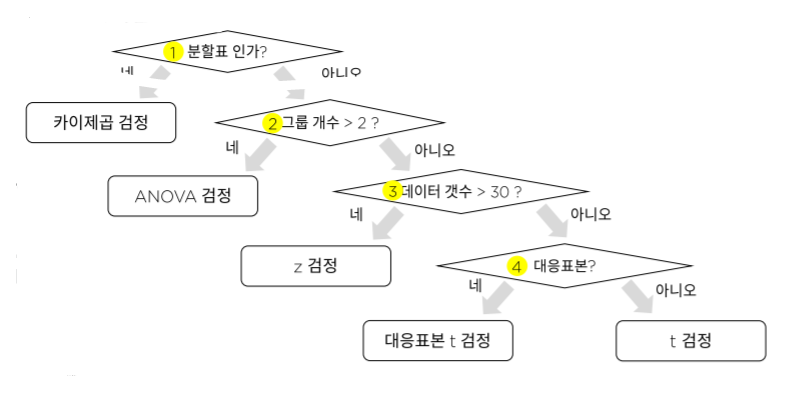
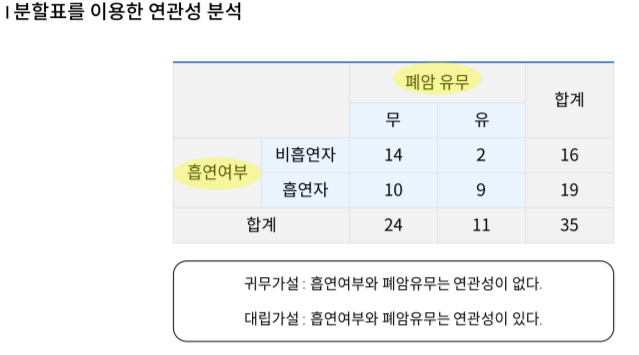
빨간색 부분이 오늘 진행한 내용입니다.
태양열 프로젝트
1차 시도. 랜덤 포레스트 log 상태에서 스케일링에 따른 변화
-> 변화 없음
2차 시도. log 아닌 상태에서 스케일링에 따른 변화
->Normalizer
3차 시도. 변수의 차분 변화에 따른 성능 측정
->변수 2개 이상 동시 사용 시 성능 저하 발생
4차 시도. extracted_features 활용
-> 모든 변수 사용시 성능 저하 발생하여 VIF 및 RFECV 실행
extracted_features 함수를 통해 얻은 변수들 중 의미 있어 보이는 120여 개 피처들로 예측한 그래프입니다.
성능값이 23점을 기록했습니다;;

120여개의 피처들을 vif를 통해 추리고, 추린 값을 refecv를 통해 또 추려봤습니다. 120개의 피처를 refecv를 돌리면 에러가 발생해서 vif 통해 1차적으로 걸렀습니다. 그래서 vif을 통해 얻은 피처 VS vif+refecv을 통해 얻은 피처들을 각각 랜덤 포레스트에 돌렸고 결과는 아래와 같습니다. 기존 변수 활용 시 성능은 7.801이었습니다.
* VIF : 7.98 (성능다운)
* refecv: 7.98(성능다운)
ㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎ
5차 시도. 랜덤 포레스트 그리드 서치
-> 랜덤포레스트 그리드 서치를 실행했습니다.
{'criterion': 'mse',
'max_depth': None,
'max_features': 'auto',
'min_samples_leaf': 2,
'min_samples_split': 8,
'n_estimators': 300}
앞서 구한 결과를 토대로 적용한 결과
* 7.96 (성능다운)
6차 시도. 계절성 분해 적용
-> target값을 분해한 후 validation data인 2021년 01월 추세&계절 값은 2020년도 01월 값을 사용했습니다.
랜덤 포레스트: 13.98 (추세+계절)
랜덤포레스트: 7.78(계절), 약 0.02 개선
7차 시도. Cloud lag값 제거
-> 7.73으로 성능 개선됨
8차 시도. ['Temperature','WindSpeed','Humidity'] 차분 횟수에 따른 성능변화
-> 차분 6일 때 가장 좋은 성능을 보임
1. diff -> 3 : 7.580
2. diff -> 4 : 7.510
3. diff -> 5 : 7.599
4. diff -> 6 : 7.435
5. diff -> 7 : 7.589 (차분 7회 이상부터 과적합)
6. diff -> 8 : 7.645
7. diff -> 9 : 7.702
8. diff -> 10 : 7.753
9차 시도. 랜덤 포레스트 estimator 변경에 따른 성능변화
300 : 7.369
400: 7.363
500: 7.326
600: 7.314
700: 7.331
800: 7.350
900: 7.340
1000: 7.360
10차 시도. 수정된 피처를 적용한 그리드 재검토
*그리드 결과
'max_depth': None,
'min_samples_leaf': 6,
'min_samples_split': 14,
'n_estimators': 600
-> 정확도 83%, Score : 7.51
기존 7.31 보다 0.2 낮아짐. min_samples_leaf & min_samples_split는 과적합 방지로 사용한다. 기존에 사용하던 값은 디폴트 값을 이용했으므로 과적합에 취약한 모델일 가능성이 있다. 하지만 validation 값은 앞서 언급했듯이 0.2가 낮아진 상태이다. 어떤 파라미터가 옳은지는 사실 잘 모르겠다. 일단 val값을 가장 낮추는 방향으로 진행할 예정이다.
11차 시도. Cloud의 더미 변수화
-> 7.526으로 개선 효과 없음
12차 시도. day 데이터의 lag 적용
day lag값 -> 24,48 인 경우 7.249 성능개선
day lag값 -> 24,48,72 인 경우 7.26 성능감소
day lag값 -> 24,48,72,96 인 경우 7.35 성능감소
'Data Diary' 카테고리의 다른 글
| 2021-06-25(태양열예측28) (0) | 2021.06.26 |
|---|---|
| 2021-06-24(태양열예측27) (0) | 2021.06.24 |
| 2021-06-22(R 데이터 분석_6(랜덤포레스트)& 태양열예측25) (2) | 2021.06.22 |
| 2021-06-21(R 데이터 분석_5(나이브베이즈)& 태양열예측24) (0) | 2021.06.21 |
| 2021-06-17(R 데이터 분석_4(knn,logitstic)) (0) | 2021.06.19 |