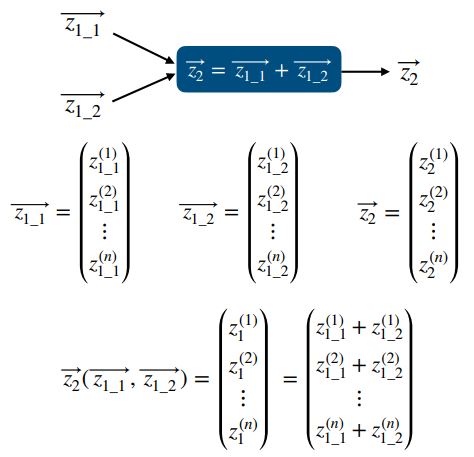
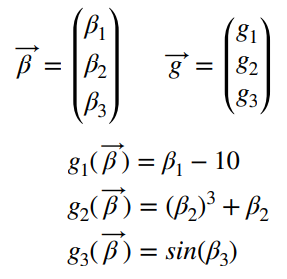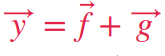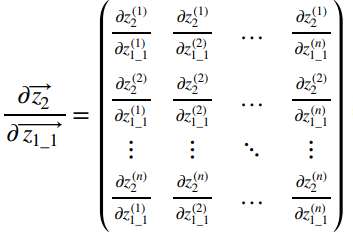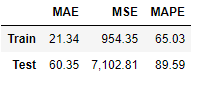시계열 데이터 심화 강의의 마지막 단계인 실습프로젝트들 중 자전거 수요예측 실습을 포스팅하겠습니다.
본 실습은 성능보다는 어떻게 적용할지에 대한 내용만 간략하게 소개되어 있음을 알립니다.
MLP # Data Loading
location = './Data/BikeSharingDemand/Bike_Sharing_Demand_Full.csv'
raw_all = pd.read_csv(location)
#Feature Engineering
raw_fe = feature_engineering(raw_all)
#reality
target = ['coount_trend','count_seasonal','count_Day','count_Week','count_diff']
raw_feR = feature_engineering_year_duplicated(raw_fe, target)
#Data Split
#confirm of input and output
Y_colname=['count']
X_remove=['datetime','DateTime','temp_group','casual','registered']
X_colname = [x for x in raw_fe.columns if x not in Y_colname+X_remove]
X_train_feR, X_test_feR, Y_train_feR, Y_test_feR = datasplit_ts(raw_feR, Y_colname, X_colname,'2017-07-01')
#Reality
target=['count_lag1','count_lag2']
X_test_feR =feature_engineering_lag_modified(Y_test_feR, X_test_feR, target)
#Paramters
scaler_X_tr = preprocessing.MinMaxScaler()
scaler_Y_tr = preprocessing.MinMaxScaler()
batch_size = 32
epoch = 10
verbose = 1
dropout_ratio = 0
# Scaling
X_train = scaler_X_tr.fit_transform(X_train_feR)
Y_train = scaler_Y_tr.fit_transform(Y_train_feR)
X_test = scaler_X_tr.transform(X_test_feR)
Y_test = scaler_Y_tr.fransform(Y_test)
'''
MLP는 시퀀스가 없기때문에 2차원 형식으로 들어가면 된다
'''
# MLP
model = Sequential()
model.add(Dense(128, input_shape=(X_train.shape[1],), activation='relu')
model.add(Dropout(dropout_ratio))
model.add(Dense(256,activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(128, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(64, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(1)
model.compile( optimizer='adam', loss='mean_squard_error')
model.summary()
model_fit=model.fit(X_train, Y_train, batch_size=batch_size, epochs = epoch,
verbose=verbose)
plt.plot(pd.DataFrame(model_fit.history)
plt.grid(True)
plt.show()
#prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predict(X_test)
#evaluation
result = model.evaluate(X_test, Y_Test_pred)
if scaler_T_tr !=[]:
Y_train = scaler_Y_tr.inverse_transform(Y_train)
Y_train_pred = scaler_Y_tr.inverse_transform(Y_train_pred)
Y_test = scaler.Y_tr.inverse_transform(Y_test)
Y_test_pred = scaler_Y_tr.inverse_transform(Y_test_pred)
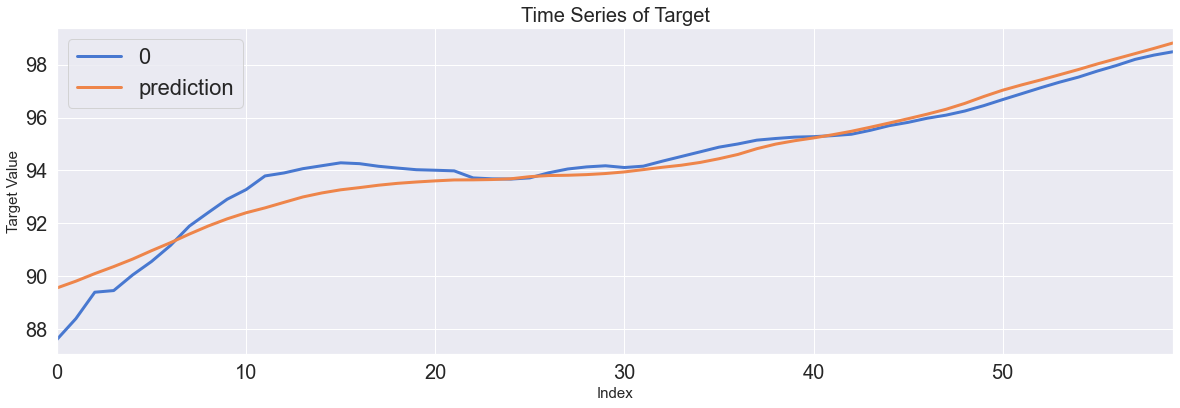
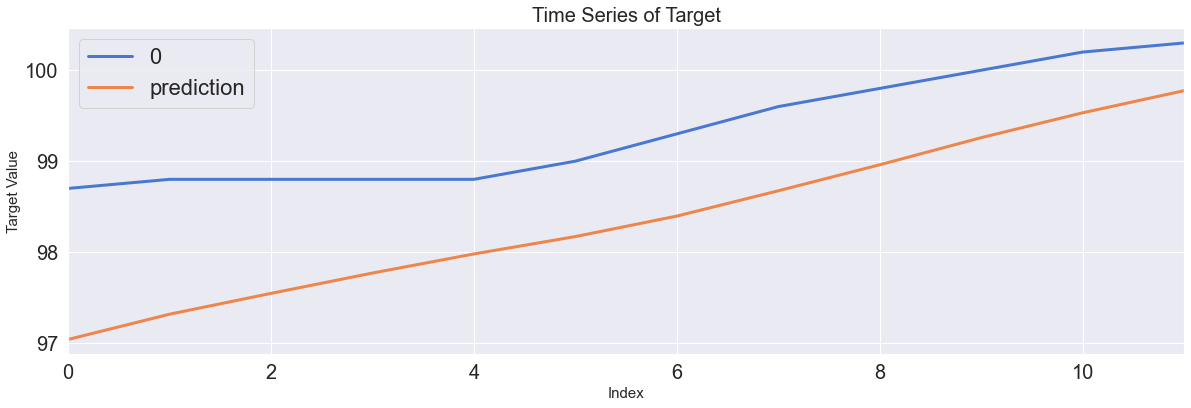
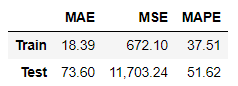
Score_MLP, Residual_tr, Residual_te = evaluation_trte(pd.DataFrame(Y_Train), Y_train_pred.flatten(),
pd.DataFrame(Y_test), Y_test_pred.flatten(),graph_on=True)
display(Score_MLP)
RNN # Data Loading
location = './Data/BikeSharingDemand/Bike_Sharing_Demand_Full.csv'
raw_all = pd.read_csv(location)
# Feature Engineering
raw_fe = feature_engineering(raw_all)
### Reality ###
target = ['count_trend', 'count_seasonal', 'count_Day', 'count_Week', 'count_diff']
raw_feR = feature_engineering_year_duplicated(raw_fe, target)
###############
# Data Split
# Confirm of input and output
Y_colname = ['count']
X_remove = ['datetime', 'DateTime', 'temp_group', 'casual', 'registered']
X_colname = [x for x in raw_fe.columns if x not in Y_colname+X_remove]
X_train_feR, X_test_feR, Y_train_feR, Y_test_feR = datasplit_ts(raw_feR, Y_colname, X_colname, '2012-07-01')
### Reality ###
target = ['count_lag1', 'count_lag2']
X_test_feR = feature_engineering_lag_modified(Y_test_feR, X_test_feR, target)
###############
# Parameters
scaler_X_tr = preprocessing.MinMaxScaler()
scaler_Y_tr = preprocessing.MinMaxScaler()
sequence = 24
batch_size = 32
epoch = 10
verbose = 1
dropout_ratio = 0
# Feature Engineering
## Scaling
X_train_scaled = scaler_X_tr.fit_transform(X_train_feR)
Y_train_scaled = scaler_Y_tr.fit_transform(Y_train_feR)
X_test_scaled = scaler_X_tr.transform(X_test_feR)
Y_test_scaled = scaler_Y_tr.transform(Y_test_feR)
## X / Y Split
X_train, Y_train = [], []
for index in range(len(X_train_scaled) - sequence):
X_train.append(np.array(X_train_scaled[index: index + sequence]))
Y_train.append(np.ravel(Y_train_scaled[index + sequence:index + sequence + 1]))
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_test, Y_test = [], []
for index in range(len(X_test_scaled) - sequence):
X_test.append(np.array(X_test_scaled[index: index + sequence]))
Y_test.append(np.ravel(Y_test_scaled[index + sequence:index + sequence + 1]))
X_test, Y_test = np.array(X_test), np.array(Y_test)
## Retype and Reshape
X_train = X_train.reshape(X_train.shape[0], sequence, -1)
X_test = X_test.reshape(X_test.shape[0], sequence, -1)
print('X_train:', X_train.shape, 'Y_train:', Y_train.shape)
print('X_test:', X_test.shape, 'Y_test:', Y_test.shape)
# RNN
model = Sequential()
model.add(SimpleRNN(128, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=True, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(SimpleRNN(256, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(SimpleRNN(128, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(SimpleRNN(64, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(Flatten())
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit = model.fit(X_train, Y_train,
batch_size=batch_size, epochs=epoch,
verbose=verbose)
plt.plot(pd.DataFrame(model_fit.history))
plt.grid(True)
plt.show()
# prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predict(X_test)
# evaluation
result = model.evaluate(X_test, Y_test_pred)
if scaler_Y_tr != []:
Y_train = scaler_Y_tr.inverse_transform(Y_train)
Y_train_pred = scaler_Y_tr.inverse_transform(Y_train_pred)
Y_test = scaler_Y_tr.inverse_transform(Y_test)
Y_test_pred = scaler_Y_tr.inverse_transform(Y_test_pred)
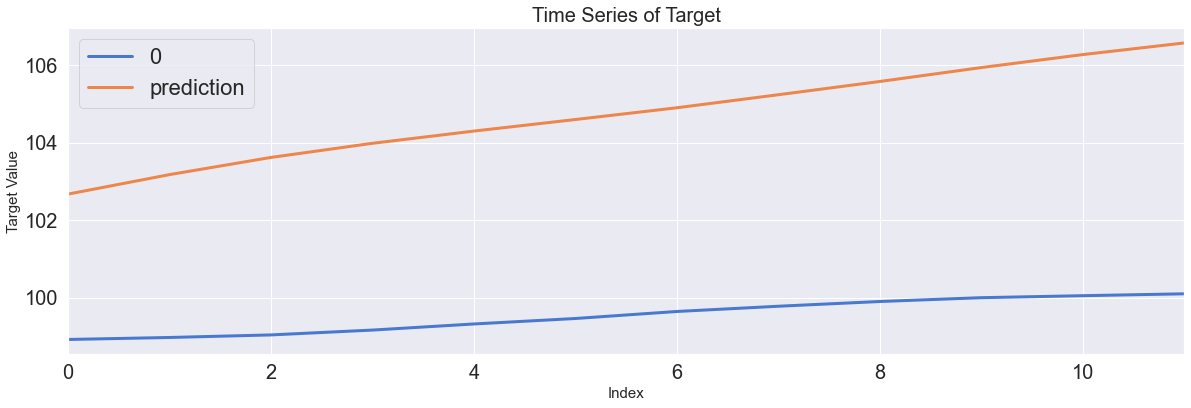
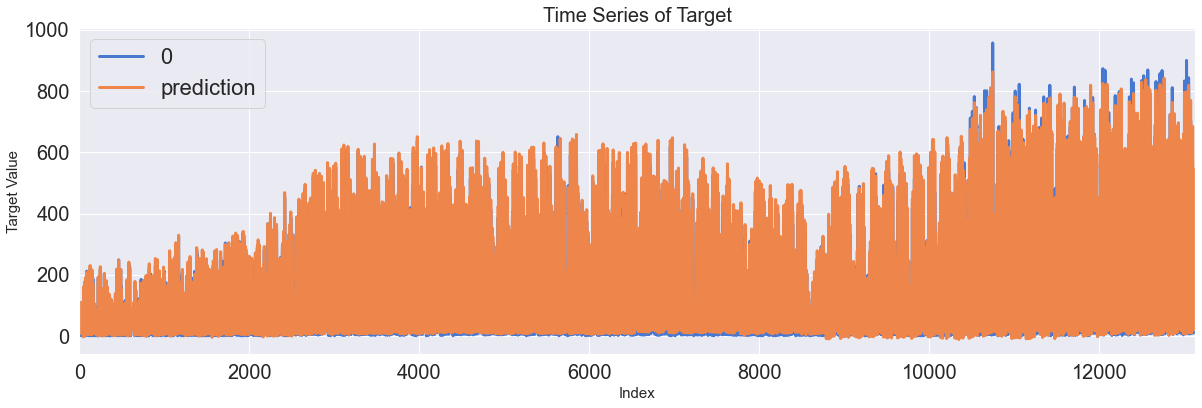
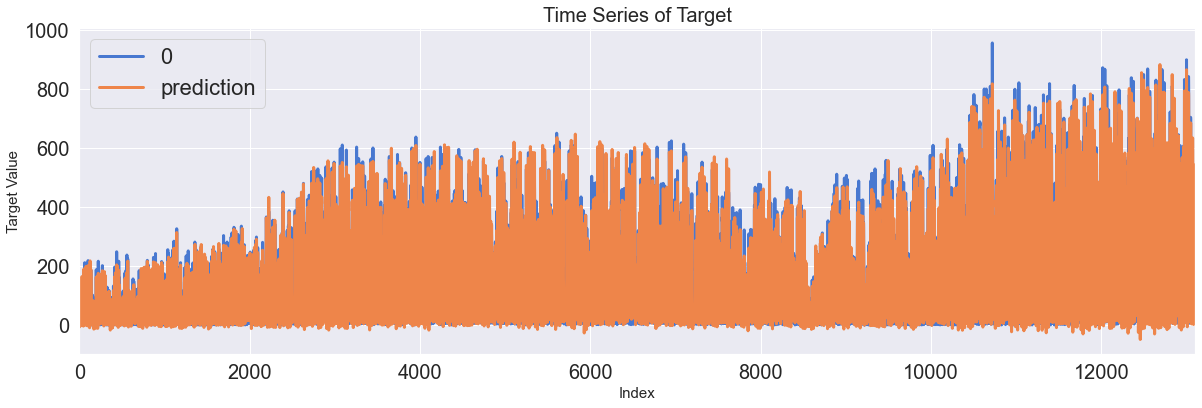
Score_RNN, Residual_tr, Residual_te = evaluation_trte(pd.DataFrame(Y_train), Y_train_pred.flatten(),
pd.DataFrame(Y_test), Y_test_pred.flatten(), graph_on=True)
display(Score_RNN)
Train, Test
LSTM # Data Loading
location = './Data/BikeSharingDemand/Bike_Sharing_Demand_Full.csv'
raw_all = pd.read_csv(location)
# Feature Engineering
raw_fe = feature_engineering(raw_all)
### Reality ###
target = ['count_trend', 'count_seasonal', 'count_Day', 'count_Week', 'count_diff']
raw_feR = feature_engineering_year_duplicated(raw_fe, target)
###############
# Data Split
# Confirm of input and output
Y_colname = ['count']
X_remove = ['datetime', 'DateTime', 'temp_group', 'casual', 'registered']
X_colname = [x for x in raw_fe.columns if x not in Y_colname+X_remove]
X_train_feR, X_test_feR, Y_train_feR, Y_test_feR = datasplit_ts(raw_feR, Y_colname, X_colname, '2012-07-01')
### Reality ###
target = ['count_lag1', 'count_lag2']
X_test_feR = feature_engineering_lag_modified(Y_test_feR, X_test_feR, target)
###############
# Parameters
scaler_X_tr = preprocessing.MinMaxScaler()
scaler_Y_tr = preprocessing.MinMaxScaler()
sequence = 24
batch_size = 32
epoch = 10
verbose = 1
dropout_ratio = 0
# Feature Engineering
## Scaling
X_train_scaled = scaler_X_tr.fit_transform(X_train_feR)
Y_train_scaled = scaler_Y_tr.fit_transform(Y_train_feR)
X_test_scaled = scaler_X_tr.transform(X_test_feR)
Y_test_scaled = scaler_Y_tr.transform(Y_test_feR)
## X / Y Split
X_train, Y_train = [], []
for index in range(len(X_train_scaled) - sequence):
X_train.append(np.array(X_train_scaled[index: index + sequence]))
Y_train.append(np.ravel(Y_train_scaled[index + sequence:index + sequence + 1]))
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_test, Y_test = [], []
for index in range(len(X_test_scaled) - sequence):
X_test.append(np.array(X_test_scaled[index: index + sequence]))
Y_test.append(np.ravel(Y_test_scaled[index + sequence:index + sequence + 1]))
X_test, Y_test = np.array(X_test), np.array(Y_test)
## Retype and Reshape
X_train = X_train.reshape(X_train.shape[0], sequence, -1)
X_test = X_test.reshape(X_test.shape[0], sequence, -1)
print('X_train:', X_train.shape, 'Y_train:', Y_train.shape)
print('X_test:', X_test.shape, 'Y_test:', Y_test.shape)
# LSTM
model = Sequential()
model.add(LSTM(128, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=True, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(LSTM(256, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(LSTM(128, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(LSTM(64, return_sequences=False, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit = model.fit(X_train, Y_train,
batch_size=batch_size, epochs=epoch,
verbose=verbose)
plt.plot(pd.DataFrame(model_fit.history))
plt.grid(True)
plt.show()
# prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predict(X_test)
# evaluation
result = model.evaluate(X_test, Y_test_pred)
if scaler_Y_tr != []:
Y_train = scaler_Y_tr.inverse_transform(Y_train)
Y_train_pred = scaler_Y_tr.inverse_transform(Y_train_pred)
Y_test = scaler_Y_tr.inverse_transform(Y_test)
Y_test_pred = scaler_Y_tr.inverse_transform(Y_test_pred)
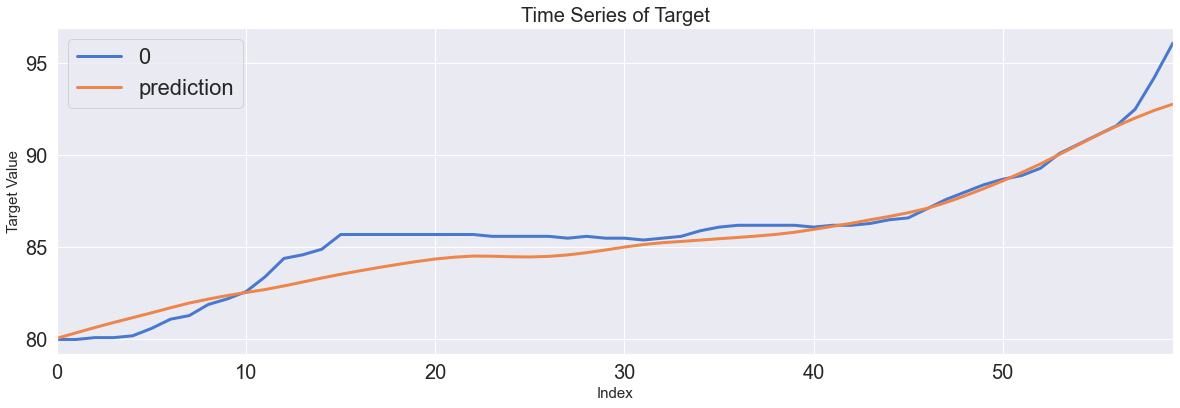
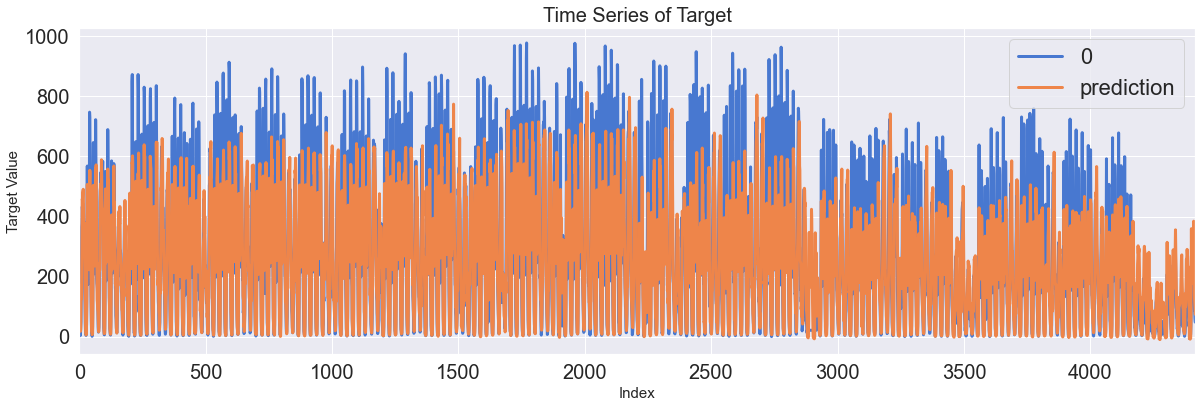
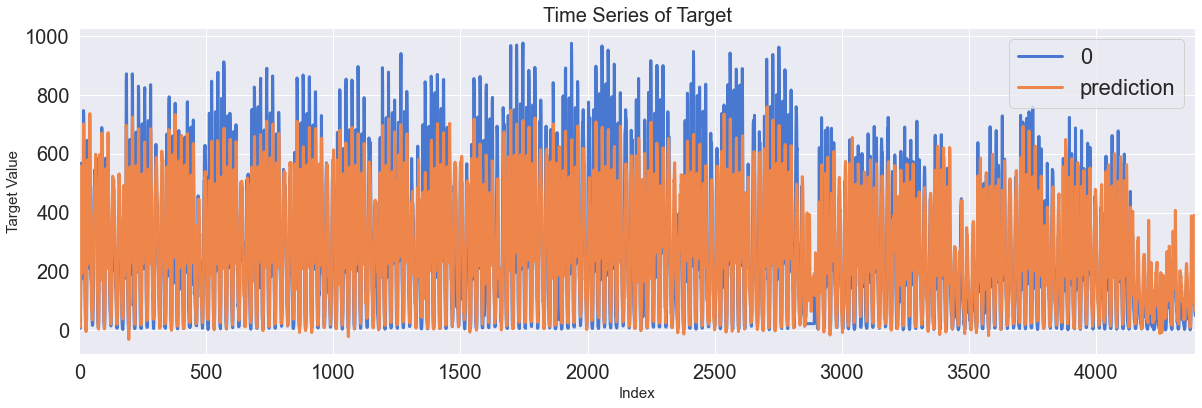
Score_LSTM, Residual_tr, Residual_te = evaluation_trte(pd.DataFrame(Y_train), Y_train_pred.flatten(),
pd.DataFrame(Y_test), Y_test_pred.flatten(), graph_on=True)
display(Score_LSTM)
Train, Test
GRU # Data Loading
location = './Data/BikeSharingDemand/Bike_Sharing_Demand_Full.csv'
raw_all = pd.read_csv(location)
# Feature Engineering
raw_fe = feature_engineering(raw_all)
### Reality ###
target = ['count_trend', 'count_seasonal', 'count_Day', 'count_Week', 'count_diff']
raw_feR = feature_engineering_year_duplicated(raw_fe, target)
###############
# Data Split
# Confirm of input and output
Y_colname = ['count']
X_remove = ['datetime', 'DateTime', 'temp_group', 'casual', 'registered']
X_colname = [x for x in raw_fe.columns if x not in Y_colname+X_remove]
X_train_feR, X_test_feR, Y_train_feR, Y_test_feR = datasplit_ts(raw_feR, Y_colname, X_colname, '2012-07-01')
### Reality ###
target = ['count_lag1', 'count_lag2']
X_test_feR = feature_engineering_lag_modified(Y_test_feR, X_test_feR, target)
###############
# Parameters
scaler_X_tr = preprocessing.MinMaxScaler()
scaler_Y_tr = preprocessing.MinMaxScaler()
sequence = 24
batch_size = 32
epoch = 10
verbose = 1
dropout_ratio = 0
# Feature Engineering
## Scaling
X_train_scaled = scaler_X_tr.fit_transform(X_train_feR)
Y_train_scaled = scaler_Y_tr.fit_transform(Y_train_feR)
X_test_scaled = scaler_X_tr.transform(X_test_feR)
Y_test_scaled = scaler_Y_tr.transform(Y_test_feR)
## X / Y Split
X_train, Y_train = [], []
for index in range(len(X_train_scaled) - sequence):
X_train.append(np.array(X_train_scaled[index: index + sequence]))
Y_train.append(np.ravel(Y_train_scaled[index + sequence:index + sequence + 1]))
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_test, Y_test = [], []
for index in range(len(X_test_scaled) - sequence):
X_test.append(np.array(X_test_scaled[index: index + sequence]))
Y_test.append(np.ravel(Y_test_scaled[index + sequence:index + sequence + 1]))
X_test, Y_test = np.array(X_test), np.array(Y_test)
## Retype and Reshape
X_train = X_train.reshape(X_train.shape[0], sequence, -1)
X_test = X_test.reshape(X_test.shape[0], sequence, -1)
print('X_train:', X_train.shape, 'Y_train:', Y_train.shape)
print('X_test:', X_test.shape, 'Y_test:', Y_test.shape)
# GRU
model = Sequential()
model.add(GRU(128, input_shape =(X_train.shape[1], X_train.shape[2]), activation='relu',return_sequences=True))
model.add(Dropout(dropout_ratio))
model.add(GRU(256, return_sequneces=True, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(GRU(128, return_sequences=True, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(GRU(64, return_sequences=False, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(1, activation='relu')
model.complie( optimizer ='adam', loss='mean_squared_error'))
model.summary()
model_fit = model.fit(X_train, Y_train,batch_size= batch_sizem
epochs=epoch, verbose=verbose)
plt.plot(pd.DataFrame(model_fit.history)
plt.grid(True)
plt.show()
#prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predict(X_test)
#evaluation
result = model.evaluation(X_test, Y_test_pred)
if scaler_Y_tr != []:
Y_train = scaler_Y_tr.inverse_transform(Y_train)
Y_train_pred = scaler_Y_tr.inverse_transform(Y_train_pred)
Y_test = scaler_Y_tr.inverse_transform(Y_test)
Y_test_pred = scaler_Y_tr.inverse_transform(Y_test_pred)
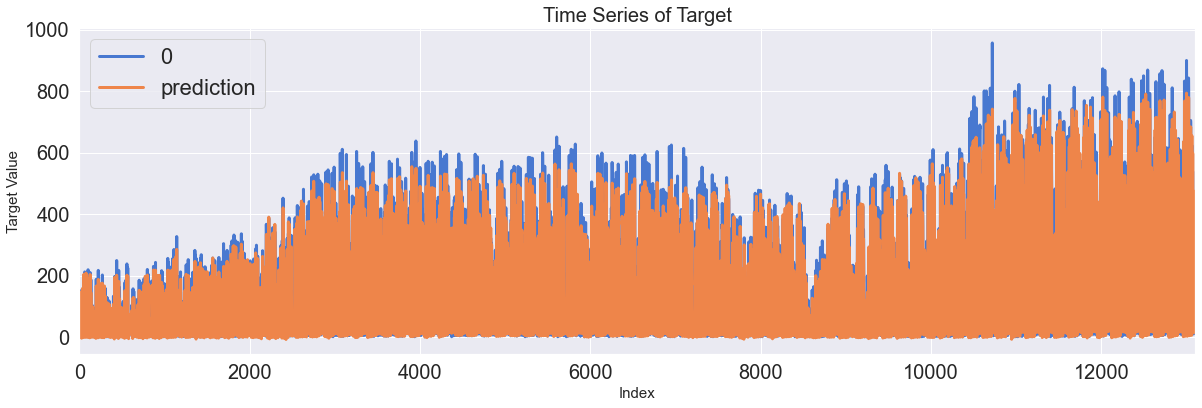
Score_GRU, Residual_tr, Residual_te = evaluation_trte(pd.DataFrame(Y_train), Y_train_pred.flatten(),
pd.DataFrame(Y_test), Y_test_pred.flatten(), graph_on=True)
display(Score_GRU)
Train, Test