.figure(figsize=(15,4.8))
plt.subplot(1,2,1)
#OBP모델의 alpha값의 변화에 따른 계수의 변화를 alpha,coefs에 저장
alphas,_,coefs = lars_path(OBP_train.iloc[:,-5:].values, OBP_train['OBP'], method='lasso',verbose=True)
#피처별 alpha값에 따른 선형 모델 계수의 절댓값의 합
xx= np.sum(np.abs(coefs.T),axis=1) #coefs.T.shape : (6,5), axis=1하니까 행으로 합쳐지는 것같다. 총 6개 값이 나온다
#계수의 절댓값 중 가장 큰 값으로 alpha에 따른 피처의 계수의 합을 나눈다
xx/=xx[-1] #0.81069777을 각 원소에 나눈다
plt.plot(xx, coefs.T)
plt.xlabel('|coef|/max|coef|')
plt.ylabel('cofficients')
plt.title('OBP LASSO path')
plt.axis('tight')
plt.legend(OBP_train.iloc[:,-5:].columns)
plt.subplot(1,2,2)
#SLG모델에서 alptha값의 변화에 따른 계수의 변화를 alpha, coefs에 저장
alphas,_,coefs = lars_path(SLG_train.iloc[:,-5:].values, SLG_train['SLG'], method='lasso',verbose=True)
#피처별 alpha값에 따른 선형 모델 계수의 절댓값의 합
xx= np.sum(np.abs(coefs.T),axis=1)
#계수의 절댓값 중 가장 큰 값으로 alpha에 따른 피처의 계수의 합을 나눈다
xx/=xx[-1]
plt.plot(xx, coefs.T)
plt.xlabel('|coef|/max|coef|')
plt.ylabel('cofficients')
plt.title('SLG LASSO path')
plt.axis('tight')
plt.legend(SLG_train.iloc[:,-5:].columns)
plt.show()
위 그래프 원리는 좀더 공부가 필요해 보임
앙상블
print('OBP model averaging:', wrmse(OBP_test['OBP'], OBP_test['AB'],(Lasso_OBP+RF_OBP)/2))
print('SLG model averaging:', wrmse(SLG_test['SLG'], SLG_test['AB'],(Lasso_SLG+RF_SLG)/2))
OBP model averaging: 0.3181395239559683
SLG model averaging: 0.6717303946958075
단순화된 모델 생성
#전처리된 데이터를 다른 곳에 저장
sum_hf_yr_OBP_origin=sum_hf_yr_OBP.copy()
#전체 희생 플라이 계산
regular_season_df_SF['SF']=regular_season_df[['H','BB','HBP']].sum(axis=1)/regular_season_df['OBP']-regular_season_df[['AB','BB','HBP']].sum(axis=1)
regular_season_df['SF'].fillna(0, inplace=True) #결측값은 0으로
regular_season_df['SF']=regular_season_df['SF'].apply(lambda x:round(x,0)) #정수형태로 변경
#한 타수당 평균 희생 플라이 계산 후 필요한 것만 추출
regular_season_df['SF_1']=regular_season_df['SF']/regular_season_df['AB']
regular_season_df_SF=regular_season_df[['batter_name','year','SF_1']]
# day_by_day_df에서 연도별 선수의 시즌 상반기 출루율과 관련된 성적 합 구하기 +BB,RBI 추가
sum_hf_yr_OBP= day_by_day_df.loc[day_by_day_df['date']<=7.18].groupby(['batter_name','year'])['AB','H','BB','HBP','RBI','2B','3B','HR'].sum().reset_index()
# day_by_day_df와 regular_season에서 구한 희생플라이 관련 데이터 합치기
sum_hf_yr_OBP=sum_hf_yr_OBP.merge(regular_season_df_SF, how='left', on=['batter_name','year'])
#한 타수당 평군 희생플라이 계산, 정규시즌에서 구한 희생플라이 비율을 일일데이터에 적용
sum_hf_yr_OBP['SF']=(sum_hf_yr_OBP['SF_1']*sum_hf_yr_OBP['AB']).apply(lambda x:round(x,0))
sum_hf_yr_OBP.drop('SF_1', axis=1, inplace=True)
#각 변수에 대한 1년 전 성적 생성
sum_hf_yr_OBP=lag_function(sum_hf_yr_OBP,'BB',1)
sum_hf_yr_OBP=lag_function(sum_hf_yr_OBP,'TB',1)
sum_hf_yr_OBP=lag_function(sum_hf_yr_OBP,'RBI',1)
sum_hf_yr_OBP=lag_function(sum_hf_yr_OBP,'OBP',1)
sum_hf_yr_OBP=sum_hf_yr_OBP.dropna() #결측치 포함한 행 제거
#변수리스트 지정
feature_list1=['age','lag1_OBP','mean_OBP']
feature_list2=['age','lag1_OBP','lag1_BB','lag1_TB','lag1_RBI','lag1_OBP','mean_OBP']
#학습시킬 데이터 30타수 이상만 학습
sum_hf_yr_OBP= sum_hf_yr_OBP.loc[sum_hf_yr_OBP['AB']>=30]
#2018 test로 나누고 나머지는 학습
OBP_train=sum_hf_yr_OBP.loc[sum_hf_yr_OBP['year']!=2018]
OBP_test=sum_hf_yr_OBP.loc[sum_hf_yr_OBP['year']==2018]
#gridSearch를 이용한 학습
OBP_RF_models_1={
'RF':GridSearchCV(RandomForestRegressor(random_state=42), param_grid=RF_params, n_jobs=-1).fit(OBP_train.loc[:,feature_list1], OBP_train['OBP']).best_estimator_
}
OBP_RF_models_2={
'RF':GridSearchCV(RandomForestRegressor(random_state=42), param_grid=RF_params, n_jobs=-1).fit(OBP_train.loc[:,feature_list2], OBP_train['OBP']).best_estimator_
}
#예측
RF_OBP1= OBP_models_1['RF'].predict(OBP_test.loc[:,feature_list1])
RF_OBP2= OBP_models_2['RF'].predict(OBP_test.loc[:,feature_list2])
#wrmse 계산
wrmse_score= [wrmse(OBP_test['OBP'], OBP_test['AB'],RF_OBP1),
wrmse(OBP_test['OBP'], OBP_test['AB'],RF_OBP2)]
x_lab=['simple','complicate']
plt.bar(x_lab, wrmse_score)
plt.title('WRMSE of OBP', fontsize=20)
plt.xlabel('model', fontsize=18)
plt.xlabel('', fontsize=18)
plt.ylim(0,0.5)
#막대그래프 위에 값 표시
for i,v in enumerate(wrmse_score):
plt.text(i-0.1, v+0.01, str(np.round(v,3)))
plt.show()
#최종 제출을 위한 워래 데이터 복구
sum_hf_yr_OBP=sum_hf_yr_OBP_origin.copy()
# submission OBP,SLG 파일 2개로 만들어 합치기
submission_OBP=submission.copy()
submission_SLG=submission.copy()
OBP
# 앞서 전처리한 데이터를 이용해 평균 성적 기입
submission_OBP=submission_OBP.merge(sum_hf_yr_OBP[['batter_name','mean_OBP']].drop_duplicates().reset_index(drop=True),
how='left', on='batter_name')
#과거 성적 값 채우기
for i in [1,2,3]:
temp_lag_df=sum_hf_yr_OBP.loc[
(sum_hf_yr_OBP['year']==(2019-i))&
(sum_hf_yr_OBP['AB']>=30),['batter_name','OBP']].copy()
temp_lag_df.rename(columns={'OBP':'lag'+str(i)+'_OBP'}, inplace=True)
submission_OBP=submission_OBP.merge(temp_lag_df, how='left', on='batter_name')
submission_OBP.head()
case1 - 일별 데이터에 기록이 없어서 mean_OBP가 없는 경우 - 김주찬,이범호
for batter_name in ['김주찬','이범호']:
#30타수 이상인 해당선수의 인덱스
cond_regular=(regular_season_df['AB']>=30) & (regular_season_df['batter_name']==batter_name)
#타수를 고려해 평균 OBP계산
mean_OBP= sum(regular_season_df.loc[cond_regular,'AB']*\
regular_season_df.loc[cond_regular,'OBP'])/\
sum(regular_season_df.loc[cond_regular,'AB'])
submission_OBP.loc[(submission_OBP['batter_name']==batter_name),'mean_OBP']=mean_OBP #계산한 평균값으로 대체
#regular_season_df으로부터 1,2,3년전 성적 구하기
cond_sub=submission_OBP['batter_name']==batter_name
#타수가 30이면서 김주찬,이범호인 사람의 2018년 기록을 lag1_OBP에 삽입
submission_OBP.loc[cond_sub,'lag1_OBP']=regular_season_df.loc[(cond_regular)&(regular_season_df['year']==2018),'OBP'].values
#타수가 30이면서 김주찬,이범호인 사람의 2017년 기록을 lag1_OBP에 삽입
submission_OBP.loc[cond_sub,'lag1_OBP']=regular_season_df.loc[(cond_regular)&(regular_season_df['year']==2017),'OBP'].values
#타수가 30이면서 김주찬,이범호인 사람의 2016년 기록을 lag1_OBP에 삽입
submission_OBP.loc[cond_sub,'lag1_OBP']=regular_season_df.loc[(cond_regular)&(regular_season_df['year']==2016),'OBP'].values
case2 - 1998년 혹은 1999년 출생의 신인급 선수 - 성장가능성을 기대 할수 있으므로 2018년 시즌의 성적으로 출루율의 평균을 대체
for i in np.where(submission_OBP['batter_name'].isin(['고명성','전민재','김철호','신범수','이병휘'])):
submission_OBP.loc[i,'mean_OBP']=season_OBP_mean.loc[season_OBP_mean['year']==2018,'mean_OBP']
case3
- 2018년 하반기 성적만 있는 경우 - 정규시즌 성적을 바탕으로 평균 출루율 / 1년 전 출루율 수치를 대체
for batter_name in ['전병우','샌즈']:
#30타수 이상인 해당 선수의 index추출
cond_regular=(regular_season_df['AB']>=30)&(regular_season_df['batter_name']==batter_name)
#타수를 고려해 선수의 평균 OBP 계산
mean_OBP=sum(regular_season_df.loc[cond_regular, 'AB']* regular_season_df.loc[cond_regular,'OBP'])/\
sum(regular_season_df.loc[cond_regular,'AB'])
submission_OBP.loc[(submission_OBP['batter_name']==batter_name),'mean_OBP']=mean_OBP
#2018년 데이터로부터 2019년 1년 전 성적 기입
cond_sub= submission_OBP['batter_name']==batter_name
submission_OBP.loc[cond_sub,'lag1_OBP']=regular_season_df.loc[(cond_regular)&(regular_season_df['year']==2018),'OBP'].values
case3
- 은퇴 혹은 1군 수준의 성적을 보여주지 못한 선수 - 하위25%의 성적으로 대체
#평균 성적이 결측치인 선수들에 대해 평균 OBP의 하위25% 성적 기입
submission_OBP.loc[submission_OBP['mean_OBP'].isna(),'mean_OBP']=np.quantile(player_OBP_mean['mean_OBP'],0.25)
#과거 데이터 채우기
for i in [1,2,3]:
#i년 전 OBP 결측치 제거
submission_OBP=lag_na_fill(submission_OBP,'OBP',i,season_OBP_mean)
submission_OBP.head()
SLG
# 앞서 전처리한 데이터를 이용해 평균 성적 기입
submission_SLG=submission_SLG.merge(sum_hf_yr_SLG[['batter_name','mean_SLG']].drop_duplicates().reset_index(drop=True),
how='left', on='batter_name')
#과거 성적 값 채우기
for i in [1,2,3]:
temp_lag_df=sum_hf_yr_SLG.loc[
(sum_hf_yr_SLG['year']==(2019-i))&
(sum_hf_yr_SLG['AB']>=30),['batter_name','SLG']].copy()
temp_lag_df.rename(columns={'SLG':'lag'+str(i)+'_SLG'}, inplace=True)
submission_SLG=submission_SLG.merge(temp_lag_df, how='left', on='batter_name')
submission_SLG.head()
#case1
for batter_name in ['김주찬','이범호']:
#30타수 이상인 해당선수의 인덱스
cond_regular=(regular_season_df['AB']>=30) & (regular_season_df['batter_name']==batter_name)
#타수를 고려해 평균 OBP계산
mean_SLG= sum(regular_season_df.loc[cond_regular,'AB']*\
regular_season_df.loc[cond_regular,'SLG'])/\
sum(regular_season_df.loc[cond_regular,'AB'])
submission_SLG.loc[(submission_SLG['batter_name']==batter_name),'mean_SLG']=mean_SLG #계산한 평균값으로 대체
#regular_season_df으로부터 1,2,3년전 성적 구하기
cond_sub=submission_SLG['batter_name']==batter_name
#타수가 30이면서 김주찬,이범호인 사람의 2018년 기록을 lag1_OBP에 삽입
submission_SLG.loc[cond_sub,'lag1_SLG']=regular_season_df.loc[(cond_regular)&(regular_season_df['year']==2018),'SLG'].values
#타수가 30이면서 김주찬,이범호인 사람의 2017년 기록을 lag1_OBP에 삽입
submission_SLG.loc[cond_sub,'lag1_SLG']=regular_season_df.loc[(cond_regular)&(regular_season_df['year']==2017),'SLG'].values
#타수가 30이면서 김주찬,이범호인 사람의 2016년 기록을 lag1_OBP에 삽입
submission_SLG.loc[cond_sub,'lag1_SLG']=regular_season_df.loc[(cond_regular)&(regular_season_df['year']==2016),'SLG'].values
#case2
for i in np.where(submission_SLG['batter_name'].isin(['고명성','전민재','김철호','신범수','이병휘'])):
submission_SLG.loc[i,'mean_SLG']=season_SLG_mean.loc[season_SLG_mean['year']==2018,'mean_SLG']
#case3
for batter_name in ['전병우','샌즈']:
#30타수 이상인 해당 선수의 index추출
cond_regular=(regular_season_df['AB']>=30)&(regular_season_df['batter_name']==batter_name)
#타수를 고려해 선수의 평균 OBP 계산
mean_SLG=sum(regular_season_df.loc[cond_regular, 'AB']* regular_season_df.loc[cond_regular,'SLG'])/\
sum(regular_season_df.loc[cond_regular,'AB'])
submission_SLG.loc[(submission_SLG['batter_name']==batter_name),'mean_SLG']=mean_SLG
#2018년 데이터로부터 2019년 1년 전 성적 기입
cond_sub= submission_SLG['batter_name']==batter_name
submission_SLG.loc[cond_sub,'lag1_SLG']=regular_season_df.loc[(cond_regular)&(regular_season_df['year']==2018),'SLG'].values
#case4
#평균 성적이 결측치인 선수들에 대해 평균 SLG의 하위25% 성적 기입
submission_SLG.loc[submission_SLG['mean_SLG'].isna(),'mean_SLG']=np.quantile(player_SLG_mean['mean_SLG'],0.25)
#과거 데이터 채우기
for i in [1,2,3]:
#i년 전 SLG 결측치 제거
submission_SLG=lag_na_fill(submission_SLG,'SLG',i,season_SLG_mean)
submission_SLG.head()
### OBP,SLG 둘다 lasso 모델에서 가장 좋은 성능을 보였으므로 lasso로 예측을 시행한다
#Lasso를 이용한 OBP 예측
predict_OBP=OBP_linear_models['Lasso'].predict(submission_OBP.iloc[:,-5:])
#Lasso를 이용한 SLG 예측
predict_SLG=SLG_linear_models['Lasso'].predict(submission_OBP.iloc[:,-5:])
final_submission=submission[['batter_id','batter_name']]
final_submission['OPS']=predict_SLG+predict_OBP #OBP+SLG= OPS
final_submission.head()
반발계수의 변화
#시즌별 전체 OBP 계산(30타수 이상인 선수들의 기록만 이용)
season_OBP=regular_season_df.loc[regular_season_df['AB']>=30].groupby('year').agg({'AB':'sum','H':'sum','BB':'sum','HBP':'sum','SF':'sum'}).reset_index()
season_OBP['OBP']=season_OBP[['H','BB','HBP']].sum(axis=1)/ season_OBP[['AB','BB','HBP','SF']].sum(axis=1)
#시즌별 전체 SLG 계산(30타수 이상인 선수들만의 기록만 사용)
season_SLG=regular_season_df.loc[regular_season_df['AB']>=30].groupby('year').agg({'AB':'sum','H':'sum','2B':'sum','3B':'sum','HR':'sum'}).reset_index()
season_SLG['SLG']=((season_SLG['H']- season_SLG[['2B','3B','HR']].sum(axis=1))+\
season_SLG['2B']*2+season_SLG['3B']*3+season_SLG['HR']*4)/season_SLG['AB']
#season_OBP와season_SLG 병합 후 season_OPS를 생성해 계산
season_OPS=pd.merge(season_OBP[['year','OBP']], season_SLG[['year','SLG']], on='year')
season_OPS['OPS']=season_OBP['OBP']+season_SLG['SLG']
#시즌별 전체 홈런 수와 한 선수당 평균 홈런 수 계산
season_HR=regular_season_df.loc[regular_season_df['AB']>=30].groupby('year').agg({'HR':['sum','mean','count']}).reset_index()
season_HR.columns=['year','sum_HR','mean_HR','count']
#기존의 OPB 데이터셋과 병합
season_OPS=season_OPS.merge(season_HR, on='year', how='left')
display(season_OPS)
# 2000년도 이전의 데이터 수가 충분치 않아 고려하지 않는다
season_OPS.loc[season_OPS['year']>2000]
#2018년의 평균 홈런 개수를 시즌별평균 홈런 수에서 뺀다
season_OPS['HR_diff']=season_OPS['mean_HR']-season_OPS['mean_HR'].iloc[-1]
difference=season_OPS.sort_values(by='HR_diff')[['year','OPS','HR_diff']]
display(difference.reset_index(drop=True).head(12))
final_submission['OPS'] =final_submission['OPS']-0.038
display(final_submission.head(10))
# final_submission.to_csv('submissionb.csv', index=False) #최종 제출 파일
이번 실습은 야구에 대한 도메인 지식이 부족한 상태에서 진행한거라 그런지 이해하기가 시간이 걸렸습니다
### 가우시안 필터
import sys
import numpy as np
import cv2
src = cv2.imread('rose.bmp', cv2.IMREAD_GRAYSCALE)
#커널크기는 (0,0)을 사용함으로써 sigma값을 계산하여 자동으로 크기를 결정한다
#사용자가 강제로 커널크기를 결정하면 가우시안의 분포 모양 가중치를 사용 못하기 때문에 지양한다
#sigmaX=1
#1.커널크기는 8*sigma+1(0.0좌표를 추가로 더한다), 9*9 커널크기 : 주로 float 타입 영상에 사용
#2.커널크기는 6*sigma+1(0.0좌표를 추가로 더한다), 7*7 커널크기 : 주로 uint8 타입 영상에 사용
#블러를 강하게,더 흐릿하게 할땐 시그마 값을 올린다
dst= cv2.GaussianBlur(src, (0,0),1) #7*7커널크기, sigmax=3, 6*3+1=19*19커널
dst2 = cv2.blur(src, (7, 7))
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.imshow('dst2', dst2)
cv2.waitKey()
cv2.destroyAllWindows()
가우시안 필터_2
### 가우시안필터 크기에 따른 영상변화
import sys
import numpy as np
import cv2
src = cv2.imread('rose.bmp', cv2.IMREAD_GRAYSCALE)
if src is None:
print('Image load failed!')
sys.exit()
cv2.imshow('src', src)
for sigma in range(1, 6):
# sigma 값을 이용하여 가우시안 필터링
dst = cv2.GaussianBlur(src, (0, 0), sigma)
desc = 'sigma = {}'.format(sigma)
#(x축의 글자 시작점 좌표,y축 글 시작점 좌표)
cv2.putText(dst, desc, (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
1.0, 255, 1, cv2.LINE_AA)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
샤프닝 필터_1
### 샤프닝
import sys
import numpy as np
import cv2
src = cv2.imread('rose.bmp', cv2.IMREAD_GRAYSCALE)
if src is None:
print('Image load failed!')
sys.exit()
blr = cv2.GaussianBlur(src,(0,0),2) #블러가 된 영상, 부드러워진 영상, 차이값을 얻디위해 블러처리
'''
엣지 포인트만 남아서 윤곽선으로 보인다.
이 윤곽선을 나타내는 픽셀값을 원본 영상에 더하면 되는데
subtract는 음수의 값을 0으로 바꾸기 때문에 완전한 엣지 픽셀모양이 아니다
이를 해결하기 위해서 addweighted를 사용한다
dst =cv2.subtract(src,blr)
'''
#src에 1가중치, blr에 -1 가중치 준뒤
#결과값을 잘 보기 위해서 128을 더해준다
tmp= cv2.addWeighted(src,1,blr,-1,128) #회색부분은 윤곽선이 아닌 부분임,흰색또는 검정색 부분이 엣지 포인트
#방법1
#아래처럼하면 tmp객체를 이용한 덧셈을 할 필요가 없다
#원하는 결과물은 (원본-부드러운영상)+원본= "2원본-부드러워진영상"이므로
#가중치를 아래처럼 설정한다.
dst= cv2.addWeighted(src,2,blr,-1,128) #가중치에 -가 붙으면 뺄셈이 가능하다
#방법2
#numpy형식이므로 아래 처럼 src-blr 형태로가능
#타입이 float으로 계산해야 saturate가 되지 않는다
# dst=np.clip(2.0*src-blr, 0,255).astype(np.uint8) #float64형태->np.uint8 변환해야 0~255 값 표현가능(2**8=256)
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
샤프닝 필터_2
### 컬러샤프닝
import sys
import numpy as np
import cv2
src = cv2.imread('rose.bmp') #컬러
if src is None:
print('Image load failed!')
sys.exit()
#컬러영상:밝기 채널만 활용한다
src_ycrcb = cv2.cvtColor(src, cv2.COLOR_BGR2YCrCb)
#0: Y(밝기)plane
src_f = src_ycrcb[:, :, 0].astype(np.float32) #np.float32 실수타입으로 바꾼다. 정교한 결과를 위해서
#GaussianBlur은 입력영상의 타입을 출력영상 타입과 같게 한다
#src_f가 실수값이라서 blr도 실수값을 가진다.
#실수값을 가진다는 건 213.3243352 의3243352이라는 미세한 픽셀값이 살아 있다는 의미
#따라서 미세한 값까지 반영한 픽셀값을 uint8로 변경해서 출력하면 보다 더 정교한 결과를 얻을수 있다
blr = cv2.GaussianBlur(src_f, (0, 0), 2.0)
#더해진 값을 0번째 plane에 덮어쓰기
src_ycrcb[:, :, 0] = np.clip(2.* src_f - blr, 0, 255).astype(np.uint8)
dst = cv2.cvtColor(src_ycrcb, cv2.COLOR_YCrCb2BGR) #imshow는 BGR채널만 취급한다
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
median 필터
### median 필터
import sys
import numpy as np
import cv2
src = cv2.imread('noise.bmp', cv2.IMREAD_GRAYSCALE)
if src is None:
print('Image load failed!')
sys.exit()
#입력영상에서 3*3 커널 픽셀을 정렬 한 후 median값을 결과영상 가운데 값에 그대로 넣는다
#후추노이즈 제거에 효과적
dst = cv2.medianBlur(src, 3)
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
### 잡음제거 필터
import sys
import numpy as np
import cv2
src = cv2.imread('lenna.bmp', cv2.IMREAD_GRAYSCALE)
if src is None:
print('Image load failed!')
sys.exit()
#커널크기는 자동적으로 계산되기 때문에 -1값으로 입력하는게 좋다
#10(시그마 값임): 이 값을 기준으로 엣지 부분인지 아닌지를 판단한다.(sigmaColor)
#5: sigmaspace -> 가우시안블러의 시그마기능과 완전히 같다
#5이상의 값을 넣으면 가우시간 필터값이 커지게 된다 (8*sigma+1 또는 6*sigma+1)
#필터크기가 커진다-> 연산량증가 -> 속도 저하
dst = cv2.bilateralFilter(src, -1, 10, 5)
'''
sigmaColor추가설명
위 예제처럼 표준편차가 10이라고 한다면
가우시안 분포x 값이 -10<x<10 사이에 67%값들이 모여있다고 설명할수 있다
이때, 보통 플러스마이너스 2시그마, or 3시그마 보다 큰 픽셀이라면
엣지로 인식해서 블러를 적용안하고 살린다.
'''
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
카툰필터
### 카툰 필터
# 카툰 필터 카메라
import sys
import numpy as np
import cv2
#자연스러운 컬러를 단순한 컬러로 바꾸고 ->cv2.bilaterFilter
#검정색 엣지를 단순한 컬러 영상에 ->cv2.Canny
#합친다 ->cv2.bitwise_and():검정색 엣지를 0픽셀값으로 변경하고, 그외 하얀 부분은 단순한 컬로 영상으로 채운다
def cartoon_filter(img):
#크기 반으로 축소
h,w =img.shape[:2]
img =cv2.resize(img, (w//2, h//2)) #축소 후 연산하면 연산량도 줄어들뿐만 아니라 단순한 컬러의 효과가 극대화된다
blr= cv2.bilateralFilter(img, -1, 20, 7) #과장하게 만들기 위해 시그마 값을 좀 높게 설정
#50~120으로하면 평탄한 부분이 검정,엣지가 하얀색이되므로 255로 빼서 반전시킨다
#평탄한부분이 하얀, 엣지가 검정으로 반전되는 것
edge=cv2.Canny(img,50,120) #컬러영상을 내부적으로 그레이로 바꾼다
edge=cv2.cvtColor(edge,cv2.COLOR_GRAY2BGR) #blr가 컬러이므로 합치기 위해서 타입을 컬러로 통일
dst= cv2.bitwise_and(blr,edge)
#크기 정상으로 다시 확대
dst=cv2.resize(dst,(w,h), interpolation=cv2.INTER_NEAREST) #interpolation의 디폴트 값으로 하면 블러처리된 느낌을 준다
#지금은 급격한 변화를 줘야 하므로 따로 설정한다
return dst
#그레이로 컨버트 시킨 후
#가우시안블러로 처리한다.
#가우시안블러를 사용하면 엣지 부분이 완만한 곡선으로 블러처리되는데
#이 부분을 검정색으로처리하고, 나머지는 모두 흰색으로 처리한다
#검정과 흰색을 처리하는 연산은 가우시안블러를 한 영상을 그레이영상에 나눗셈하여 얻을수 있다
#가우시안블러가 큰 쪽(엣지가 발생한 영역)은 0.xx 값으로 나온다.
#엣지영역에 가우시안블러를 처리하면 급격한 경사을 완만한 곡선으로 만들어준다
#급격한 경사를 이루는 부분의 높이가 완만한곡선의 높이보다 낮으므로
#완만한곡선의 높이를 나누면 0.xx로 되고
#반대로 그레이값의 높이가 더 큰 평탄화 부분은 픽셀 1.xxx로 결과값을 얻게 된다
#0.xx 와 1.xx 이둘이 남겨 되는데 0픽셀이나 1픽셀이나 구분을 못하므로 곱하기 255로 해준다
#결론적으로 0*255, 1*255이 되므로 엣지 부분이 검정색, 나머지가 하얀색으로 된다
def pencil_sketch(img):
gray= cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blr= cv2.GaussianBlur(gray, (0,0), 3)#가우시안블러처리
dst=cv2.divide(gray, blr, scale=255) #나눠준후 255곱하기
return dst
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print('video open failed!')
sys.exit()
cam_mode = 0 # 0이 오리지널, 1:카툰필터, 2:스케치 필터
while True:
ret, frame = cap.read()
if not ret:
break
if cam_mode == 1:
frame = cartoon_filter(frame)
elif cam_mode == 2:
frame = pencil_sketch(frame)
# frame = cv2.cvtColor(frame, cv2.COLOR_GRAY2BGR) #없어도 작동한다
cv2.imshow('frame', frame)
key = cv2.waitKey(1)
if key == 27:
break
elif key == ord(' '):
cam_mode += 1
if cam_mode == 3:
cam_mode = 0
cap.release()
cv2.destroyAllWindows()
### video_effect
# ==========================합성하기 전 데이터 준비==============================
import sys
import numpy as np
import cv2
# 두 개 동영상열어서 각 객체에 지정하기
cap1= cv2.VideoCapture('video1.mp4') #원숭이 영상
cap2= cv2.VideoCapture('video2.mp4') #코끼리 영상
#예외처리 코드
if not cap1.isOpened() or not cap2.isOpened(): #둘중에 하나라도 열리지 않을경우
print('video open failed!')
sys.exit()
# 두 동영상의 크기, FPS는 같다고 가정(FPS:초당 24.75프레임, 초당 정지 사진을 24개씩 보여준다는 의미)
frame_cnt1=round(cap1.get(cv2.CAP_PROP_FRAME_COUNT)) #1번 영상의 전체 프레임수
frame_cnt2=round(cap2.get(cv2.CAP_PROP_FRAME_COUNT)) #2번 영상의 전체 프레임수
fps= cap1.get(cv2.CAP_PROP_FPS) #24 출력됨
#첫번째영상 끝부분 2초,두번째 앞부분 2초 영상을 합성이 되게끔
effect_frames= int(fps*2) #초당 24프레임 곱하기 2 = 48프레임을 가진다(합성부분)
print('frame_cnt1',frame_cnt1)
print('frame_cnt2',frame_cnt2)
print('FPS',fps)
delay= int(1000/fps) #두 영상 사이의 시간 간격을 계산, 두 영상 재생시간(저장할때 실제 영상시간이 저장된다)
#영상크기 뽑아내기
w= round(cap1.get(cv2.CAP_PROP_FRAME_WIDTH)) #반올림해서 정수로 만듦
h= round(cap1.get(cv2.CAP_PROP_FRAME_HEIGHT))
fourcc= cv2.VideoWriter_fourcc(*'DIVX') #영상 압축
#출력 동영상 객체 생성
#영상 저장하기 위해서는 가로세로크기, 압축방식, fps
out= cv2.VideoWriter('output.avi', fourcc,fps, (w,h)) #영상저장
# ==============================두영상을 단순히 이어붙이기==============================
#첫번째 영상
'''
while True:
ret1,frame1 = cap1.read()
if not ret1: #영상이 끝나면 while문을 빠져 나오기
break
out.write(frame1) #1번째 영상 고대~로 저장
cv2.imshow('frame',frame1)
cv2.waitKey(delay)
#두번째 영상
while True:
ret2,frame2 = cap2.read()
if not ret2: #영상이 끝나면 while문을 빠져 나오기
break
out.write(frame2) #2번째 영상 고대~로 저장
cv2.imshow('frame',frame2) #frame이라는 창을 이어쓰기
cv2.waitKey(delay)
'''
# ============================밀어내기 합성================================
#첫번째 영상 나오고->합성영상-> 두번째 영상으로 마무리 순
#첫번째 영상
for i in range(frame_cnt1- effect_frames): #1번영상의 48프레임은 남겨두고 out영상에 그대로 저장된다
ret1, frame1 =cap1.read()
if not ret1:
break
out.write(frame1) #1번영상 저장
cv2.imshow('frame',frame1) #1번영상 보여준 후 합성된 영상 2초짜리 보여준다
cv2.waitKey(delay)
#합성영상
for i in range(effect_frames): #effect_frames: 1번 영상 2번 영상 겹치는 프레임(48프레임=2초동안)
ret1, frame1=cap1.read()
ret2, frame2=cap2.read()
#합성
# 첫번째 영상 밀어낼때 얼만큼 간격으로 영상을 바꿀건지 정하기
#dx = (w*i//effect_frames) w:1280
dx = int(w*i/effect_frames) # 1280/48 = 가로가 약27개 픽셀단위로 밀어낸다
#for문이 실행되면서 27*i 만큼 점차 픽셀이 늘어나는 것
#0,27,54,81,~ 합성할 부분의 픽셀이 늘어난다 -> ppt의 밀어내기 기능과 유사, 2번째 영상으로 전환 되어 간다
#몇초간? 2초(48프레임=effect_frame)동안,
frame = np.zeros((h,w,3), dtype=np.uint8) #컬러영상에 맞게 설정하여 두 영상을 대입한다
frame[:,0:dx]= frame2[:,0:dx] #영상앞부분 부터 서서히 2번째 영상으로 채워진다 왜? dx의 픽셀이 for돌아갈수록 늘어나니까
frame[:,dx:w] =frame1[:,dx:w] #앞부분에 채워진 두번영상 이후 첫번째 영상을 넣어야 한다. w:1280(가로 끝까지)
# ============================디졸브합성================================
#두 영상 디졸브로 합성하기: 두번째영상을 서서히 나타나게 함, 합성영상에서 두 영상의 가중치를 다르게 조정
# alpha=1.0-i/effect_frames #frame1 가중치를 서서히 낮춘다. effect_frames가 48이니까 i가 증가할수록 가중치가 낮아지는 것.
#alpha:frame1의 가중치
# frame= cv2.addWeighted(frame1, alpha, frame2, 1-alpha,0) #0: gamma-> 전체 가중치에 추가로 더하는 가중치
# =====================================================================
out.write(frame)
cv2.imshow('frame',frame)
cv2.waitKey(delay)
cap1.release()
cap2.release()
out.release()
cv2.destroyAllWindows()
영상 밝기 조절
### 영상의 밝기 조절
import sys
import numpy as np
import cv2
#src: 입력을 의미, dst: 출력을 의미
src= cv2.imread('lenna.bmp',cv2.IMREAD_GRAYSCALE)
#grayscale 영상을 100만큼 밝게 하는 경우
'''
dst=cv2.add(src,100)
dst=src+100 #src가 ndarray이기 때문에 브로드캐스팅으로 덧셈이 가능
#하지만 255보다 큰 값은 0에 가까운 값으로 변하게 되는 문제점발생
#numpy 개선코드
#100. : 점.을찍어서 실수 단위로 연산이 되게 해야한다
#결과가 실수 단위로 계산이 된다
#그 후 astype으로 다시 컨버트해준다
dst=np.clip(src+100.,0,255).astype(np.uint8) #결과가 0보다 작으면 0으로,255보다 크면 255로 만들기
'''
#컬러로 불러와서 100만큼 밝게 하는 경우
'''
src= cv2.imread('lenna.bmp')
#아래결과는 블루색깔이 많아진다 왜일까?
dst=cv2.add(src,100) #여기서 100은 사실 네개의 실수값 네개로 구성된 스칼라 값이다
#따라서 실제 컴퓨터는(100,0,0,0)로 구성이된다 순서 상 100이 블루이므로 블루색이 100만큼 더 증가
'''
#동일하게 모두 밝게 할때
dst=cv2.add(src, (100,100,100,0))
cv2.imshow('src',src)
cv2.imshow('dst',dst)
cv2.waitKey()
cv2.destroyAllwindows()
산술연산
### 영상의 산술연산
import sys
import numpy as np
import cv2
from matplotlib import pyplot as plt
src1 = cv2.imread('lenna256.bmp', cv2.IMREAD_GRAYSCALE)
src2 = cv2.imread('square.bmp', cv2.IMREAD_GRAYSCALE)
if src1 is None or src2 is None:
print('Image load failed!')
sys.exit()
dst1 = cv2.add(src1, src2, dtype=cv2.CV_8U) #덧셈
dst2 = cv2.addWeighted(src1, 0.5, src2, 0.5, 0.0) #두 가중치 0.50 => 두 입력영상의 윤곽을 골고루 가지는 평균영상
dst3 = cv2.subtract(src1, src2) #두 영상을 뺄셈
dst4 = cv2.absdiff(src1, src2) #두영상 중 가장 차이가 나는 곳을 표현 ex)틀린그림 찾기에서 틀린 부분만 부각되어 표현될것이다
plt.subplot(231), plt.axis('off'), plt.imshow(src1, 'gray'), plt.title('src1')
plt.subplot(232), plt.axis('off'), plt.imshow(src2, 'gray'), plt.title('src2')
plt.subplot(233), plt.axis('off'), plt.imshow(dst1, 'gray'), plt.title('add')
plt.subplot(234), plt.axis('off'), plt.imshow(dst2, 'gray'), plt.title('addWeighted')
plt.subplot(235), plt.axis('off'), plt.imshow(dst3, 'gray'), plt.title('subtract')
plt.subplot(236), plt.axis('off'), plt.imshow(dst4, 'gray'), plt.title('absdiff')
plt.show()
컬러영상
### 컬러 영상과 색 공간
import sys
import numpy as np
import cv2
# 컬러 영상 불러오기
src = cv2.imread('candies.png', cv2.IMREAD_COLOR)
if src is None:
print('Image load failed!')
sys.exit()
# 컬러 영상 속성 확인
print('src.shape:', src.shape) # src.shape: (480, 640, 3)
print('src.dtype:', src.dtype) # src.dtype: uint8
#컬러 공간 변환
'''
src_hsv=cv2.cvtColor(src, cv2.COLOR_BGR2HSV)
plane=cv2.split(src_hsv)
'''
#채널분리
plane=cv2.split(src)#3개의 영상이 들어있는 리스트가 반환
cv2.imshow('src', src)
cv2.imshow('plane[0]',plane[0]) #블루
cv2.imshow('plane[1]',plane[1]) #그린
cv2.imshow('plane[2]',plane[2]) #레드
cv2.waitKey()
cv2.destroyAllWindows()
히스토그램_1
### 히스토그램1
import sys
import numpy as np
import matplotlib.pyplot as plt
import cv2
# 그레이스케일 영상의 히스토그램
src= cv2.imread('lenna.bmp', cv2.IMREAD_GRAYSCALE) #채널이 하나 ->[0]
if src is None:
print('IMAGE load failed')
sys.exit()
#[0]:gray채널 #bin의 수256 #gray 범위가 0부터256까지
hist = cv2.calcHist([src], [0], mask=None, histSize=[256], ranges=[0,256])
cv2.imshow('src',src)
cv2.waitKey(1) #이 구간에서 1ms 대기 후 아래 코드로 넘어가라는 의미
plt.plot(hist)
plt.show()
# 컬러 영상의 히스토그램
src= cv2.imread('lenna.bmp')
if src is None:
print('IMAGE load failed')
sys.exit()
colors=['b','g','r']
bgr_planes= cv2.split(src) #bgr 각 채널을 따로 분리해서 아래 for문을 돌린다
#세개의 색상성분의 히스토그램을 계산하는데,
#각각을 일차원 그레이스케일 형태로 생각하고 계산하는 것임
for (p,c) in zip(bgr_planes, colors):
hist= cv2.calcHist([p], [0], None, [256],[0,256])
plt.plot(hist, color=c) #컬러값을 지정해준다
cv2.imshow('src',src)
cv2.waitKey(1)
plt.show()
히스토그램_2
### 히스토그램2
import sys
import numpy as np
import matplotlib.pyplot as plt
import cv2
#cv2를 이용해서 히스토그램을 만드는 함수
def getGrayHistImage(hist):
#세로100, 가로256, 밝기 255의 흰 창
imgHist = np.full((100, 256), 255, dtype=np.uint8)
#흰 창에 하나씩 그림을 그리는 것
histMax = np.max(hist) #세로가 창을 벗어나가는 것을 제한 하기 위함
print("histMax:",histMax)
for x in range(256):
pt1 = (x, 100)
#hist[x, 0]: 높이를 뜻함, 2745가 가장 큰값 100-int(2745*100/2745))=0
pt2 = (x, 100 - int(hist[x, 0] * 100 / histMax)) #가장 높은 값이 100이 되도록(공부필요)
print('hist[x, 0]',hist[x, 0], 'pt2', pt2) # 최고치 hist[x, 0] 2745.0 일때 pt2는 (155, 0) 즉 155픽셀이 2745개가 있다
#x축을 나타내는 pt1=(x,100)이다. 기존 좌표는 (1,0), (2,0)으로 y값이 0으로 고정이 되는데
#이 그래프는 y=100이 0의 역할을 한다 즉(1,0)=(1,100)
#따라서 최대높이인 2745값을 pt2를 이용해 높이를 계산하면 0이 나온다 (가장 높은 높이 0)
#0과100이 반대개념이라 생각하면 된다
cv2.line(imgHist, pt1, pt2, 0) #pt1 부터 pt2까지 그림을 그린다
#pt1이 가로 좌표,pt2가 세로좌표, 이 둘의 좌표를 이은다
#밑바닥에서 시작해서 위로 뻗어가는 직선의 선들을 쭉 생성하면 히스토그램 그림이 된다
return imgHist
src = cv2.imread('lenna.bmp', cv2.IMREAD_GRAYSCALE)
if src is None:
print('Image load failed!')
sys.exit()
hist = cv2.calcHist([src], [0], None, [256], [0, 256])
histImg = getGrayHistImage(hist)
cv2.imshow('src', src)
cv2.imshow('histImg', histImg)
cv2.waitKey()
cv2.destroyAllWindows()
Contrast_1
### 명함비1
import sys
import numpy as np
import cv2
src = cv2.imread('lenna.bmp', cv2.IMREAD_GRAYSCALE)
if src is None:
print('Image load failed!')
sys.exit()
alpha=1.0 #값이 커질수록 더 급격한 기울기를 갖는다= 급격한 명도
#np.clip 쓰는이유: sturate용도
#아래 공식은 강의에서 제시한 명함비 공식
#(128,128)을 지나고 y절편이 -128인 직선이다
#장점:영상에서 가장 많이 분포하는 픽셀부분에 명함 부여하기가 좋다
#단점: 아주 밝은 영상이나 어두운 영상의 픽셀은 주로 양끝단에 위치하므로 sturate로 인해 0 또는 255로 고정이된다
#다시말해 아주 밝거나 어두운 영상에는 명함을 주지 못한다
#alpha가 실수형, dst도 실수형으로 계산하기 때문에 마지막에는 astype(np.uint8)로 변경
dst=np.clip((1+alpha)*src-128*alpha,0,255).astype(np.uint8)
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
Contrast_2
### 명함비2
import sys
import numpy as np
import cv2
def getGrayHistImage(hist):
imHist= np.full((100,256), 255, dtype=np.uint8)
histMax=np.max(hist)
for x in range(256):
pt1=(x,100)
pt2=(x,100-int(hist[x,0]*100/histMax))
cv2.line(imHist,pt1,pt2,0)
return imHist
src = cv2.imread('Hawkes.jpg', cv2.IMREAD_GRAYSCALE)
if src is None:
print('Image load failed!')
sys.exit()
#히스토그램 스트레칭: 명도 자동 조절해준다
# None:dst를 None로 해주면된다
# 0:alpha, 255:beta
#함수 적용한 경우
# dst= cv2.normalize(src,None,0,255, cv2.NORM_MINMAX)
#numpy로 계산한 경우_공식은 책 참고(p222)
gmin= np.min(src)
gmax= np.max(src)
#255.: 실수형으로 계산 후 마무리는 uint8
#src: 픽셀값
dst= np.clip((src-gmin)*255./(gmax-gmin),0,255).astype(np.uint8)
#정리1:입력영상의 최소값을 0(알파)이 되게 하고, 최대값을 255(베타)로 만든다. (늘려준다)
#정리2:만일 입력영상의 최소값이 애초에 0이고, 최대값이 애초에 255라면 늘려봤자 그대로 일것이다
#정리3:최소값 픽셀이 만일50이고 최대값이 230이라면 스트레칭의 명함효과를 볼수 있다
# ==============================
#히스토그램 시각화하기
#입력영상에 대한 히스토그램
hist = cv2.calcHist([src], [0], None, [256], [0,256])
histImg=getGrayHistImage(hist)
#명함효과 넣은 영상 히스토그램
hist2 = cv2.calcHist([dst],[0],None,[256],[0,256])
histImg2= getGrayHistImage(hist2)
# ==============================
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.imshow('histImg', histImg)
cv2.imshow('histImg2', histImg2)
cv2.waitKey()
cv2.destroyAllWindows()
히스토그램 평활화
### 평활화
import sys
import numpy as np
import cv2
# 그레이스케일 영상의 히스토그램 평활화
src = cv2.imread('Hawkes.jpg', cv2.IMREAD_GRAYSCALE)
if src is None:
print('Image load failed!')
sys.exit()
'''
dst = cv2.equalizeHist(src)
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
'''
# 컬러 영상의 히스토그램 평활화(348p)
src = cv2.imread('field.bmp')
if src is None:
print('Image load failed!')
sys.exit()
#src_ycrcb를 각 채널로 분리후 밝기 정보를 가진 Y만을 평활화 한다
src_ycrcb = cv2.cvtColor(src, cv2.COLOR_BGR2YCrCb)
planes = cv2.split(src_ycrcb) #Y,Cr,Br =>planes는 세개짜리의 영상을 가진 리스트이다
#Y성분만 평활화진행
planes[0]=cv2.equalizeHist(planes[0])
#YCrCR-> BGR 변환 후 imshow()에 넣는다. imshow는 BGR만 취급한다
dst_ycrcb=cv2.merge(planes) #분리한 채널을 다시 합친다
dst= cv2.cvtColor(dst_ycrcb, cv2.COLOR_YCrCb2BGR)
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
특정컬러추출_1
### 특색영상추출
import sys
import numpy as np
import cv2
src = cv2.imread('candies.png') #밝은 영상
#src = cv2.imread('candies2.png') #어두운 영상
if src is None:
print('Image load failed!')
sys.exit()
#HSV로 변환
src_hsv = cv2.cvtColor(src, cv2.COLOR_BGR2HSV)
#그레이 영상이라면 스칼라 하나씩
#(B,G,R) (B,G,R)
#ex)블루 성분은 0~100까지 성분을 고른다
#lowerb, opperb
#하한값 상한값 사이의 값만 골라서 dst리턴해줌(0 or 255인 마스트영상이다(이진영상))
dst1 = cv2.inRange(src, (0, 128, 0), (100, 255, 100)) #어두운 영상은 색구별 성능 떨어짐
#(H,S,V) (H,S,V)
dst2 = cv2.inRange(src_hsv, (50, 150, 0), (80, 255, 255)) #어두운 영상에도 색 구분 성능 좋음(권장)
cv2.imshow('src', src)
cv2.imshow('dst1', dst1)
cv2.imshow('dst2', dst2)
cv2.waitKey()
cv2.destroyAllWindows()
특정컬러추출_1
### 트랙바를 이용한 색상 영역 추출
import sys
import numpy as np
import cv2
src = cv2.imread('candies.png')
if src is None:
print('Image load failed!')
sys.exit()
src_hsv = cv2.cvtColor(src, cv2.COLOR_BGR2HSV)
def on_trackbar(pos):
#getTrackbarPos: dst창에 있는 h_min 트랙바의 위치를 받는 함수
hmin= cv2.getTrackbarPos('H_min','dst') #H_min 트랙바 값의 위치값(사용자가 지정할수 있음)
#getTrackbarPos: dst창에 있는 h_max 트랙바의 위치를 받는 함수
hmax= cv2.getTrackbarPos('H_max','dst') #H_min 내용과 같음
dst= cv2.inRange(src_hsv, (hmin,150,0),(hmax,255,255))
cv2.imshow('dst',dst)
cv2.imshow('src', src)
cv2.namedWindow('dst')
#50:시작값, 179:트랙바 범위
cv2.createTrackbar('H_min', 'dst', 50, 179, on_trackbar)
cv2.createTrackbar('H_max', 'dst', 80, 179, on_trackbar)
on_trackbar(0)
cv2.waitKey()
cv2.destroyAllWindows()
히스토그램 역투영_1
### 히스토그램 역투영
import sys
import numpy as np
import cv2
# 입력 영상에서 ROI를 지정하고, 히스토그램 계산
src = cv2.imread('cropland.png')
if src is None:
print('Image load failed!')
sys.exit()
#선택된 영억이 x, y, w, h 사각형 형태의 정보로 저장된다
x, y, w, h = cv2.selectROI(src) #찾고 싶은 색깔 영역을 드래그 & 스페이스바,enter key
#히스토그램 계산(18~30번줄 까지)
src_ycrcb = cv2.cvtColor(src, cv2.COLOR_BGR2YCrCb)
crop = src_ycrcb[y:y+h, x:x+w] #사용자가 선택한 사각형 영역의 부분 영상
#x,y는 시작점 좌표
channels = [1, 2] #Ycrcb에서 Y를 쓰지 않는다. 1:Cr, 2:Cb, Y는 밝기정보, 조명에 대한 영향을 무시하기 위해서 Y를 사용X
cr_bins = 128 #원래는 256써야하지만 단순화 시킴
cb_bins = 128
histSize = [cr_bins, cb_bins]
cr_range = [0, 256] #256이라고 써야 256를 제외한 255까지로 인식한다
cb_range = [0, 256]
ranges = cr_range + cb_range #[0,256,0,256] => Cr1이 0~255,Cb2는 0~255 인식하는 코드
hist = cv2.calcHist([crop], channels, None, histSize, ranges)#계산된 히스토그램을 사용해서 역투영실시
hist_norm = cv2.normalize(cv2.log(hist+1), None, 0, 255, cv2.NORM_MINMAX, cv2.CV_8U)
# 입력 영상 전체에 대해 히스토그램 역투영
backproj = cv2.calcBackProject([src_ycrcb], channels, hist, ranges, 1)
dst = cv2.copyTo(src, backproj)
cv2.imshow('backproj', backproj)
cv2.imshow('hist_norm', hist_norm)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
히스토그램 역투영_2
### 히스토그램 역투영2
import sys
import numpy as np
import cv2
# CrCb 살색 히스토그램 구하기
ref = cv2.imread('kids1.png', cv2.IMREAD_COLOR)
mask = cv2.imread('kids1_mask.bmp', cv2.IMREAD_GRAYSCALE)
if ref is None or mask is None:
print('Image load failed!')
sys.exit()
ref_ycrcb = cv2.cvtColor(ref, cv2.COLOR_BGR2YCrCb)
#Y:0, Cr:1, Cb:2
channels = [1, 2]
#앞의 0,256은 Cr범위, 뒤에 0,256은 Cb
ranges = [0, 256, 0, 256]
#mask에 대해서 히스토그램을 구할때는 mask를 적어 넣고
#입력영상 전체에 대해서 히스토그램을 구할때는 None주면 된다
#구하고자 하는 색상의 mask영상을 먼저 히스토그램으로 계산한 후
#계산된 히스토그램을 통해서 역투영 한다
#histSize=[128,128]
hist = cv2.calcHist([ref_ycrcb], channels, mask,[128,128], ranges)#계산된 hist는 이차원 형태(x,y)
print('hist',hist)
#화면으로 보기위해서 로그 그레이스케일로 변환하는 코드
#log 왜 사용한걸까: 히스토그램에서 가장 큰 값을 가지는 것들은 다른 것에 비해 너무 큰 값이 나오면
#정규화 한 후에는 큰 거 몇개의 픽셀만 돋보이고 나머지는 0에 가까운 검정색이 된다
#즉, 비율을 맞춰주기 위해서
#hist값이 0이 나올수 있으므로 +1을 해줌으로써 최소값이 0이 되게끔 설정한다
hist_norm= cv2.normalize(cv2.log(hist+1), None,0,255,cv2.NORM_MINMAX,cv2.CV_8U)
# 입력 영상에 히스토그램 역투영 적용
src = cv2.imread('kids2.png', cv2.IMREAD_COLOR) #역투영 할 이미지
if src is None:
print('Image load failed!')
sys.exit()
src_ycrcb = cv2.cvtColor(src, cv2.COLOR_BGR2YCrCb)
#역투영
#backproj는 그레이스케일이기 때문에 타입변경없이 바로 imshow하면된다
backproj= cv2.calcBackProject([src_ycrcb], channels, hist, ranges,1)
cv2.imshow('src', src)
cv2.imshow('hist_norm', hist_norm) #단지 히스토그램을 보기위해서 hist_norm을 구함
cv2.imshow('backproj', backproj)
cv2.waitKey()
cv2.destroyAllWindows()
크로마키 합성
### 크로마 키 합성
import sys
import numpy as np
import cv2
# 녹색 배경 동영상
cap1 = cv2.VideoCapture('woman.mp4')
if not cap1.isOpened():
print('video open failed!')
sys.exit()
# 비오는 배경 동영상
cap2 = cv2.VideoCapture('raining.mp4')
if not cap2.isOpened():
print('video open failed!')
sys.exit()
# 두 동영상의 크기, FPS는 같다고 가정
w = round(cap1.get(cv2.CAP_PROP_FRAME_WIDTH))
h = round(cap1.get(cv2.CAP_PROP_FRAME_HEIGHT))
frame_cnt1 = round(cap1.get(cv2.CAP_PROP_FRAME_COUNT))
frame_cnt2 = round(cap2.get(cv2.CAP_PROP_FRAME_COUNT))
print('w x h: {} x {}'.format(w,h))
print('frame_cnt1:', frame_cnt1)
print('frame_cnt2:', frame_cnt2)
fps = cap1.get(cv2.CAP_PROP_FPS)
delay = int(1000 / fps)
#출력 동영상 객체 생성
# fourcc= cv2.VideoWriter_fourcee(*'DIVX')
# out = cv2.VideoWriter('output.avi', fourcc, fps, (w,h))
# 합성 여부 플래그
#경우에 따라 원본을 보여줄지, 합성한 영상을 보여줄지를 결정하는 변수
#True이면 합성영상 on
do_composit = False
# 전체 동영상 재생
while True:
ret1, frame1 = cap1.read() #woman 영상
if not ret1: #맨 마지막 까지가게 되면 불러올 프레임이 없기 때문에
break #break가 걸린다. ret1=False, frame1=None 값이 저장된다
# do_composit 플래그가 True일 때에만 합성
if do_composit:
ret2, frame2 = cap2.read()
if not ret2:
break
#만일사이즈가 다를경우 resize를 해준다
# frame2= cv2.resize(frame2, (w,h)) #w,h는 cap1의 크기
# HSV 색 공간에서 녹색 영역을 검출하여 합성
hsv = cv2.cvtColor(frame1, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv, (50, 150, 0), (70, 255, 255))
#두번째 영상에서 마스크가 흰색으로 되어 있는 부분만 frame1쪽으로 복사한다
cv2.copyTo(frame2, mask, frame1)
# out.write(frame1) #저장
cv2.imshow('frame', frame1)
key = cv2.waitKey(delay) #41ms를 기다리고 다음영상을 받아온다
# 스페이스바를 누르면 do_composit 플래그를 변경
if key == ord(' '):
do_composit = not do_composit
elif key == 27:
break
cap1.release()
cap2.release()
# out.release()
cv2.destroyAllWindows()